从0了解深度学习——注意力机制与外部记忆
本文章将介绍深度学习中的注意力机制与外部记忆
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
引言
增加网络能力,除了改进模型结构/复杂度,还可以引入注意力机制和外部记忆
案例一:使用 RNN 进行阅读理解(Facebook bAbi tasks 数据集)
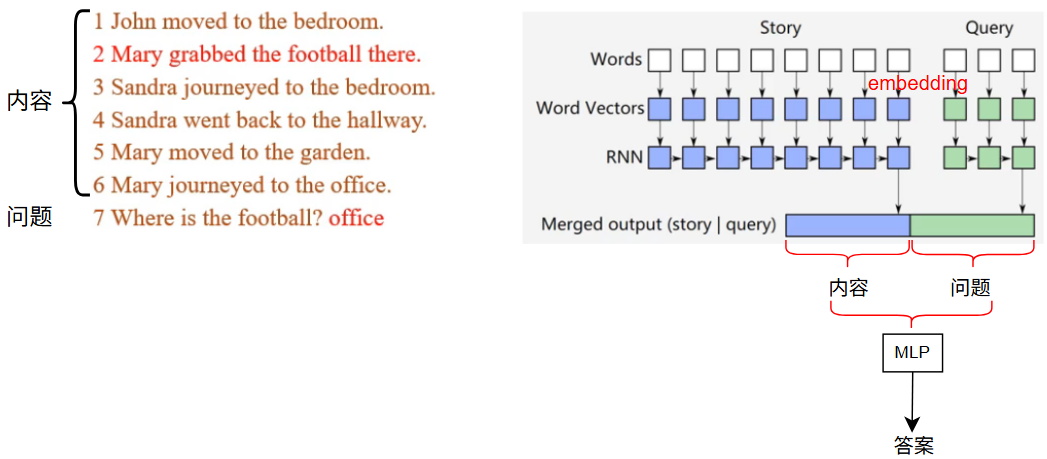
缺点:
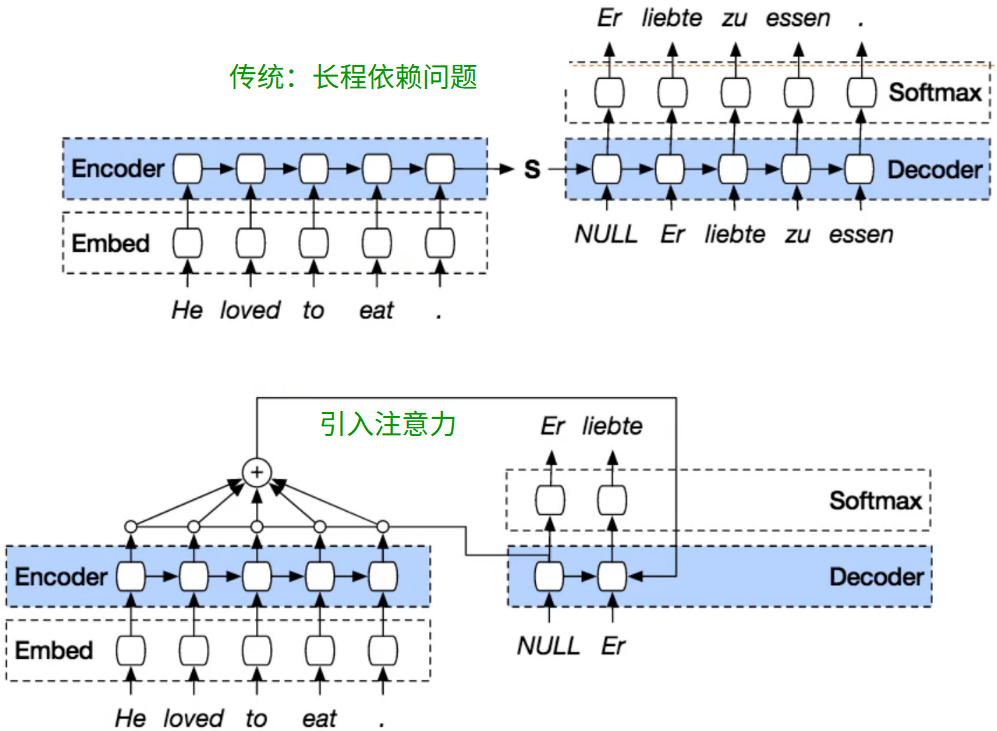
- RNN 长程依赖问题:序列很长时,会忽略前期信息
- 句子 1,3,4 与问题无关,是否考虑省略
- 向量表示信息有限,当文本越长,所储存的信息越多,很难用低维向量表示所有内容,若增加维度,则会导致参数膨胀
案例二:阅读理解(SQuAD 数据集)
让机器和人一样思考:先读问题,带着问题找答案,只找与问题相关的上下文,节约资源

注意力机制
人脑每个时刻接收的外界输入信息很多,包括来源于视觉、听觉、触觉的各种各样的信息
- 单就视觉而言,眼睛每秒钟会发送千万比特的信息给视觉神经系统
如何解决信息超载问题——注意力
例如:看报纸时,会首先关注图片,大字等信息
两种注意力:
- 自上而下:自发的,不受外界干扰地被动接受(汇聚,pooling)
- 自下而上:外界干扰的,有目的地主动注意(会聚,focus)
鸡尾酒会效应: 以更高的权重关注应该关注的,但会有更少的权重关注其他信息(环境/噪声)
在酒会上,尽管周围噪声不断,但仍能与朋友进行谈话而忽略其他人的声音
但如果环境中有重要的词,比如有人叫自己名字,仍能马上注意到
人工神经网络中的注意力机制
原理
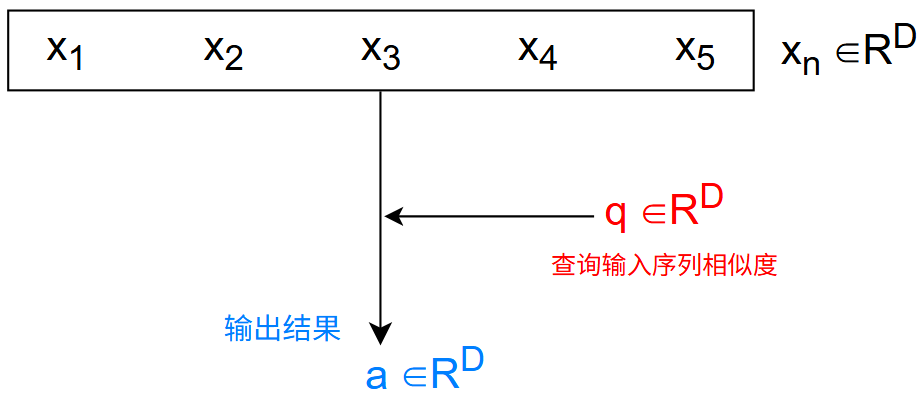
不同注意力的输出 \(a\) 不同:
- 硬注意力:仅输出最相关的信息
- 软注意力:对各个输入进行打分,生成对应权重后加权汇总
软注意力机制
软注意力机制分为两步:
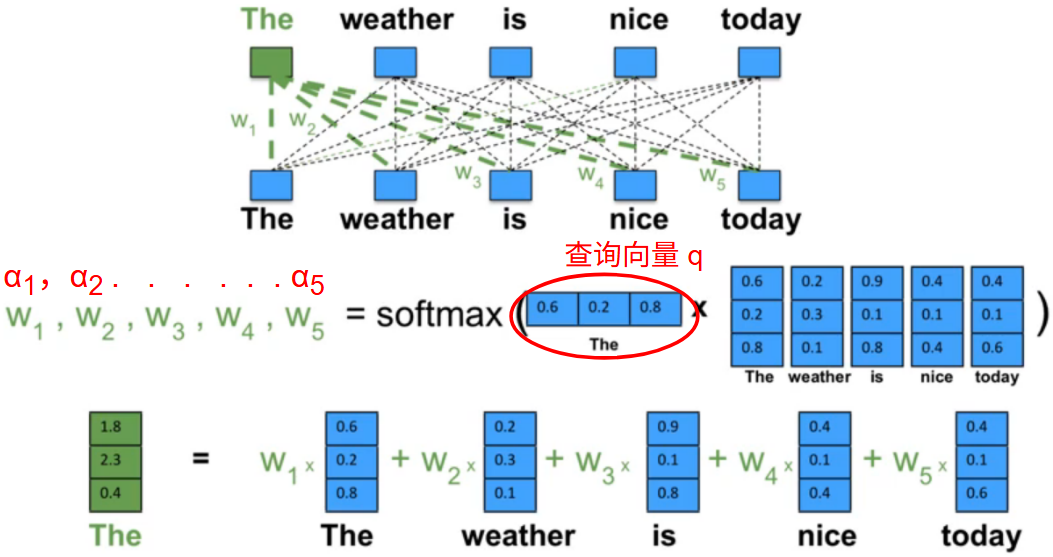
- 计算注意力分布 \(\alpha\) :用任务向量 \(q\) 对各个输入打分,将得分过 Softmax 函数
\[ \begin{gather} \alpha_n=p(z=n|X,q) \\ =softmax(s(x_n,q)) \\ =\frac{e^{s(x_j,q)}}{\sum^N_{j=1}e^{s(x_j,q)}} \end{gather} \]
\(p(z=n|X,q)\) 表示第 \(n\) 个输入与任务最相关的概率
\(s(x_n,q)\) 为打分函数
