从0了解深度学习——网络优化与正则化
本文章将介绍深度学习中的网络优化与正则化
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
网络优化
有效地学习深层神经网络的参数是一个具有挑战性的问题
网络优化的难点:
- 结构差异大
- 没有通用的优化算法
- 超参数多
- 梯度消失/爆炸问题
- 非凸优化问题
- 参数初始化
- 逃离局部最优(低维)或鞍点(高维)
高维空间中的非凸优化问题
鞍点
某些维度上是全局最小,在一些维度上是全局最大
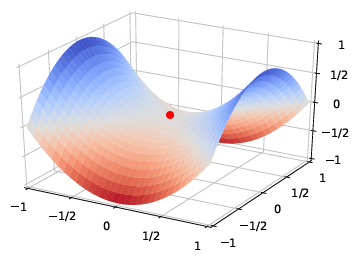
驻点:梯度为0的点
一般,局部最小点与局部最大点的数量相近
则在 \(D\) 维空间中,1个点在所有维度都是最小点的概率为:\((\frac{1}{2})^D\)
当 \(D\) 很大时,概率很小,所以说,在空间中的驻点,基本上全是鞍点
所以要逃离鞍点
平坦最小值
- 一个平坦最小值的邻域内,所有点对应的训练损失都比较接近
- 大部分的局部最小解是等价的(能让训练损失相同的点,可能分布在空间中的不同位置)
- 局部最小解对应的训练损失都可能非常接近与全局最小解对应的训练损失(可能找到一个局部最小解就够了)
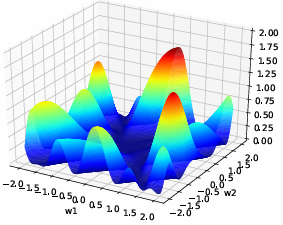
优化地形可视化
优化地形:再高维空间中损失函数的曲面形状
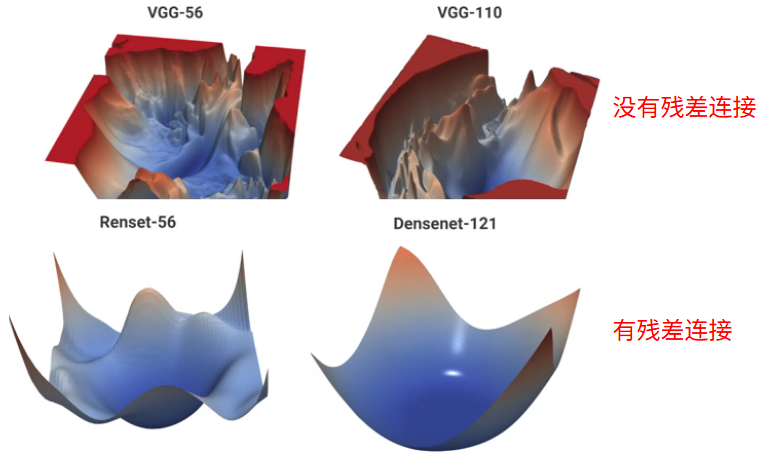
残差连接好处:
- 梯度—>+1
- 优化地形—>平滑
神经网络优化的改善方法
- 更有效的优化算法来提高优化方法的效率和稳定性
- 动态学习率调整
- 梯度估计修正
- 更好的参数初始化方法,数据预处理方法来提高优化效率
- 修改网络结构来得到更好的优化地形
- 好的优化地形通常比较平滑
- 使用 ReLu 激活函数、残差连接、逐层归一化等
- 使用更好的超参数优化方法(较难,组合优化问题)
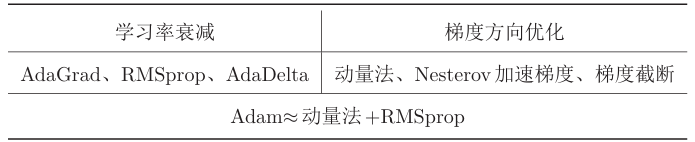
优化算法改进
改进方法
- 标准的(小批量)梯度下降
- 学习率
- 学习率衰减
- AdaGrad
- AdaDelta
- RMSprop
- 梯度
- 动量法:计算负梯度的“加权移动平均”作为参数更新方向
- Nesterov加速梯度
- 梯度截断
小批量随机梯度下降(Mini-Batch)
选取 \(k\) 个训练样本 \(S_t= \{x^{(k)},y^{(k)} \}^k_{k=1}\) ,计算偏导数: \[ \mathcal{G}_t(\theta)=\frac{1}{k}\sum_{(x,y)\in S_t}\frac{\partial L(y,f(x,\theta))}{\partial \theta} \] 定义第 \(t\) 次更新的梯度: \[ g_t\overset{\triangle}{=}\mathcal{G}_t(\theta_{t-1}) \] 使用梯度下降来更新参数: \[ \theta_t\leftarrow\theta_{t-1}-\alpha·g_t \] 关键因素:
- 小批量样本数量 \(k\)
- 梯度
- 学习率
批量大小
批量大小不影响随机梯度的期望,但会影响随机梯度的方差
- 批量越大,随机梯度的方差越小,引入的噪声也越小,训练越稳定,可以设置较大的学习率
- 批量越小,需要设置较小的学习率,否则模型不会收敛
批量大小与学习率的关系
- 当批量为 \(k\) 时,梯度:\(-\alpha\frac{1}{k}·(...)\)
- 当批量为 \(mk\) 时,梯度:\(-\alpha\frac{1}{mk}·(...)\)
线性缩放规则: \(\alpha\) 需要乘 \(m\) 来抵消分母的 \(m\) :\(-m\alpha\frac{1}{mk}·(...)\)
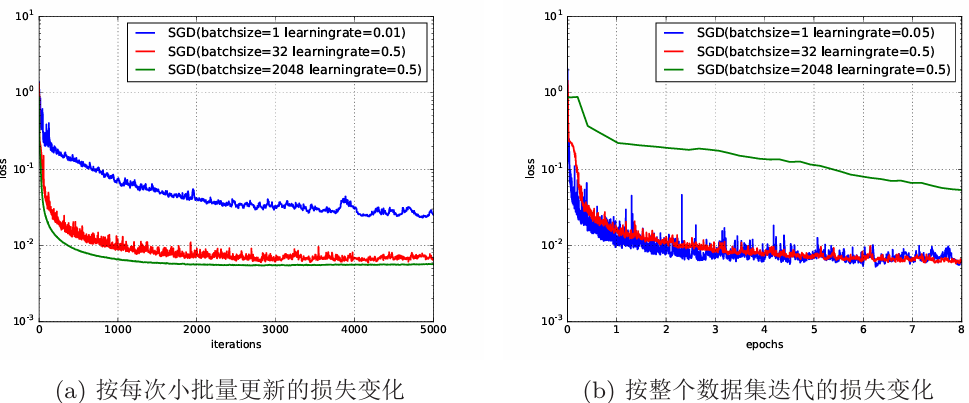
下图给出了不同批量大小,遵循线性缩放规则的训练结果,其中左边的是每一次更新的损失变化,右边的是每一轮更新的损失变化:
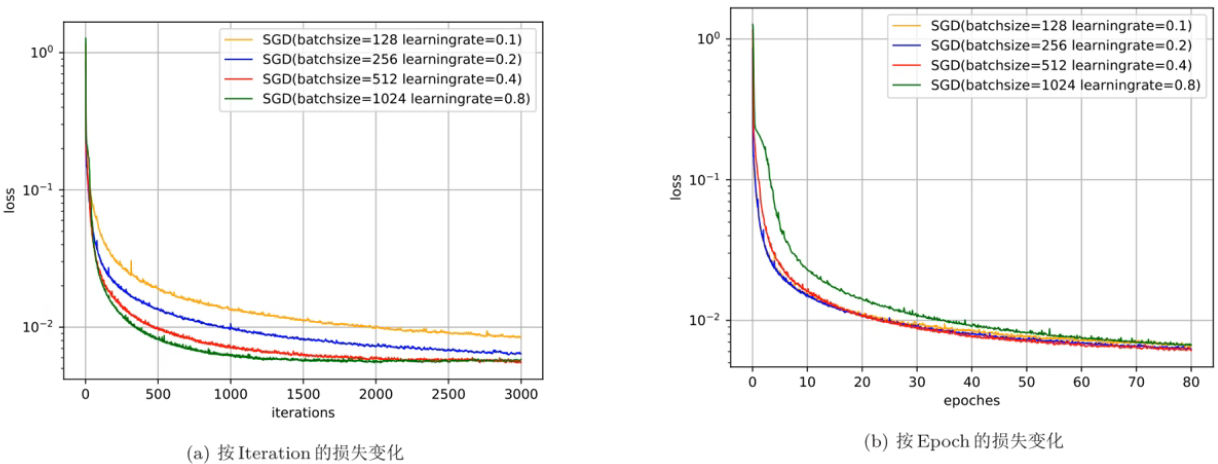
从图中可以看出:
按照每次更新来看:
- batch越大,一步走得越多,方向越正
- batch越小,一步走得越小,方向越随机
