从0了解深度学习——循环神经网络
本文章将介绍深度学习中的循环神经网络
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
引言
前馈神经网络: 相邻两层之间存在单向连接,层内无连接
- 有向无环图
- 输入和输出的维数都是固定的,不能任意改变
- (全连接前馈网络)无法处理变长的序列数据
前馈神经网络可以看着是一个复杂的函数,每次输入都是独立的,即网络的输出只依赖于当前的输入
但是在很多现实任务中,网络的输入不仅和当前时刻的输入相关,也和其过去一段时间的输出相关,比如有限状态自动机等:
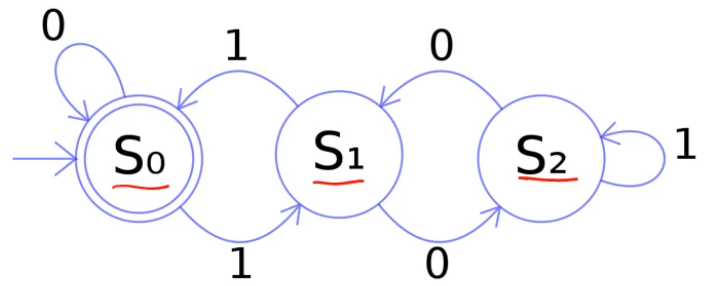
其下一个时刻的状态(输出)不仅仅和当前输入相关,也和当前状态(上一个时刻的输出)相关
对于可计算问题:
- 不需要记忆能力: \(y=f(x)\;\rightarrow\;S_{t+1}=f(x,S_t)\)
- 前馈网络
- 需要记忆能力: \(y_t=f(x_t,memory)\)
- 有限自动机
- 图灵机
如何给网络增加记忆能力
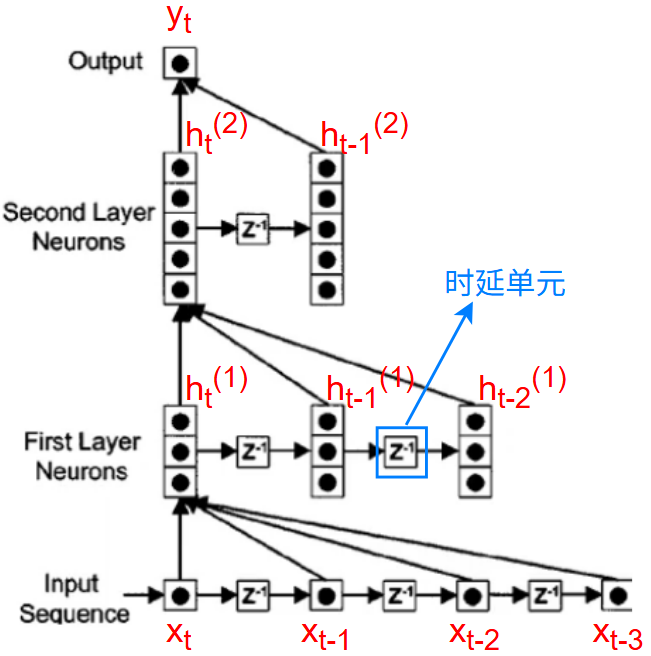
时延神经网络(TDNN)
建立一个额外的延时单元,用来存储网络的历史信息(可以包括输入,输出,隐状态等)
在第 \(t\) 个时刻,第 \(l\) 层神经元和第 \(l-1\) 层神经元的最近 \(k\) 次输出相关,即: \[ h_t^l=f(h_t^{l-1},h_{t-1}^{l-1},h_{t-2}^{l-1},...,h_{t-k+1}^{l-1}) \] 这样,前馈神经网络就具有了短期记忆能力:
自回归模型(AR)
没有外部输入
一类时间序列模型,用变量 \(y_t\) 的历史信息,来预测自己 \[ \begin{gather} y_t=w_0+\sum_{k=1}^kw_k·y_{t-k}+\epsilon_0 \\ y_0\overset{预测}{\rightarrow}y_1\overset{预测}{\rightarrow}y_2\overset{预测}{\rightarrow}y_3 \end{gather} \] \(\epsilon_0 \sim N(0,\sigma^2)\) 为 \(t\) 时刻的噪声