\(\sum\alpha_n=1\)
- 根据 \(\alpha\) 来计算输入信息的加权平均(期望):用各自的 \(\alpha\) 乘以对应输入 \(x\)
\[ \begin{gather} att(X,q)=\sum_{n=1}^N\alpha_nx_n \\ =\mathbb{E}_{z\sim p(z|X,q)}[x]. \end{gather} \]
上述公式为软注意力机制,是连续函数,方便求导
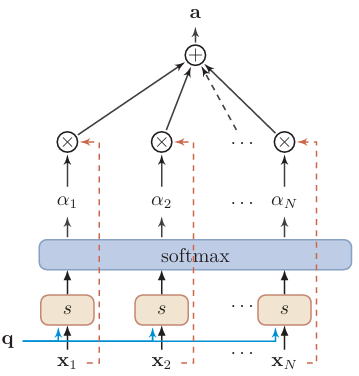
注意力打分函数
对于打分函数 \(s(x_n,q)\) 有以下几类:
- 加性模型:
\[ s(x_n,q)=v^Ttanh(Wx_n+Uq) \]
- 点积模型:
\[ s(x_n,q)=x_n^Tq \]
若值过大,经过 Softmax 后,大的值会趋近于1,小的值会趋近于0
- 缩放点积模型(常用)
\[ s(x_n,q)=\frac{x_n^Tq}{\sqrt{D}} \]
其中的 \(D\) 为输入维度
当维度过大时,点积模型的结果很大,导致梯度爆炸/消失,将其除以维度的平方根,能规范化点积结果
- 双线性模型(带方向,允许 \(x\) 与 \(q\) 维度不同)
\[ \begin{gather} s(x_n,q)=x_n^TWq \\ \Downarrow \\ s(x_n,q)=(W'x_n)^T(W'q)=x_n^T·W'^TW·q=x_n^TWq \end{gather} \]
对于 2. 和 3. 的点积模型,交换其 \(x\) 和 \(q\) 的位置,结果不变
我们有时希望 \(q\) 或 \(x\) 作查询或被查询时,相似度不同
注意力机制变体
硬注意力机制: 没有梯度,离散,常与强化学习结合在一起
键值对注意力: 用 \((K,V)=[(k_1,v_1),...,(k_N,v_N)]\) 表示
\(N\) 个输入信息 \[
\begin{gather}
att((K,V),q)=\sum_{n=1}^N\frac{e^{s(k_n,q)}}{\sum_je^{s(k_j,q)}}·v_n \\
\alpha_n=\frac{e^{s(k_n,q)}}{\sum_je^{s(k_j,q)}} \\
=\sum_{n=1}^N\alpha_nv_n
\end{gather}
\] 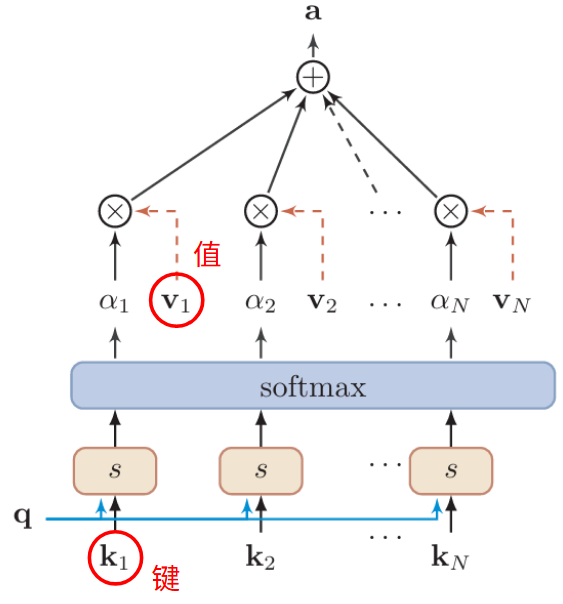
在之前的注意力机制中, \(K\) 和 \(V\) 都是用 \(X\) 代替,将 \(X\) 分为 \(K,\,V\) 将使得模型更加灵活,可以对 \(K,\,V\) 使用不同的计算策略
实际上 \(K,\,V\) 可能都是由 \(X\) 转变而来:
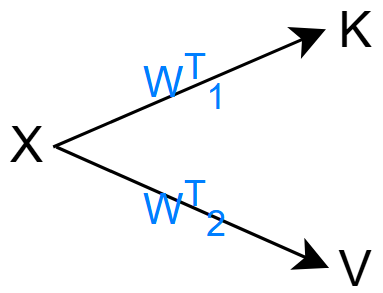
在一些任务中, \(K,\,V\) 的来源也可能不同,要依据情况
多头注意力: 利用多个查询 \(Q=[q_1,...,q_m]\) ,同时从输入信息中并行选取多组信息,每个“注意力头”关注输入信息的不同部分 \[ att((K,V),Q)=att((k,v),q_1)\oplus,..., \oplus att((k,v),q_m) \]
其他还有结构化注意力,感兴趣可以自己去了解,这里不做赘述
注意力机制应用
文本分类
以往的文本分类使用 RNN 进行,但一个模型只能进行一种分类,每更换一种分类就要重新训练,且对于 RNN 来说压力很大
可以使用 RNN 来做基础的文本句子表示,让注意力机制做分类:
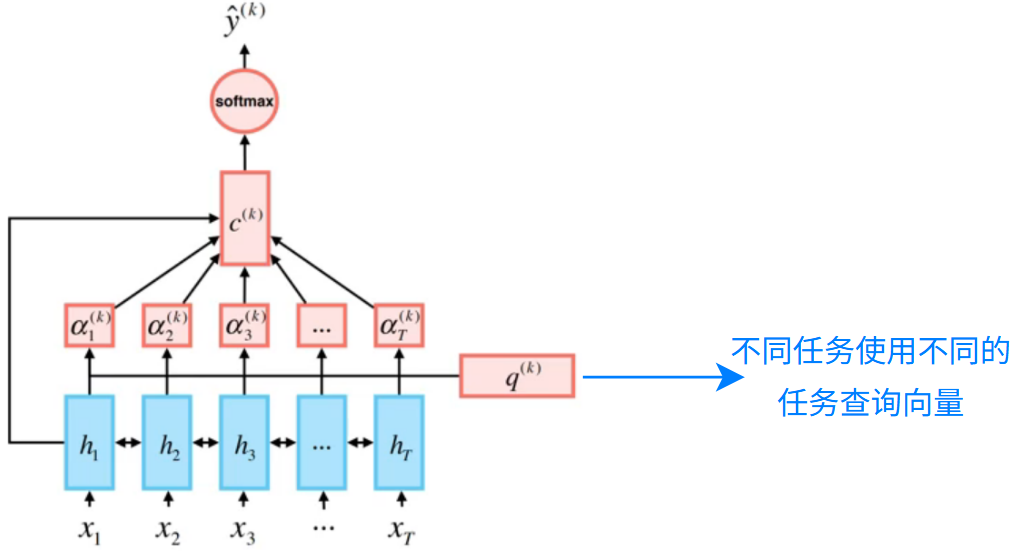
此时,RNN 只负责建立句子的通用表示,分担了 RNN 的压力
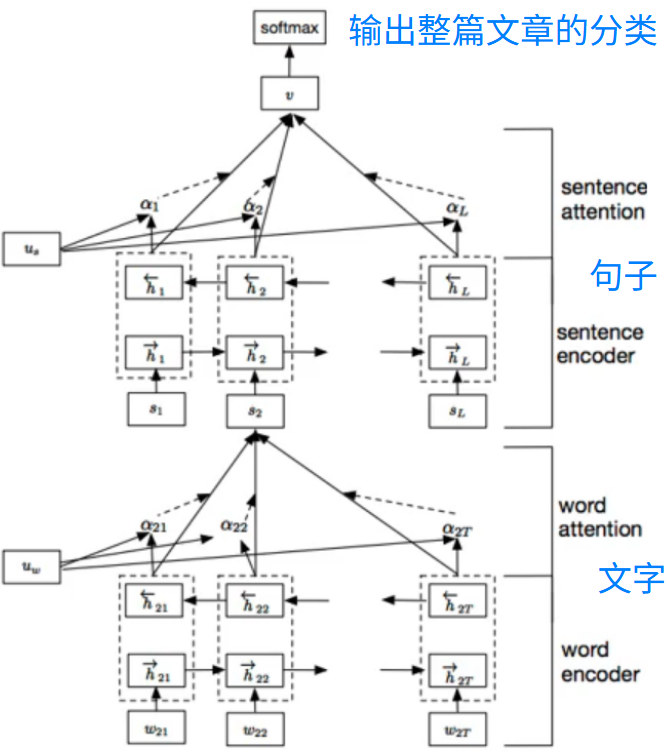
层次注意力模型
机器翻译
看图说话
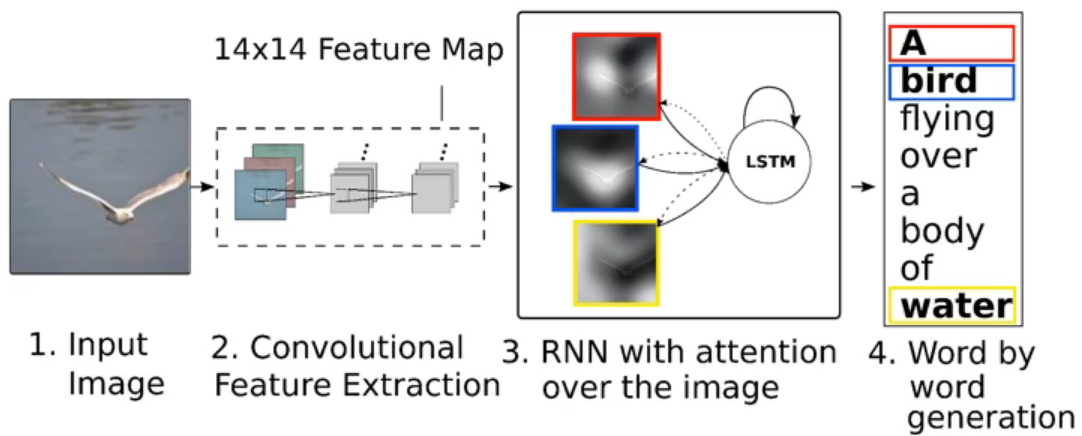
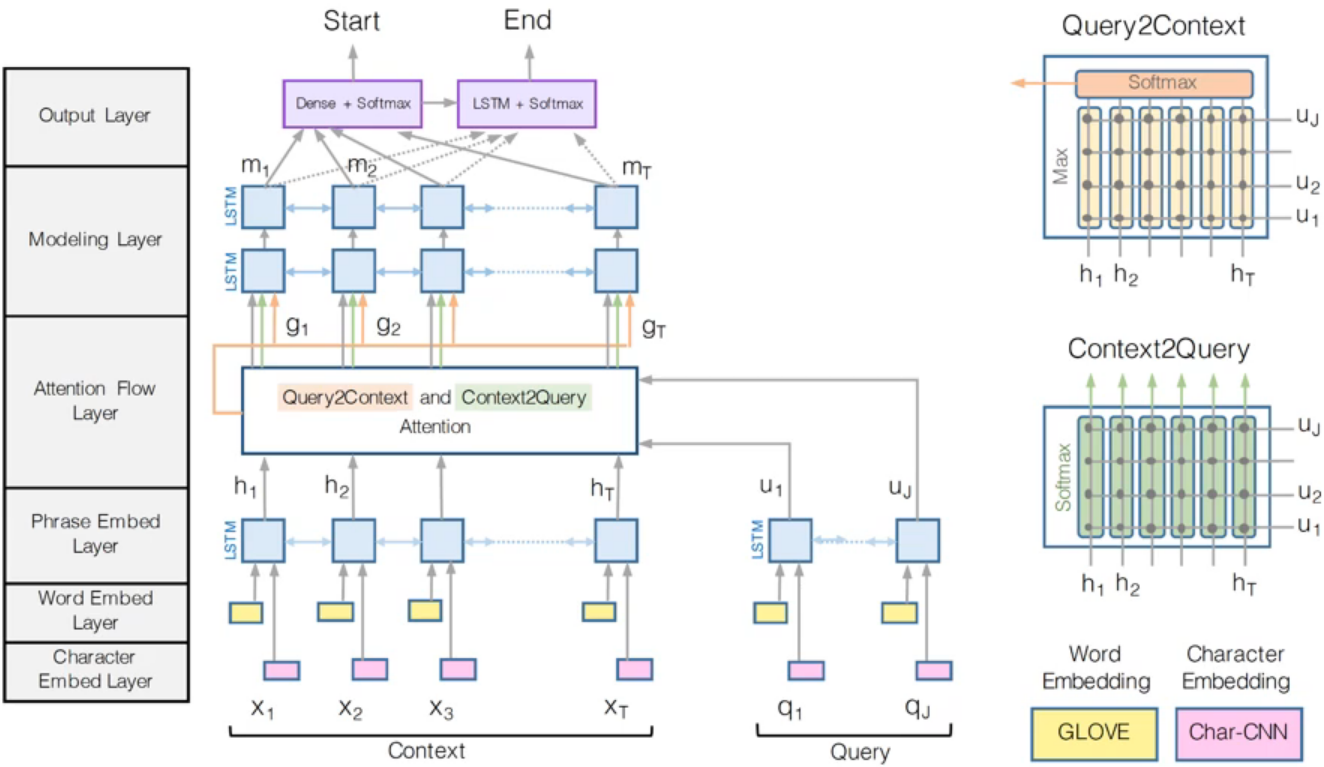
阅读理解
复杂模型:bi-att-flow
自注意力机制
变长序列的建模:
当使用神经网络来处理一个变长的向量序列时,我们通常可以用卷积网络或循环网络进行编码,来得到相同长度的输出向量序列
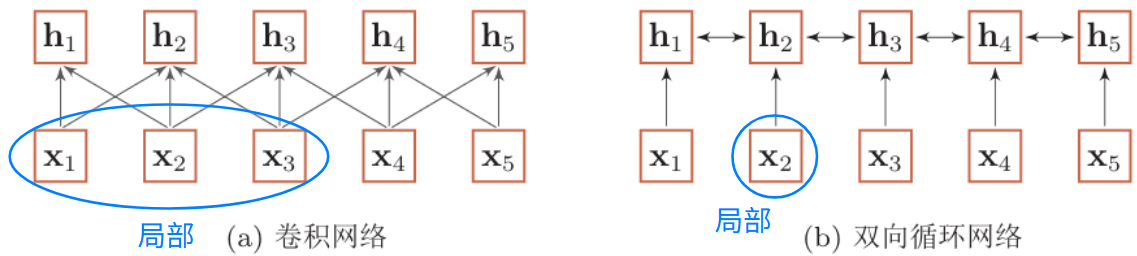
但是他们都只建模了输入信息的局部依赖关系
自注意力模型
那么如何建立非局部的依赖关系:全连接
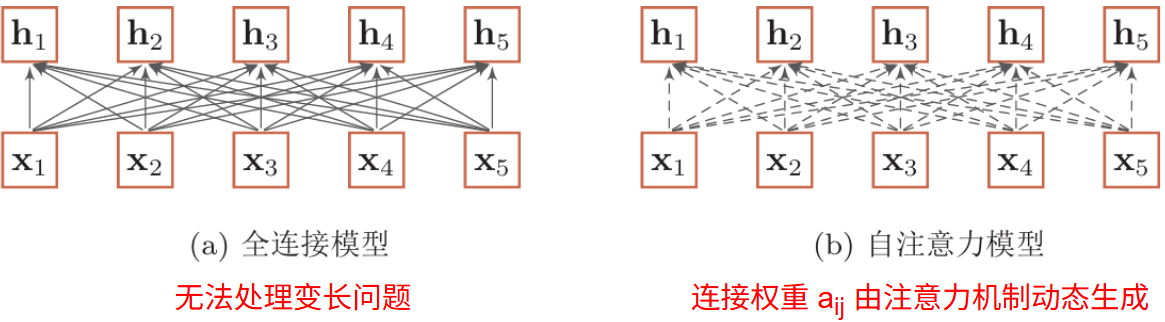
全连接模型的权重只与位置相关,与其他内容无关:
对于文本数据而言,若交换 \(x_1\) 与 \(x_2\) 的位置,其句意会改变,但权重不会改变,导致不擅长建模序列数据的语义组合关系
自注意力模型的权重矩阵只与输入的数据个数 \(n\) 有关,权重矩阵大小为:\(n\times n\)
因此无论输入数量多少,都能动态调整权重矩阵
自注意力模型:
没有外部输入的查询向量 \(Q\)
,输入的每个词都是各自的查询向量 \(q\)
,故称为 自注意力模型
自注意力模型的矩阵表示
给一个 \(D_x\) 维的数量 \(N=3\) 的输入,那么其上下文表示为:
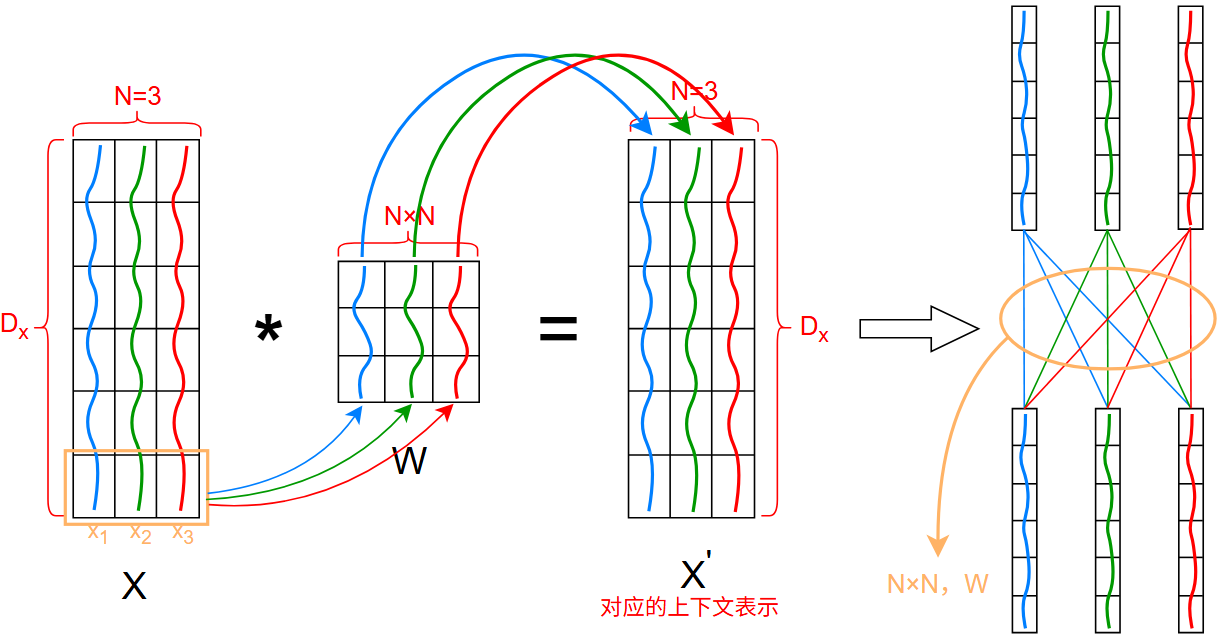
既然 \(W\) 与 \(N\) 有关,那么 \(W\) 是怎么得到的呢?