按照每一轮更新来看:
- batch越大,每一轮走的步数少,总体比较平滑
- batch越小,每一轮走的步数多,总体比较动荡
虽然大 batch 一步走的多,但走的步数少,总体可能不如小 batch 的积少成多,虽然小 batch 的方向随机,比较动荡
下图给出了不遵循线性缩放规则的训练结果,上述结论将更明显:
批量大小的设定
根据上图,得出结论:
- GPU能计算多大 batch 就尽量塞满
- 总样本数量来看:
- 样本数量大:考虑 效率 > 泛化力,batch 可以调大
- 样本数量小:考虑 泛化力 > 效率,batch 调小
动态学习率
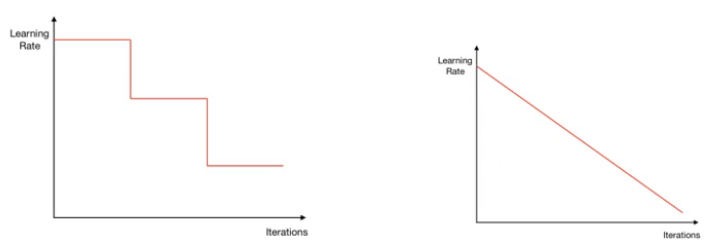
学习率衰减
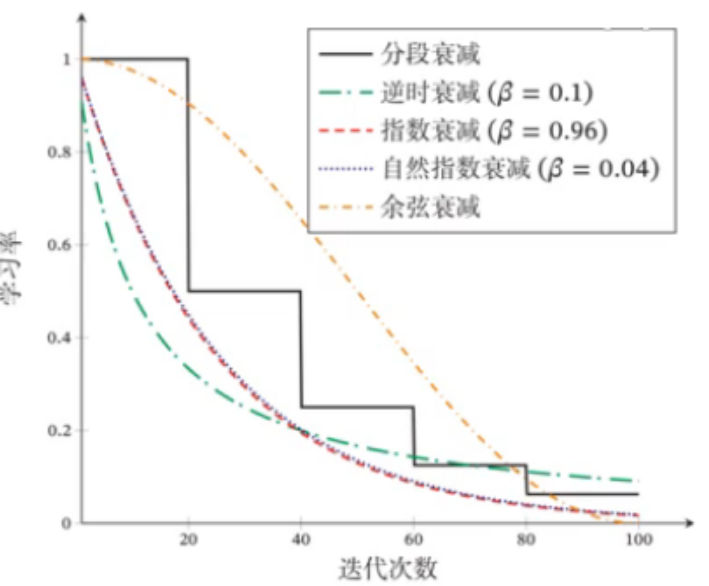
梯级衰减
线性衰减
逆时衰减 \[
\alpha_t=\alpha_0\frac{1}{1+\beta ·t}
\] 指数衰减 \[
\alpha_t=\alpha_0\beta^t
\] 自然指数衰减 \[
\alpha_t=\alpha_0e^{-\beta·t}
\] 余弦衰减 \[
\alpha_t=\frac{1}{2}\alpha_0(1+\cos(\frac{t\pi}{T}))
\] 
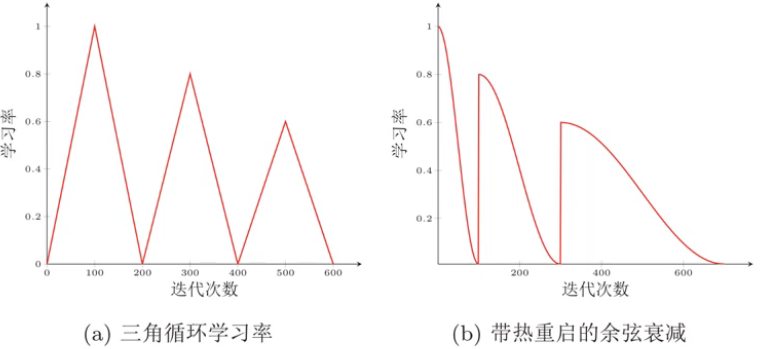
周期性学习率调整
- 三角循环学习率
- 带热重启的余弦衰减
方便跳出局部最优,同时也会倾向于更平坦的局部最优,提高模型的鲁棒性,不会因为一点变化而出现大幅变动
其他学习率调整方法
- 增大批量大小:由于批量越大,学习率应该越大,而固定学习率,增大批量,相当于减小学习率
- 学习率预热:由于初始点选得不一定好,梯度大且不稳定,不利于优化,在一开始学习率小一点,之后经过几轮学习后,参数不错时达到最大学习率后再开始衰减
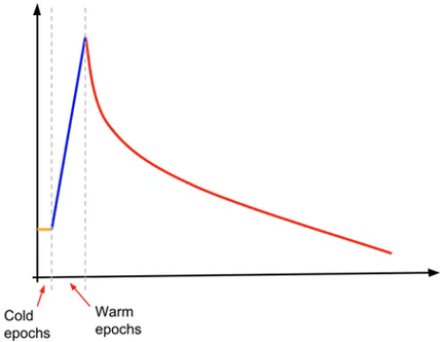
自适应学习率
定义第 \(t\) 次更新的梯度: \[ g_t\overset{\triangle}{=}\mathcal{G}_t(\theta_{t-1}) \] 使用梯度下降来更新参数: \[ \theta_t\leftarrow\theta_{t-1}-\alpha·g_t \]
每次迭代时参数更新的差值 \(\triangleθ_t\) 定义为: \[ \triangle\theta_t\overset{\triangle}{=}\theta_t-\theta_{t-1} \] 以下是各算法的计算方式:
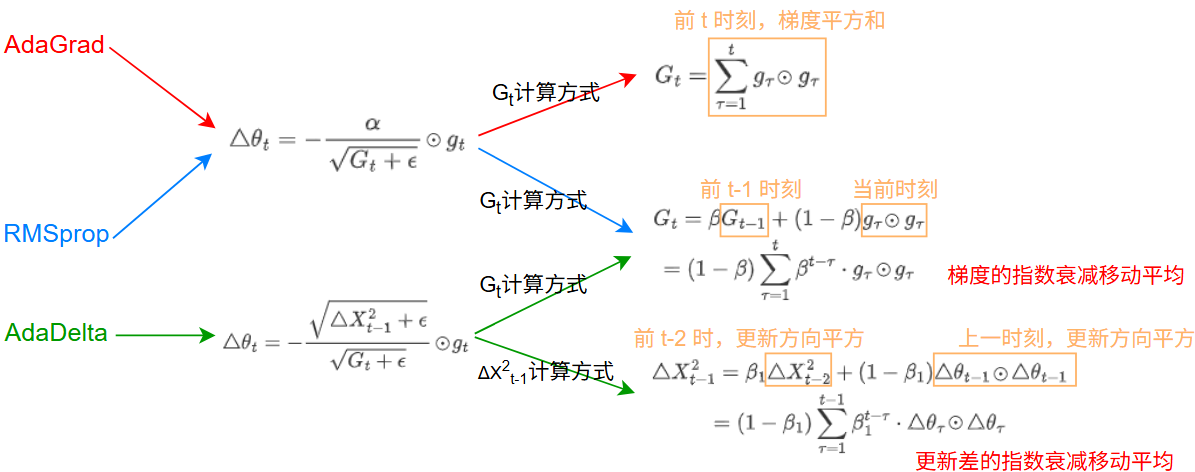
其中 \(\alpha\) 是学习率,\(\epsilon\) 是为了保持数值稳定性而设置的非常小的常数,一般取 \(e^7\) 到 \(e^{10}\)
AdaGrad算法:
如果某个参数的偏导数累积比较大,其学习率相对较小;相反,如果其偏导数累积较小,其学习率相对较大。但整体是随着迭代次数的增加,学习率逐渐缩小
缺点: 在经过一定次数的迭代依然没有找到最优点时,由于这时的学习率已经非常小,很难再继续找到最优点
RMSprop算法:
其中 \(\beta\) 为衰减率,一般取值为 0.9
RMSprop 算法和 AdaGrad 算法的区别在于 \(G_t\) 的计算由累积方式变成了指数衰减移动平均。在迭代过程中,每个参数的学习率并不是呈衰减趋势,既可以变小也可以变大
AdaDelta算法:
AdaDelta 算法将 RMSprop 算法中的初始学习率 \(\alpha\) 改为动态计算的 \(\sqrt{∆X^2_{t−1}}\) ,在一定程度上平抑了学习率的波动
梯度方向优化
动量法
用之前积累的动量来代替真正的梯度:(加权平均移动) \[ \begin{gather} \triangle \theta_t=\rho·\triangle \theta_{t-1}-\alpha·g_t \\ =-\alpha\sum^t_{\tau=1}\rho^{t-\tau}g_{\tau} \end{gather} \] 梯度与前几次方向相比:
- 某维度相同:加速梯度
- 某维度相异:互相抵消
可以看作近似的二阶梯度
类似向量加法,同方向向量相互叠加,异方向向量相互抵消
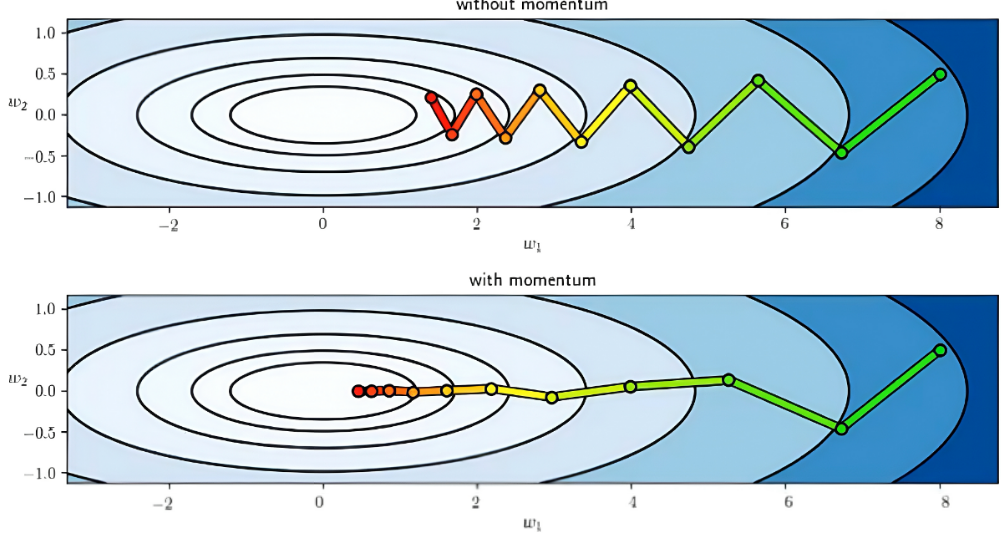