先说结论: \[ W=Softmax(X^T·X) \] 我们看看 \(X^T·X\) 是什么:
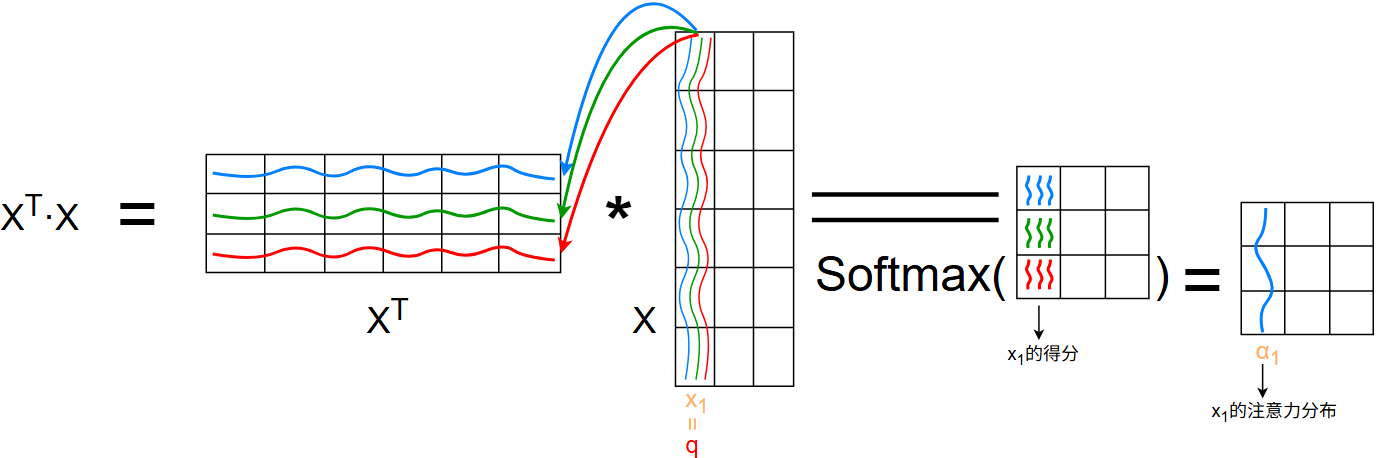
从上图中看,在 \(X\) 中代表 \(x_1\) 的那一列,这不就相当于查询向量 \(Q\) 对 \(X^T\) 的各个 \(x\) 进行查询操作吗?
那么得到的 \(3\times3\) 矩阵的第一列就是 \(x_1\) 对应的分数, \(X^T·X=s(x_n,q)\) 就是打分函数
将打分函数过 Softmax 得到权重矩阵 \(W\)
最后输出为: \[ X'=X·Softmax(X^T·X)\,=\,X·Softmax(s(x_n,q)) \] 其中的打分函数 \(s(x_n,q)\) 还可以进行缩放: \[ s(x_n,q)=X^T·X\;\Rightarrow\; \frac{X^T·X}{\sqrt{D_x}} \]
QKV模式(Query-Key-Value)
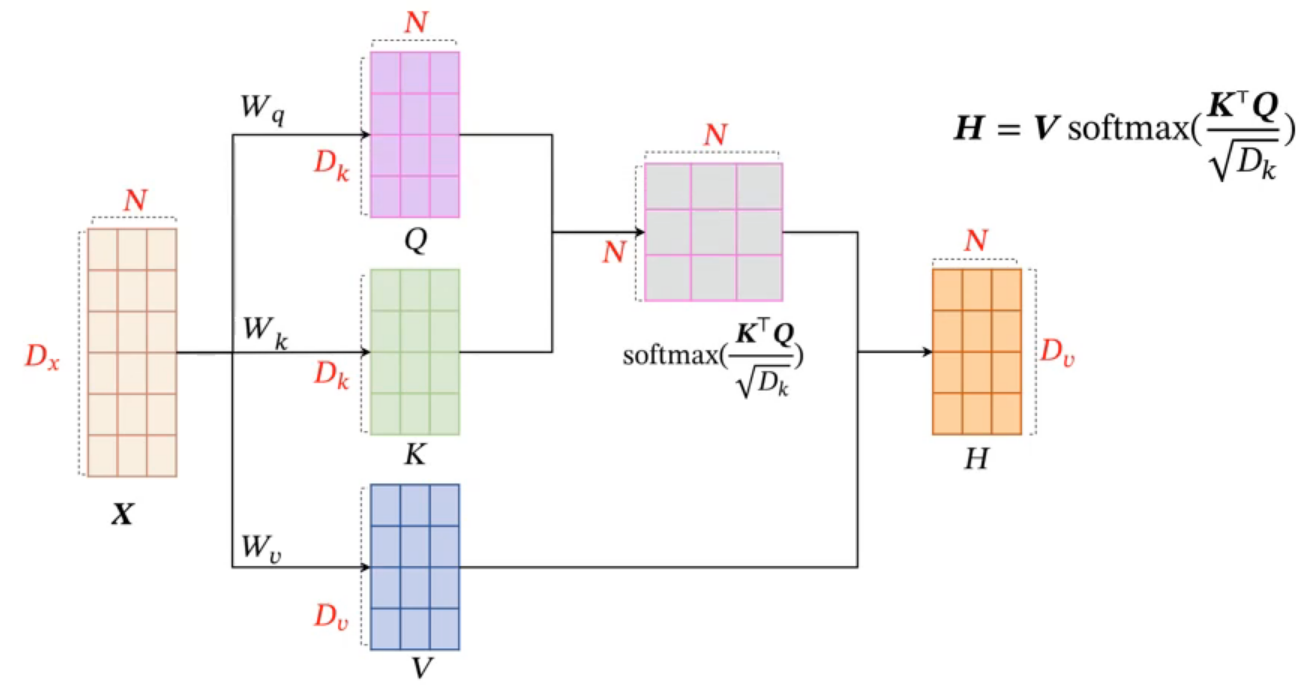
使用不同的 \(W\) 将 \(X\) 分成不同空间上的三个功能(此 \(W\) 非 \(Softmax(X^T·X)\) 的 \(W\) )
输入序列:\(X=[x_1,...,x_N]\,\in\,\mathbb{R}^{D_x\times N}\)
首先生成三个向量序列: \[ \begin{gather} Q=W_q·X\quad\in\,\mathbb{R}^{D_k\times N} \\ K=W_k·X\quad\in\,\mathbb{R}^{D_k\times N} \\ V=W_v·X\quad\in\,\mathbb{R}^{D_v\times N} \end{gather} \] 计算 \(h_n\) \[ \begin{gather} h_n=att((K,V),q_n) \\ =\sum_{j=1}^N\alpha_{nj}v_j \\ =\sum_{j=1}^NSoftmax(s(k_j,q_n))·v_j \end{gather} \] 若用点积缩放作为注意力打分函数,输出向量序列可以简写为: \[ H=V·Softmax(\frac{K^TQ}{\sqrt{D_k}}) \] 多头注意力模型:
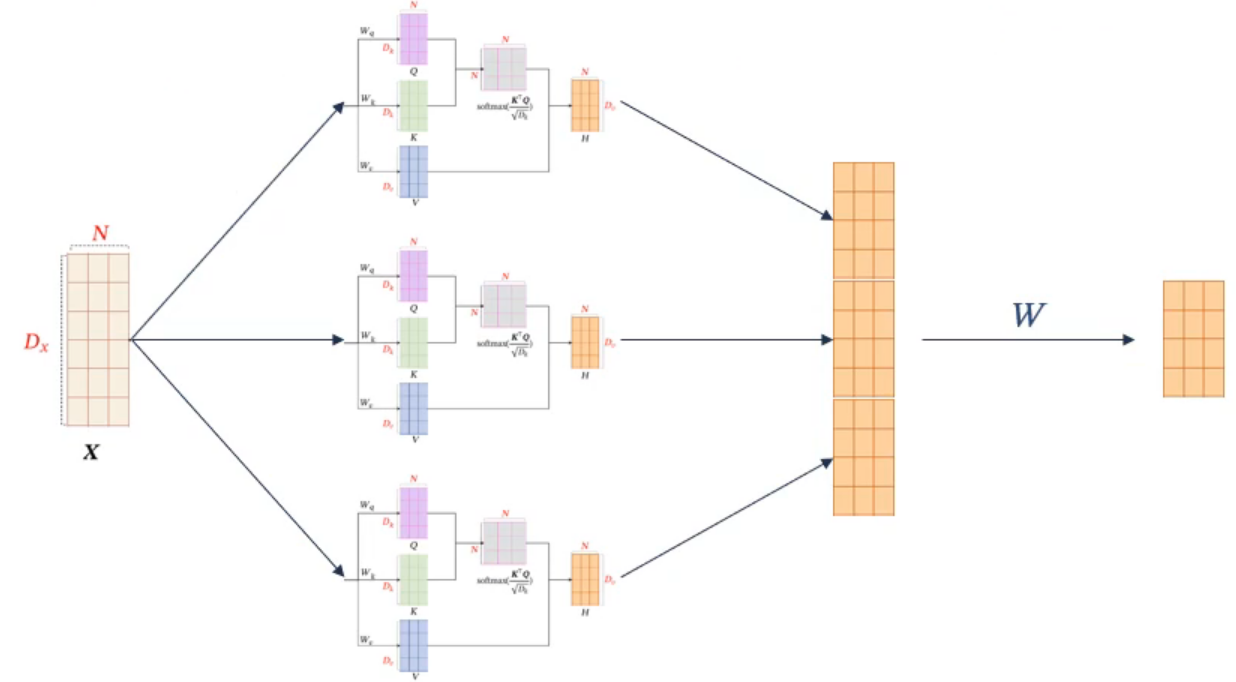
Transformer
Transformer 模型是一种基于注意力机制(Attention Mechanism)的深度学习架构,最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。Transformer 模型在自然语言处理(NLP)和计算机视觉(CV)等领域取得了巨大的成功,成为许多现代模型的基础架构
Transformer分为两部分:
- Encoder:编码源语言
- Decoder:编码目标语言
以机器翻译为例:
源语言:被翻译的语言
目标语言:源语言翻译后的结果
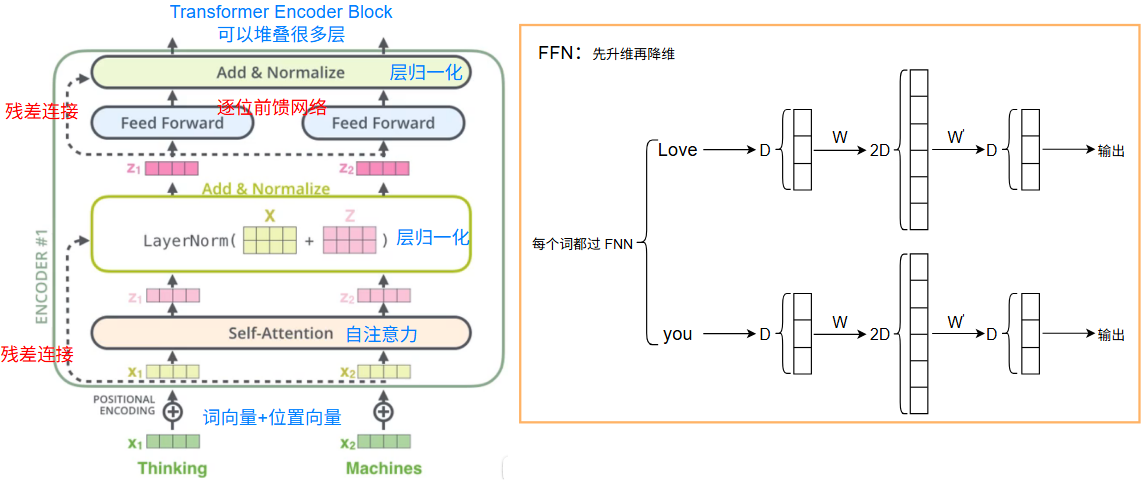
Encoder
Encoder的作用是用来编码源语言
仅仅自注意力还不够,由于自注意力模型的 \(\alpha\) 分布是动态生成的,与位置无关,只与内容有关,不利于序列建模
引入其他操作:
- 位置编码:1、2、3—>位置向量
- 层归一化
- 直连边(残差连接)
- 逐位 FFN :每个词的上下文表示都过 FFN
复杂度分析:
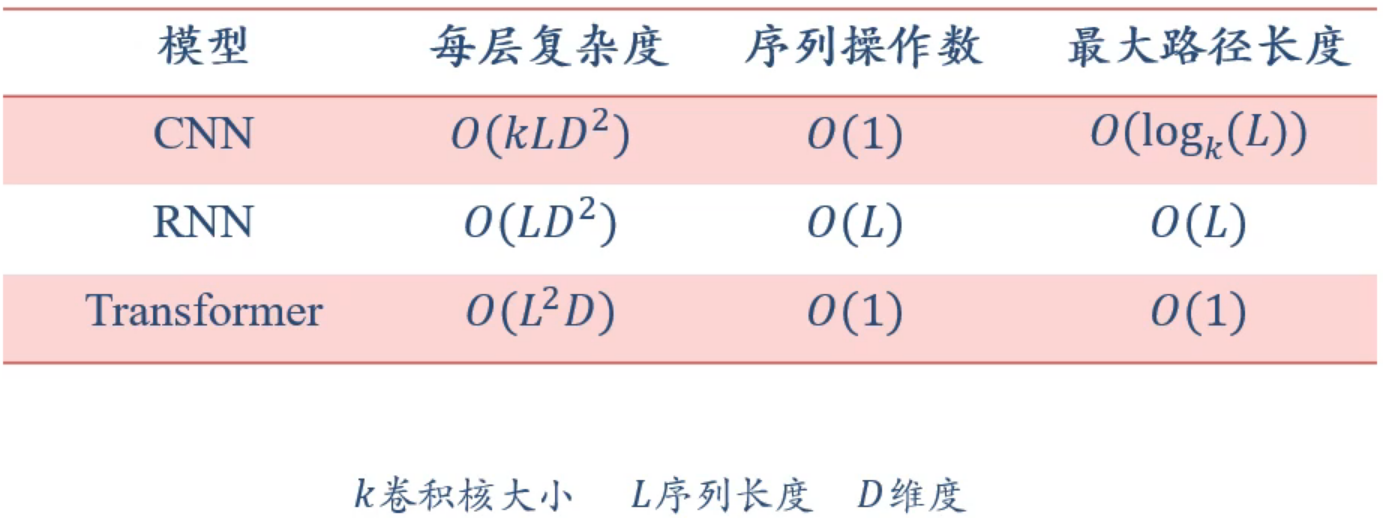
这里展示每层复杂度的计算过程:
CNN:
卷积对 \(L\) 个 \(D\) 维计算:\(K\times D\times L\)
输出 \(D\) 维,一共执行 \(D\) 次操作:\(D\times (K\times D\times L)\)
RNN:
每个时间步:\(h_t=U·h_{t-1}\)
\(U:D\times D\)
\(h_{t-1}:D\times 1\)
\(h_t:D\times D\odot D\times 1\rightarrow D^2\)
一共 \(L\) 个时间步:\(LD^2\)
Transformer:
自注意力模型:$$
\(X^T:L\times D\quad X:D\times L\)
\(X^TX:L\times D\odot D\times L\rightarrow L^2D\)
外部:\(X\odot X^TX:D\times L\odot L\times L\rightarrow L^2D\)
\(X·Softmax(X^TX):L^2D+L^2D=2L^2D\rightarrow O(L^2D)\)
Decoder
Decoder的作用是用来编码目标语言
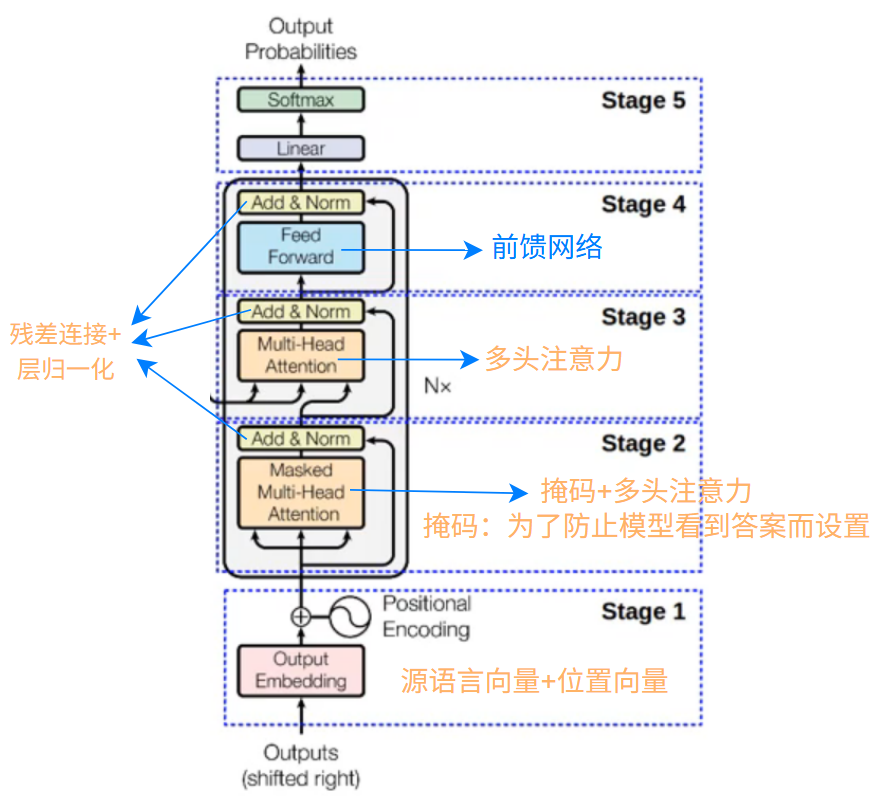
Decoder输入:
- 训练时:输入为目标语言
- 推理时:输入为 Decoder 的输出,即本次输入为上一次的输出
Decoder 模块和 Encoder 模块差不多,多了掩码
掩码:
因为 Decoder 模块在训练时输入的是目标语言,也就是“答案”,而 Decoder 的输出是一个词一个词地输出,所以为了防止训练时,模型看到之后还未输出的词,所以就使用掩码,将未输出的“词”遮起来,防止模型偷看答案