Nesterov加速梯度
在动量法中: \[ \triangle \theta_t=\rho·\triangle \theta_{t-1}-\alpha·g_t \]
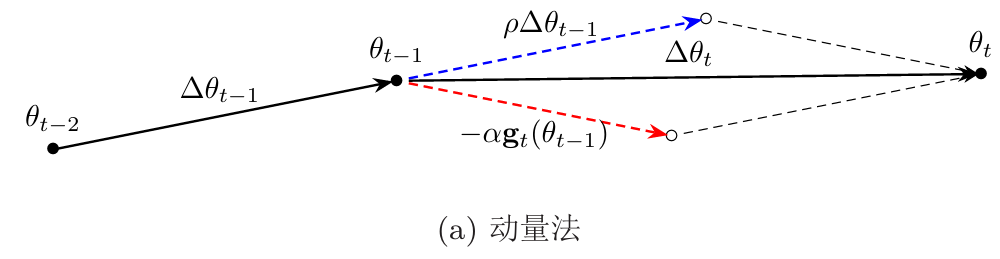
从 \(\theta_{t-1}\) 到 \(\theta_t\) 这一步分两步走:
第一步: \[ \rho·\triangle \theta_{t-1} \] 第二步: \[ -\alpha·g_t \] 但是发现一个问题,走了 \(\rho\triangle\theta_{t-1}\) 后,接下来的一步 \(-\alpha g_t(\theta_t-1)\) 用的是原来的梯度 \(\theta_{t-1}\) ,其实就相当于:走了一步之后返回原地,再走第二步,将两步再合起来
那我们可以在走了一步之后,在此基础上再走第二步
也就是第二步使用的梯度改为 \(\hat{\theta}=\theta_{t-1}+\rho\triangle\theta_{t-1}\) ,也就是第一步达到的“地方”:
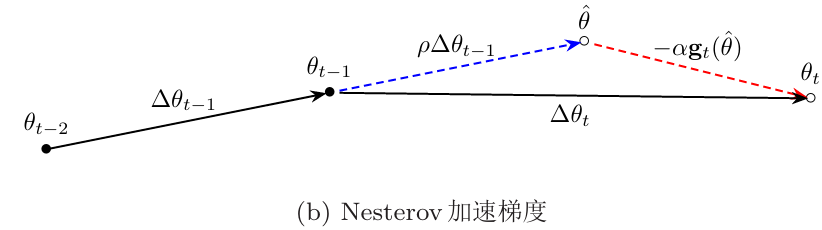
此时的参数更新差为: \[ \begin{gather} \triangle \theta_t=\rho·\triangle \theta_{t-1}-\alpha·g_t(\hat{\theta}) \\ \hat{\theta}=\theta_{t-1}+\rho\triangle\theta_{t-1} \end{gather} \]
Adam
将之前的二者结合起来:梯度方向优化 + 自适应学习率
Adam=动量法 + RMSprop
先计算动量的移动平均 \(M_t\) 和梯度的移动平均 \(G_t\) : \[ \begin{gather} M_t=\beta_1M_{t-1}+(1-\beta_1)g_t \\ G_t=\beta_2G_{t-1}+(1-\beta_2)g_t\odot g_t \end{gather} \] 当 \(t=1\) 时: \[ \begin{gather} M_1=(1-\beta_1)g_1 \\ G_1=(1-\beta_2)g_1\odot g_1 \end{gather} \] 理论上,\(M_1\) 的移动平均应该为:\(g_1\) 。 \(G_1\) 则为 \(g_1\ast g_1\)
因此,应该加上分母,将其抵消,来进行偏差修正: \[ \begin{gather} \hat{M_t}=\frac{M_t}{1-\beta_1^t} \\ \hat{G_t}=\frac{G_t}{1-\beta_2^t} \end{gather} \] 参数更新差为: \[ \triangle\theta_t=-\frac{\alpha}{\sqrt{\hat{G_t}+\epsilon}}\hat{M_t} \]
梯度截断
把梯度的模限定在一个区间,当梯度的模小于或大于区间时就截断,避免梯度爆炸
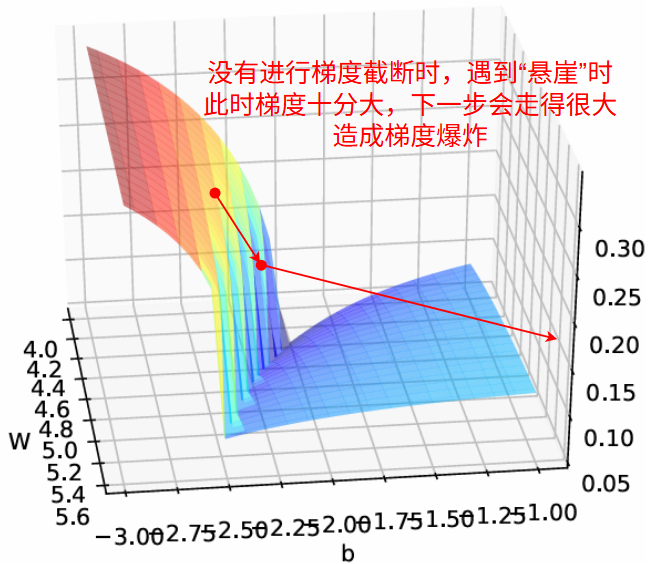
两种截断方式:
按值截断: \[ g_t=\max(\min(g_t,b),a)\;\Leftrightarrow\;[a,b] \] 按模截断: \[ g_t= \begin{cases} g_t \qquad \|g_t\|^2\leq b\\ \frac{b}{\|g_t\|}g_t\qquad \|g_t\|^2\geq b \end{cases} \] 小结:
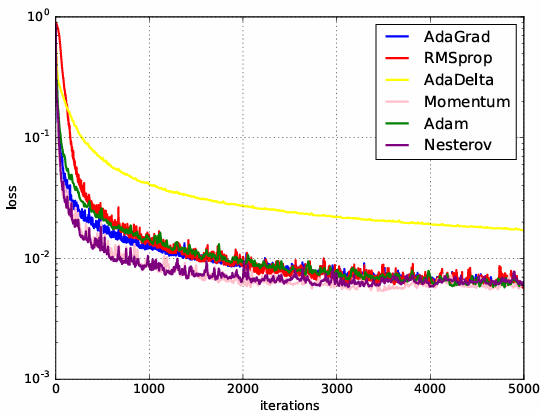
不同优化方法在MNIST数据集上收敛性的比较:
参数初始化
参数不能初始化为0,会产生对称权重问题:同一层神经元的表现一致
初始化方法:
- 预训练初始化:训练骨干网络(backbone)在下游应用进行微调
- 随机初始化
- 固定值初始化
- RNN中的门的权重
- 偏置(常初始化为0)
上述三种方法可以混合使用
随机初始化:
- 高斯分布初始化:使用固定均值(比如0)和方差进行高斯分布初始化
- 均匀分布初始化:在区间 \([-r,r]\) 内采用均匀分布进行初始化
范数保持性