而为什么这里的输入右移了(图中的 Shifted right),之后解释
完整流程
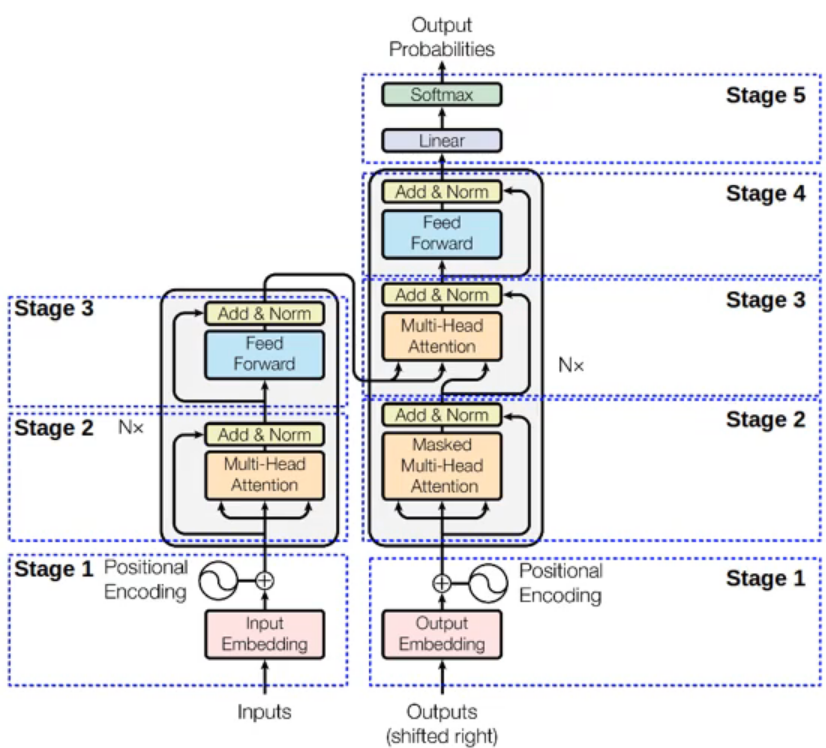
在完整的模型中,输入为两部分:
- 训练时:源语言+目标语言
- 推理时:源语言+ Decoder 的输出
例如: 我们要把 “我爱你” 翻译为 “I love you”:
- Encoder 输入:我爱你
- Decoder 输入:I love you <EOS>
流程如下:
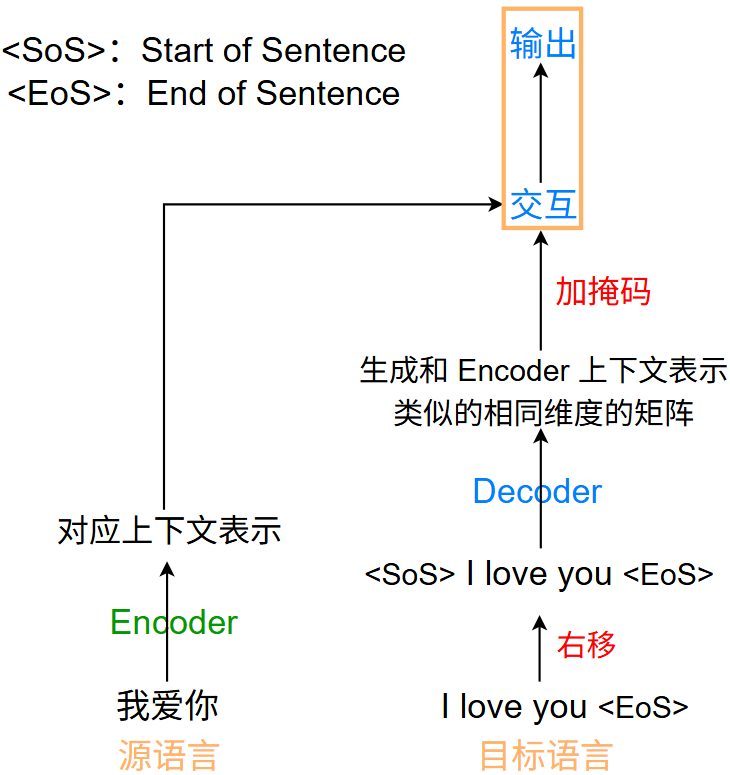
而具体的 交互和输出 流程(图中橙色框的内容)如下:
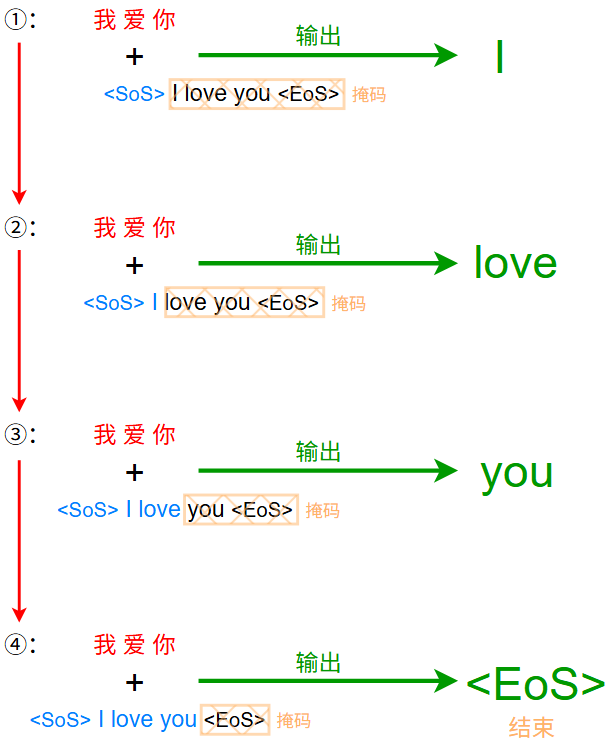
上图中,红色与蓝色的文字都是矩阵形式,只是为了方便表示,写成了文字形式
是否要生成 <EoS> 要看具体任务
在推理时,Decoder 输入仅为 <SoS> ,后续 Decoder 的输入由其输出充当,即生成一个词后,该词与上一次 Decoder 输入拼接后再作为输入
外部记忆
大脑中的记忆:
记忆:外界信息在人脑中的内部表示
记忆过程:
- 工作记忆(短期)
- 情景记忆
- 结构记忆(长期)
特点是联想记忆
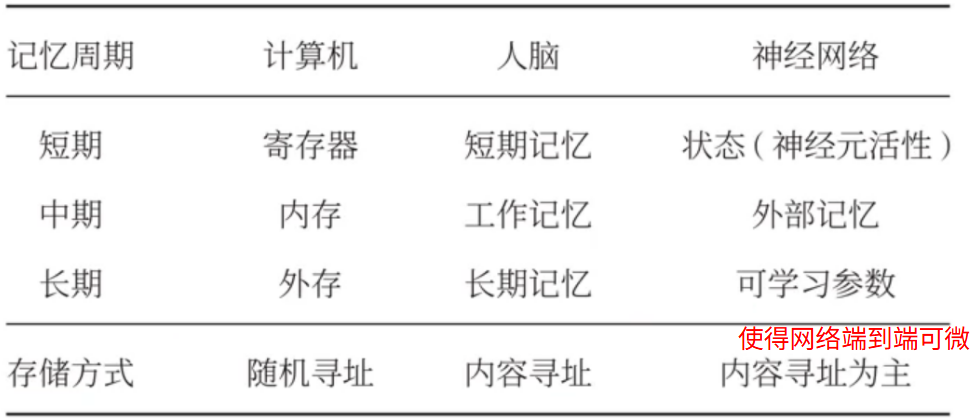
记忆网络
记忆增强神经网络
- 主网络
- 外部记忆
- 读写操作
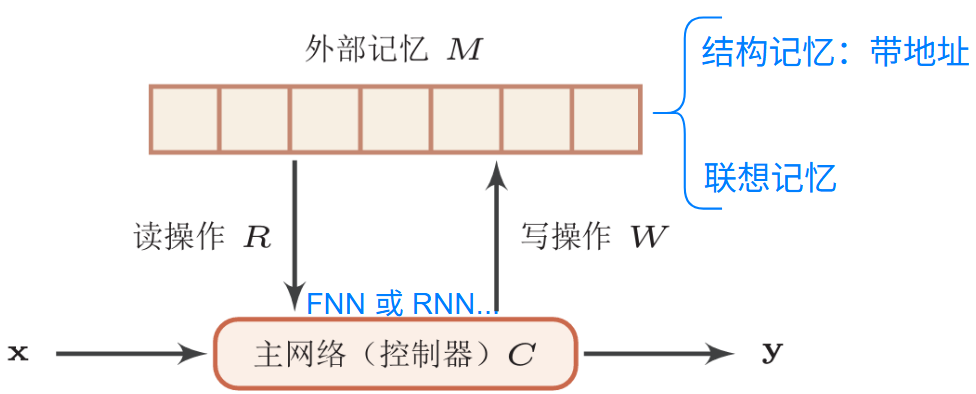
结构化外部记忆
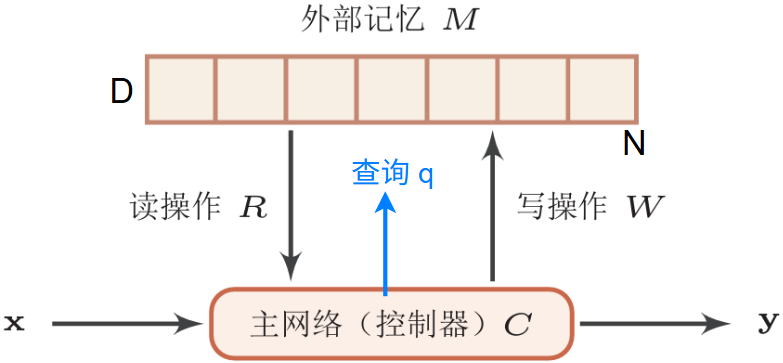
外部记忆定义为矩阵 \(M\in\mathbb{R}^{D\times N}\)
\(D\) 为每个记忆片段的大小,\(N\) 为记忆片段的数量
如何读写?注意力机制,且使用软注意力机制(可微)
端到端记忆网络
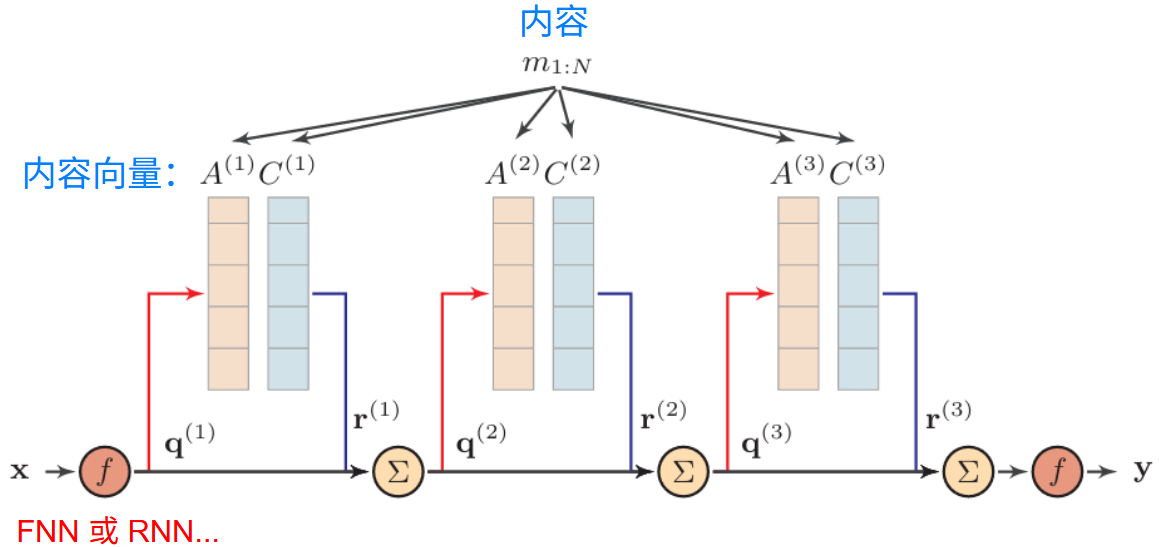
内容向量既可以为原始的 embedding ,也可以经过 RNN 进行生成
输入 \(x\) 产生查询向量 \(q\) : \[ f(x)\rightarrow q^{(1)} \] 查询后输出: \[ r^{(1)}=C^{(1)}·Softmax(A^{(1)}·q^{(1)}) \] 输出 \(q^{(2)}\) \[ q^{(1)}+r^{(1)}=q^{(2)} \] 这种被称为多跳机制(multi-hop)
神经图灵机(NTM)
图灵机:一种抽象数学模型,可以用来模拟任何可计算问题
组件:
- 控制器
- 外部记忆
- 读写操作
整个架构可微分
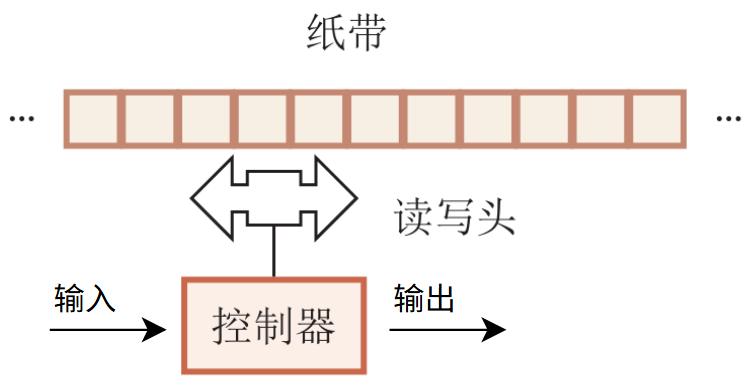