一个 \(M\) 层的等宽线性网络: \[ y=W^lW^{l-1}W^{l-2}W^{l-3}...W^1x \] 为了避免梯度消失或梯度爆炸,我们希望误差项: \[ \|\delta^{l-1} \|^2=\|(W^l)^T\delta^l \|^2=\|\delta^l \|^2 \] 也就是每一层的误差项都尽量保持一致,那么就是令 \([(W^l)^T]^2\approx I\)
让 \([(W^l)^T]^2\approx I\) 的方法:
- 正交初始化:使 \(W\) 初始化为正交矩阵(正交矩阵的平方为单位阵)
- 基于方差缩放的参数初始化:随机采样使得 \([(W^l)^T]^2\approx I\)
正交初始化
方法:\((W^l)^2=I\)
- 用均值为0,方差为1的高斯分布初始化一个矩阵
- 将这个矩阵用奇异值分解得到两个正交矩阵
- 选择两个正交矩阵的其中一个作为权重矩阵
常用于 RNN
基于方差缩放的参数初始化
下面是需要用的概率论公式: \[ \begin{gather} Var(X)=E(X^2)-E(X)^2 \qquad <1> \\ \\ Var(X+Y)=Var(X)+Var(Y)\qquad 当\,X\,和\,Y\,相互独立\qquad <2> \\ \\ Var(XY)=Var(X)·Var(Y)+Var(X)E(Y)^2+Var(Y)E(X)^2\qquad <3> \end{gather} \]
Xavier初始化
给出三个假设:
- \(E(X)=0,\;E(W)=0\)
- \(f(·)\) 对称,且 \(f'(0)=1\;\Leftrightarrow\;y=x\;当\;x\in[-a,a]\)
- \(X\) 方差都相同
由上述三个假设可知:满足条件的激活函数只有双曲正切函数,如:Tanh
正向传播
给出输入大小为 \(n\) ,输出大小为
\(m\) 的神经网络 正向传播
示意图:
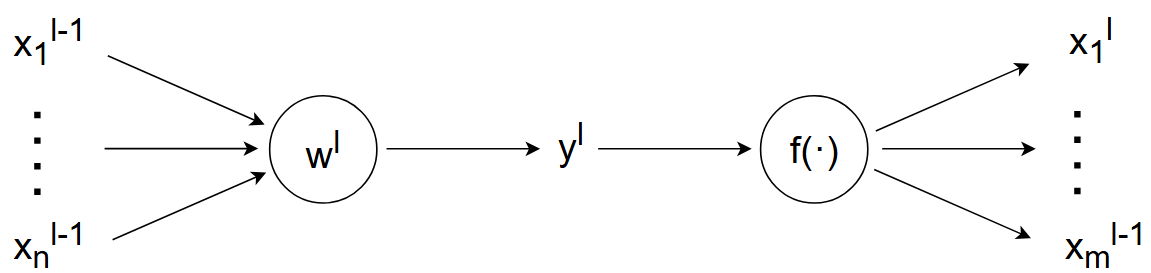
图中从左往右为正向传播,忽略偏置 \(b\) : \[ \begin{gather} y^l=\sum_{i=1}^nx_i^{l-1}·w_i^l\\ \overset{X与W独立同分布+公式<2>}{\rightarrow}\;\; Var(y^l)=\sum_{i=1}^nVar(x_i^{l-1}·w_i^l) \\ \overset{假设3.}{\rightarrow}\;\; =n·Var(x_i^{l-1}·w_i^l) \\ \overset{公式<3>}{\rightarrow}\;\;=n·[Var(x_i^{l-1})·Var(w_i^l)+Var(x_i^{l-1})·E(w_i^l)+Var(w_i^l)·E(x_i^{l-1})] \\ \overset{假设1.}{\rightarrow}\;\;=n·Var(w_i^l)·Var(x_i^{l-1}) \\ \overset{假设2.+3.}{\rightarrow}\;\;=n·Var(w_i^l)·Var(y^{l-1}) \\ \Leftrightarrow Var(y^l)=n·Var(w_i^l)·Var(y^{l-1}) \end{gather} \] 由于我们希望每一层训练稳定,也就是:\(Var(y^l)=Var(y^{l-1})\) ,那么: \[ \begin{gather} Var(y^l)=n·Var(w_i^l)·Var(y^{l-1}) \\ \Downarrow \\ 1=n·Var(w_i^l) \\ Var(w_i^l)=\frac{1}{n}=\frac{1}{n_{in}} \end{gather} \] \(n_{in}\) 表示正向传播的输入大小
反向传播
给出输入大小为 \(n\) ,输出大小为
\(m\) 的神经网络 反向传播
示意图:
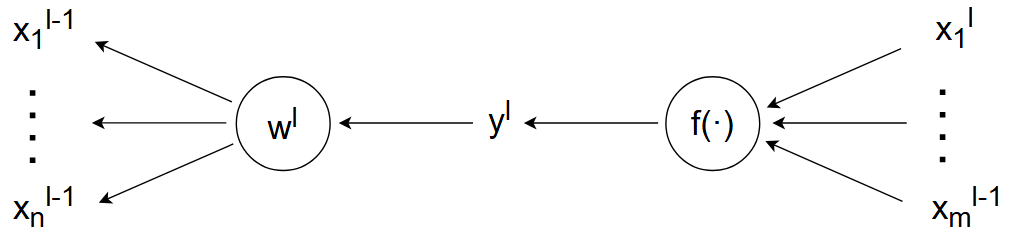
图中从右往左为反向传播,对于损失项 \(\delta^{l-1}\) : \[ \delta^{l-1}=\sum_{i=1}^m\delta^l·\frac{\partial x_i^l}{\partial y^l}·\frac{\partial y^l}{\partial x_i^{l-1}} \overset{假设2.}{=}\;\;\sum_{i=1}^m\delta^l·w_i^l \] 此处化简过程同正向传播,省略直接写结果: \[ Var(\delta^{l-1})=m·Var(\delta^l)·Var(w_i^l) \] 由于希望每层训练稳定,也就是 \(Var(\delta^l)=Var(\delta^{l-1})\) ,那么: \[ \begin{gather} Var(\delta^l)=m·Var(w_i^l)·Var(\delta^{l-1}) \\ \Downarrow \\ 1=m·Var(w_i^l) \\ Var(w_i^l)=\frac{1}{m}=\frac{1}{n_{out}} \end{gather} \] \(n_{out}\) 表示正向传播的输出大小
综合正向与反向传播
\[ Var(w_i^l)=\frac{2}{n_{in}+n_{out}} \]
为了求出该值,可以使用:
- 正态分布初始化
- 均匀分布初始化
正态分布初始化: \[ N(0,\sigma^2) \] 此时 \(\sigma^2=Var(·)\) ,即: \[ N(0,\frac{2}{n_{in}+n_{out}}) \] 均匀分布初始化: \[ U(a,b) \] 根据假设2. 我们的区间是对称的 \([-a,a]\) ,所以: \[ \begin{gather} \because \;Var(X)=E(X^2)-E(X)^2=\frac{(b-a)^2}{12} \\ \therefore\; Var=\frac{(a-(-a))^2}{12}=\frac{a^2}{3}=\frac{2}{n_{in}+n_{out}} \\ \Rightarrow\;a=\sqrt{\frac{6}{n_{in}+n_{out}}} \end{gather} \] 最后结果为: \[ U(-\sqrt{\frac{6}{n_{in}+n_{out}}},\,\sqrt{\frac{6}{n_{in}+n_{out}}}) \]
Kaiming初始化(He初始化)
由于 Xavier 的三个假设,导致其对 ReLu 激活函数的效果不是很好,而 Kaiming 初始化对 ReLu 效果很好: \[ ReLu= \begin{cases} x\qquad x\geq0 \\ \alpha x\qquad x<0 \end{cases} \] 具体简化过程,和 Xavier 异曲同工,这里作省略
最终简化为: \[ \begin{gather} Var(y^l)=\frac{1}{2}n(1+\alpha^2)·Var(w_i^l)·Var(y^{l-1}) \\ \because\; Var(y^l)=Var(y^{l-1}) \\ \therefore\; Var(w_i^l)=\frac{2}{n(1+\alpha^2)} \end{gather} \] 上述结论对正向与反向都可行,不讨论两种情况
对于两种分布的计算与 Xavier 相同,这里直接写结果:
正态分布初始化: \[ N(0,\frac{2}{n(1+\alpha^2)}) \] 均匀分布初始化: \[ U(-\sqrt{\frac{6}{n(1+\alpha^2)}},\,\sqrt{\frac{6}{n(1+\alpha^2)}}) \]
总结
参数含义: \[ \begin{gather} M_{l-1}\rightarrow n_{in} \\ M_l\rightarrow n_{out} \end{gather} \]
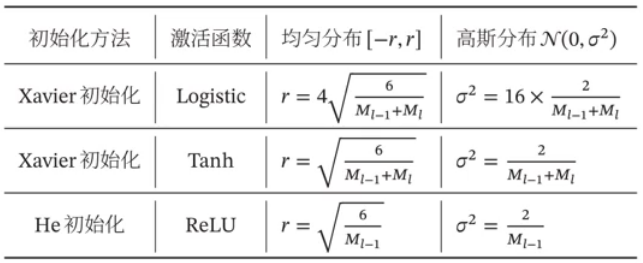
上述的 Kaiming(He)初始化中的 \(\alpha=0\)
数据预处理
尺度不变性
机器学习算法在缩放全部或部分特征后,不影响学习和预测
KNN算法不具备尺度不变性,其受尺度大的特征主导
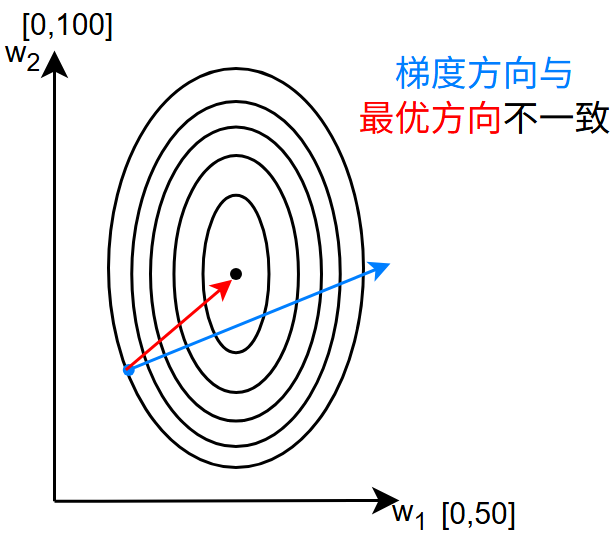
若不同的特征间尺度差异较大: \[ \begin{gather} y=w_1x_1+w_2x_2+b \\ x_1\in[0,1] \\ x_2\in[0,10000] \end{gather} \] 对于以上情况,\(x_2\) 会主导学习
我们就需要将 \(w_2\) 初始化更小来应对,后果是 \(w\) 的参数分布不一致,参数初始化有难度
同时,这种情况对优化也有影响:
归一化
归一化是将数据缩放到一个固定的范围内,通常是 \([0, 1]\) 或 \([-1, 1]\)