示例:
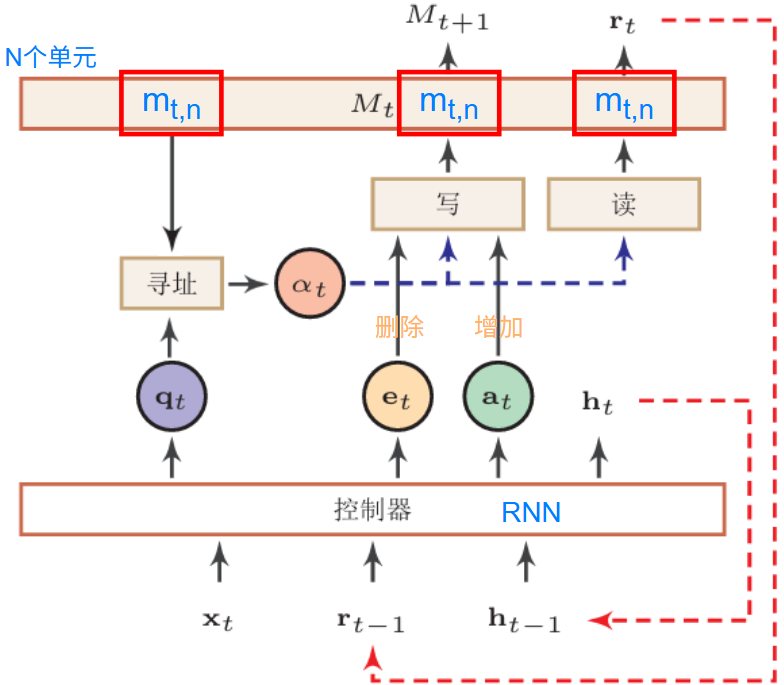
图中,从左到右为:
注意力分布 \(\alpha_t\) : \[ \alpha_t=Softmax(s(m_{t,n},q_t)) \] 写操作: \[ m_{t+1,n}=m_{t,n}(1-\alpha_{t,n}·e_t)+\alpha_{t,n}·a_t \] 读操作: \[ r_t=\sum_{n=1}^N\alpha_t·m_{t,n} \] 最后的输入输出操作: \[ \begin{gather} q_t,h_t \\ e_t,a_t \end{gather} =f(x_t,h_{t-1},r_{t-1}) \]
基于神经动力学的联想记忆
外部记忆类型:
- 只读
- 记忆网络
- RNN 中的 \(h_t\)
- 扩展到注意力机制,使用 \(q\) 去查询也可以看作一种外部记忆
- 可读写
- 神经图灵机NTM:难以训练一个模型,依赖外部记忆初始化
联想记忆
- 自联想:\(x\rightarrow x\)
- 看到一个残缺的钥匙—>完整的钥匙
- 异联想:\(x\rightarrow y\)
- 看到一个残缺的钥匙—>一把锁
- 双向异联想:\(x\Leftrightarrow y\)
赫布法则:
当神经元A的一个轴突和神经元B很近,足以对它产生影响,并且持续地,重复地参与了对神经元B的兴奋,那么在这两个神经元或其中之一会发生某种生长过程或新陈代谢变化,以至于神经元A作为能使神经元B兴奋的细胞之一,它的效能加强了
Hopfield网络
一种记忆的存储和检索模型
Hopfield网络(Hopfield Network)是一种循环神经网络模型,由一组相互连接的神经元组成。Hopfield网络也可以认为是所有神经元都相互连接的不分层的神经网络。每个神经元既是输入单元,又是输出单元,没有隐藏神经元。一 个神经元和自身没有反馈相连,不同神经元之间连接权重是对称的
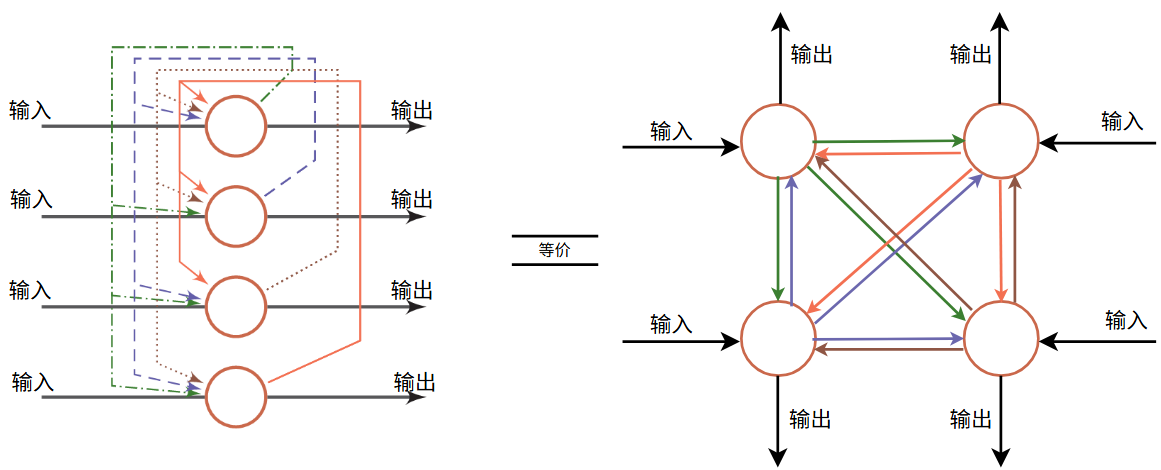
连接权重有以下性质: \[ \begin{gather} w_{ij}=w_{ji}\quad \forall i,j\in[1,m] \\ w_{ii}=0\quad\forall i\in[1,m] \end{gather} \] 若一个 Hopfield 网络有 \(m\) 个神经元,第 \(i\) 个神经元的更新规则为: \[ s_i= \begin{cases} +1\quad if\quad \sum_{j=1}^mw_{ij}s_j+b_i\geq0, \\ -1\quad otherwise \end{cases} \] \(\sum_{j=1}^mw_{ij}s_j+b_i\) 相当于对所有邻居的加权汇总
Hopfield 网络的更新可以分为异步和同步两种方式
异步更新:每次更新一个神经元,神经元的更新顺序可以是随机或事先固定的
同步更新:指一次更新所有的神经元,需要有一个时钟来进行同步
第 \(t\) 时刻的神经元状态为 \(s_t= [s_{t,1}, s_{t,2}, · · · , s_{t,m}]^T\) ,其更新规则为: \[ s_t=f(Ws_{t-1}+b)\qquad (s_0=x) \]
能量函数
在 Hopfield 网络中,我们给每个不同的网络状态定义一个标量属性,称为“能量” \[ \begin{gather} E=-\frac{1}{2}\sum_{i,j}w_{ij}s_is_j-\sum_ib_is_i \\ =-\frac{1}{2}s^TWs-b^Ts \end{gather} \] Hopfield 网络是稳定的,即能量函数经过多次迭代后会达到收敛状态
权重对称是一个重要特征,因为它保证了能量函数在神经元激活时单调递减,而不对称的权重可能导致周期性震荡或者混乱,也就是: \[ \begin{gather} s_t\rightarrow s_{t+1} \\ E_t\geq E_{t+1} \end{gather} \] 检索过程(联想记忆)
给定一个外部输入,网络经过演化,会达到某个稳定状态
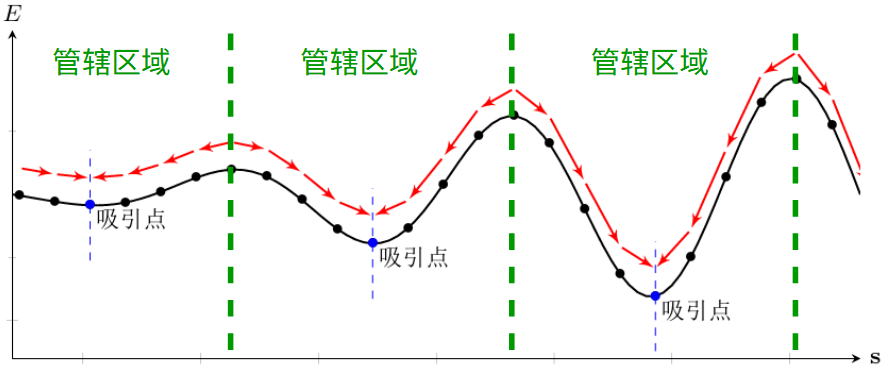
每个吸引点 \(u\) 都对应一个 “管辖区域” ,若输入向量 \(x\) 落入这个区域,网络都会收敛到 \(u\)
每个吸引点 \(u\) 都可以看作是网络中存储的信息
存储过程
信息存储是指将一组向量 \(x^{(1)},...,x^{(N)}\) 存储在网络中的过程,存储过程主要是调整神经元之间的连接权重
神经元 \(i\) 和 \(j\) 之间的连接权重: \[ w_{ij}=\frac{1}{N}\sum^N_{n=1}x_i^{(n)}x_j^{(n)} \] 其中 \(x^{(n)}_i\) 是第 \(n\) 个输入向量的第 \(i\) 维特征。如果 \(x_i\) 和 \(x_j\) 在输入向量中相同的概率越多,则 \(w_{ij}\) 越大。这种学习规则和人脑神经网络的学习方式十分类似。在人脑神经网络中,如果两个神经元经常同时激活,则它们之间的连接加强;如果经常不同时激活,则连接消失。这种学习方式称为赫布(Hebbian)法则
容量:每1000个节点可以存储138组向量,可以利用联想记忆来增加网络容量
与结构化外部记忆相比,联想记忆具有更好的生物解释性
从0了解深度学习——注意力机制与外部记忆