又称为最大最小规范化(Min-Max Scaling) \[ \hat{x}^{(n)}=\frac{x^{(n)}-\min_n(x^{(n)})}{\max_n(x^{(n)})-\min_n(x^{(n)})} \]
标准化
标准化是将数据转换为均值为0,标准差为1的分布
这种方法也被称为 Z 分数标准化(Z-score normalization) \[ \begin{gather} \hat{x}^{(n)}=\frac{x^{(n)}-\mu}{\sigma} \\ \mu=\frac{1}{N}\sum_{n=1}^Nx^{(n)} \\ \sigma^2=\frac{1}{N}\sum_{n=1}^N(x^{(n)}-\mu)^2 \end{gather} \] 分母的 \(\sigma\) 不可能为0,若为0,则说明该维的数据一致,无区分性,可以去除
逐层规范化
目的:
- 更好的尺度不变性——解决内部协变量偏移问题
- 更平滑的优化地形
内部协变量偏移: 即上一层输入满足某一分布,而经过一层线性/非线性变换后的输出却变成另一种分布,使得下一层输入要适应这种新输入
协变量偏移: 指训练数据和测试数据输入特征空间的分布不一致,即:训练集和测试集的概率分布存异,但条件概率分布一致
例如:训练集是市中心房价数据,测试集是郊区房价数据,二者的分布可能不同,但是都满足一个条件:面积与房价成正比
规范化方法:
- 批量规范化(Batch Normalization,BN)
- 层规范化(Layer Normalization,LN)
- 权重规范化(Weight Normalization,WN)
- 局部响应规范化(Local Response Normalization,LRN)
批量规范化
神经网络第 \(l\) 层为: \[ a^l=f(z^l)=f(Wa^{l-1}+b) \] 给定一个包含 \(k\) 个样本的小批量样本集合,计算均值和方差 \[ \begin{gather} \mu_B=\frac{1}{k}\sum_{k=1}^kz^{(k,l)} \\ \sigma_B^2=\frac{1}{k}\sum_{k=1}^k(z^{(k,l)}-\mu_B)\odot(z^{(k,l)}-\mu_B) \end{gather} \] 批量规范化: \[ \hat{z^l}=\frac{z^l-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}\odot\gamma+\beta\;\overset{\triangle}{=}\;BN_{\gamma,\,\beta}(z^l) \] 其中的 \(\gamma,\;\beta\) 为可学习参数,代表缩放和平移的参数向量,若效果不好,可以学习回来
批量归一化操作可以看作是一个特殊的神经层,加在每一层非线性激活函数之前,即: \[ a^{(l)}=f(BN_{\gamma,\,\beta}(z^{(l)}))=f(BN_{\gamma,\,\beta}(Wa^{(l-1)})) \] 由于批量归一化本身具有平移变换,因此不需要偏置参数
优点:
- 提高优化效率
- 隐形的正则化:训练时,某一样本会受到同一批其他样本的影响,神经网络不会对某一样本“过拟合”
缺点:
- 小批量样本数不能太小
- 无法应用到循环神经网络中
层规范化
若BN是对一个批次进行规范化,那LN就是对每个样本的每个特征规范化
第 \(l\) 层神经元的净输入为 \(z^l\) \[ \begin{gather} \mu^l=\frac{1}{M_l}\sum_{i=1}^{M_l}z_i^l \\ \sigma^{2^l}=\frac{1}{M_l}\sum_{i=1}^{M_l}(z_i^l-\mu^l)^2 \end{gather} \] 其中 \(M_l\) 为第 \(l\) 层的神经元数量
层规范化: \[ \hat{z^l}=\frac{z^l-\mu^l}{\sqrt{\sigma^{2^l}+\epsilon}}\odot\gamma+\beta\;\overset{\triangle}{=}\;LN_{\gamma,\,\beta}(z^l) \] 其中的 \(\gamma,\;\beta\) 为可学习参数,代表缩放和平移的参数向量,若效果不好,可以学习回来
批规范化VS层规范化
举一个例子:
一个班进行一场考试,考试科目难度可能不同,对于难的科目,大家成绩都低,对于简单的科目,大家成绩都高,单纯比较不同科目分数会很不公平,需要让不同科目的成绩在同一标准下进行比较
批规范化:
对全班学生的每一科进行规范化:
计算:
- \(\mu\) :全班每一科平均分
- \(\sigma^2\) :全班每一科的方差
调整:将每个学生的成绩减去该科目的全班平均分,再除以该科目的全班方差
重新调整:
- 乘以 \(\gamma\) :让成绩更分散/集中
- 加上 \(\beta\) :让成绩更高/低
批规范化会清除学生的特点:如某学生在某一科目上的优秀,会受到其他学生的影响
层规范化:
对单独一个学生的每一科成绩进行规范化:
计算:
- \(\mu\) :该学生所有科目的平均分
- \(\sigma^2\) :该学生所有科目的方差
调整:将该学生的每科成绩减去该学生所有科目的平均分,再除以该学生所有科目的方差
重新调整:
- 乘以 \(\gamma\) :让成绩更分散/集中
- 加上 \(\beta\) :让成绩更高/低
层规范化会针对每个学生自己的成绩调整,不会受其他学生影响,保留每个学生特点
所以说层规范化更适合 RNN ,因为时间序列上的每一时间步都是一个学科, 层规范化会保留时间上的特点,而批规范化会消除这种特点
超参数优化
超参数:
- 网络层数
- 神经元个数
- 激活函数
- 学习率
- 正则化系数
- 批量大小
- ...
网格搜索(Grid Search)
网格搜索是最简单的超参数优化方法之一,它通过穷举所有可能的超参数组合来寻找最优解
工作原理
定义一个超参数网格,例如学习率为 \([0.001,0.01,0.1]\) ,批次大小为 \([32,64,128]\)
对每一种超参数组合进行训练和验证,记录每种组合的验证性能,选择验证性能最好的超参数组合
总结
优点:
- 简单直观,容易实现
- 保证在给定的网格范围内找到最优解
缺点:
- 计算成本高,尤其是当超参数空间比较大时
- 无法处理连续的超参数空间,只能在离散的网格点上搜索
随机搜索(Random Search)
随机搜索通过随机采样超参数组合来进行优化,而不是穷举所有可能的组合
工作原理
定义超参数的取值范围,例如学习率在 \([0.001,0.1]\) 之间,批次大小在 \([32,256]\) 之间
随机生成一定数量的超参数组合,对每种组合进行训练和验证,记录性能,选择性能最好的组合
总结
优点:
- 比网格搜索更高效,尤其是在超参数空间较大时
- 可以处理连续的超参数空间
缺点:
- 无法保证找到全局最优解,但通常能找到较好的解
其他优化方法
前两个时常用的超参数优化方法,除了上述几种,还有以下几种,这里不做详细解释,感兴趣可以了解
- 贝叶斯优化
- 遗传算法
- 动态资源分配
- 神经架构搜索
- 基于梯度的优化
- 超参数优化框架
- Sklearn:提供网格搜索和随机搜索
- Hyperopt:一个基于贝叶斯优化的超参数优化库
- Optuna:一个轻量级的超参数优化框架,支持多种优化算法
- Ray Tune:一个分布式超参数优化框架,支持多种优化算法和大规模并行训练
网络正则化
重新思考泛化性
神经网络:
- 拟合能力强
- 过度参数化
根据传统机器学习观点,模型越复杂其泛化能力越差
事实上,很多神经网络模型训练出来有很高的泛化性,这让我们重新思考其泛化性:
神经网络优先记住普遍规律,再去记住特例/噪声 ,这其实就是一个从泛化性到过拟合的过程
正则化
(非正式定义)所有损害优化的方法都是正则化
- 增加优化约束:L1、L2约束,数据增强
- 干扰优化过程:权重衰减,随机梯度下降,早停法,暂退/丢弃法(Dropout)
对于L1、L2约束在机器学习入门系列文章以及讲过,这里不做赘述
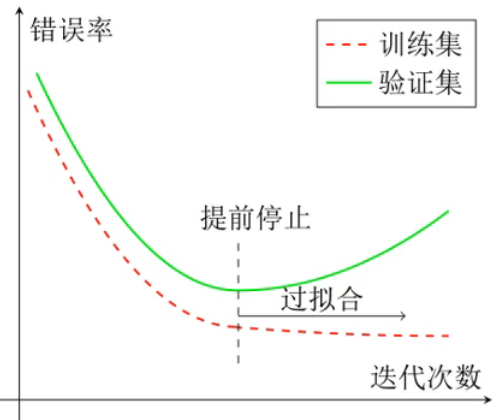
早停法(Early-stop)
使用一个验证集来测试每一次迭代参数在验证集上是否最优,若验证集上错误率不再下降,就停止
权重衰减
通过限制权重的取值范围来干扰优化过程,降低模型能力
每次更新时引入一个衰减系数 \(\beta\) \[ \theta_t\leftarrow(1-\beta)\theta_{t-1}-\alpha g_t \] \(\beta\) 一般很小,比如:0.0005
在 标准的随机梯度下降
中,权重衰减正则化和L2正则化的效果相同
L2正则化: \[ \begin{gather} Q_t=(1-\alpha\lambda)Q_{t-1}-\alpha g_t \\ \Updownarrow \\ \theta_t\leftarrow(1-\beta)\theta_{t-1}-\alpha g_t \end{gather} \] 在较为复杂的优化方法中(如Adam),权重衰减和L2正则化并不等价
暂退/丢弃法(Dropout)
对于一个神经层: \(y=f(Wx+b)\)
当神经元数量足够多时,会产生协同效应,导致两个神经元的行为可能一致,影响鲁棒性
引入一个掩蔽函数,使得 \[ \begin{gather} y=f(W·mask(x)+b) \\ mask(x)=m\odot x\qquad m\in\{0,1\}^D \end{gather} \] 其中 \(m\) 充当掩码的角色,通过概率为 \(p\) 的贝努力分布生成
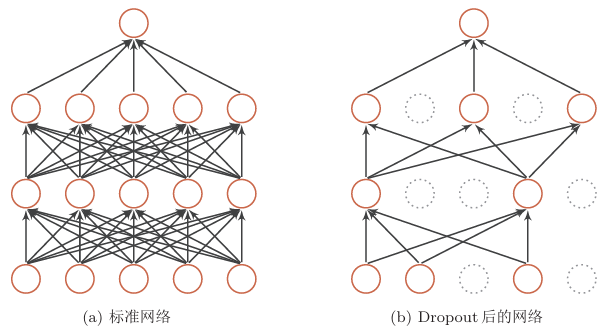
训练时使用 Dropout,测试时用完整的网络
问题:训练和测试时的网络的输出不一致
解决:测试时,\(mask(x)=px\) 把输出变成原来的 \(p\) 倍(期望)
掩码函数 \(mask(x)\) 的完整定义: \[ mask(x)= \begin{cases} m\odot x \qquad train \\ px\qquad\quad test \end{cases} \]
意义
集成学习上的解释:
每做一次暂退,相当于从原始网络中采样得到一个子网络,如果一个神经网络有 \(n\) 个神经元,那总共可以采样出 \(2^n\) 个子网络,最后使用的是所有子网络的集成
贝叶斯学习的解释: \[ \begin{gather} E_{q(\theta)}[y]=\int_qf(x,\theta)q(\theta)d\theta \\ \approx\frac{1}{M}\sum_{m=1}{M}f(x,\theta_m) \end{gather} \] 其中 \(f(x,\theta_m)\) 为第 \(m\) 次应用丢弃方法后的网络,其参数 \(\theta_m\) 为对全部参数 \(\theta\) 的一次采样
循环神经网络上的暂退
当在循环神经网络上使用暂退法,不能直接对每个时刻的隐状态进行随机暂退,这样会损害循环网络在时间维度上的记忆能力
变分Dropout
根据贝叶斯学习解释,暂退法是一种对参数 \(\theta\) 的采样,每次采样的参数要在每个时刻保持不变
在对循环神经网络上使用暂退法时,需要对这个参数矩阵的每个元素进行随机暂退,并在所有时刻都使用相同的暂退掩码
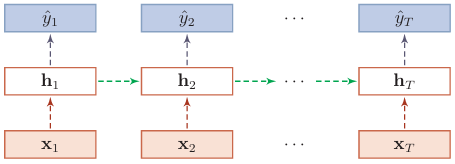
上图给出了变分丢弃法的示例,相同颜色表示使用相同的丢弃掩码
数据增强
人工构造新的样本来增加训练数据的数量和多样性
图像数据:通过算法对图像进行转变
- 旋转
- 翻转
- 缩放
- 平移
- 加噪声
- ...
文本数据:
- 词汇替换
- 回译
- 随机编辑噪声
- 增删改
- 句子乱序
标签平滑:
在输出标签中添加噪声来避免模型过拟合
一个样本 \(x\) 的标签一般用 one-hot
向量表示: \[
y=[0,...,0,1,0,...,0]^T
\] 上述 one-hot 向量为 硬标签
,也就是除了正确的标签为1,其余为0
引入一个噪声对标签进行平滑,即假设样本以 \(\epsilon\) 的概率为其他类,平滑后为: \[ \hat{y}=[\frac{\epsilon}{k-1},....\frac{\epsilon}{k-1},\,1-\epsilon,\,\frac{\epsilon}{k-1},...,\frac{\epsilon}{k-1}]^T \] 其中的 \(1-\epsilon\) 为正确标签
总结
模型
- 用 ReLu 作为激活函数
- 残差连接
- 逐层规范化
优化
- SGD + mini-batch(动态学习率、Adam算法优先)
- 每次迭代都重新随机排序
- 数据预处理(规范化)
- 参数初始化(预训练)
正则化
早停法
暂退/丢弃法
权重衰减
SGD
批量规范化
L1和L2正则化
数据增强
从0了解深度学习——网络优化与正则化