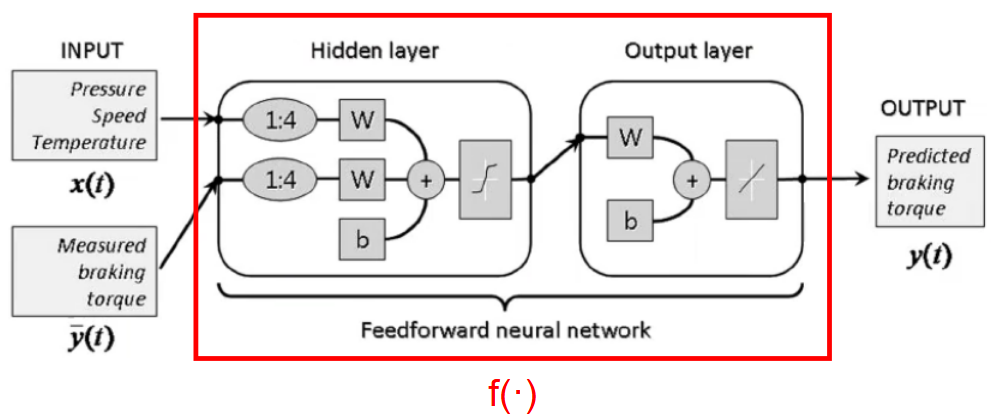
有外部输入
是自回归模型的扩展,每个时刻 \(t\) 都有一个外部输入 \(x\) ,产生一个输出 \(y_t\) ,再通过延时器记录最近几次的外部输入和输出: \[ y_t=f(x_t,x_{t-1},...,x_{t-p}\,;\;y_{t-1},y_{t-2},...,y_{t-q}) \] 其中 \(f(·)\) 表示非线性函数,可以是一个前馈网络,\(p\) 和 \(q\) 为超参数
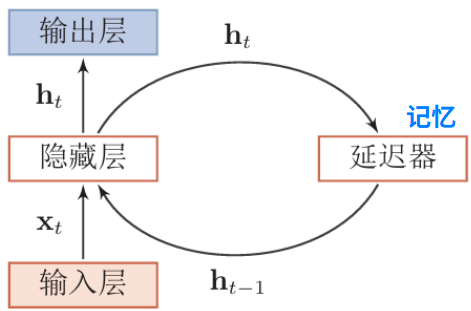
循环神经网络(RNN)
通过使用带自反馈的神经元,能够处理任意长度的时序数据
给定一个输入序列 \(x_{1:T} =(x_1,x_2,...,x_t,...,x_T)\),循环神经网络通过下面公式更新带反馈边的隐藏层的活性值 \(ht\) : \[ h_t=f(h_{t-1,x_t}) \] 其中 \(h_0=0\) ,\(f(·)\) 为一个非线性函数,也可以是一个前馈网络
循环神经网络比前馈神经网络更符合生物神经网络结构,其已经被广泛应用在语言识别、语言模型以及自然语言生成等任务
在时间维度上展开:
简单循环网络(SRN)
状态更新: \[ h_t=f(Uh_{t-1}+Wx_t+b) \] 其中 \(f(·)\) 为 sigmoid 函数
RNN通用近似定理: 一个完全连接的循环网络是任何非线性动力系统的近似器
图灵完备: 一种数据操作规则,比如一种计算机编程语言,可以实现图灵机的所有功能,解决所有问题
所有的图灵机都可以被一个由使用sigmoid型激活函数的神经元构成的全连接循环网络来进行模拟,所以一个完全连接的循环神经网络可以近似解决所有的可计算问题
若前馈网络能够模型任何函数,那么RNN可以模拟任何程序
RNN作用:
- 输入—输出映射(ML模型)
- 存储器(联想记忆模型)
应用到机器学习
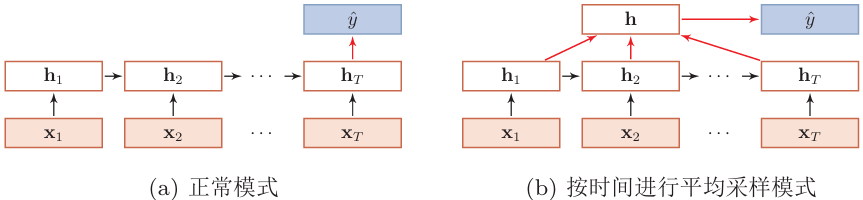
序列到类别
输入序列,输出类别
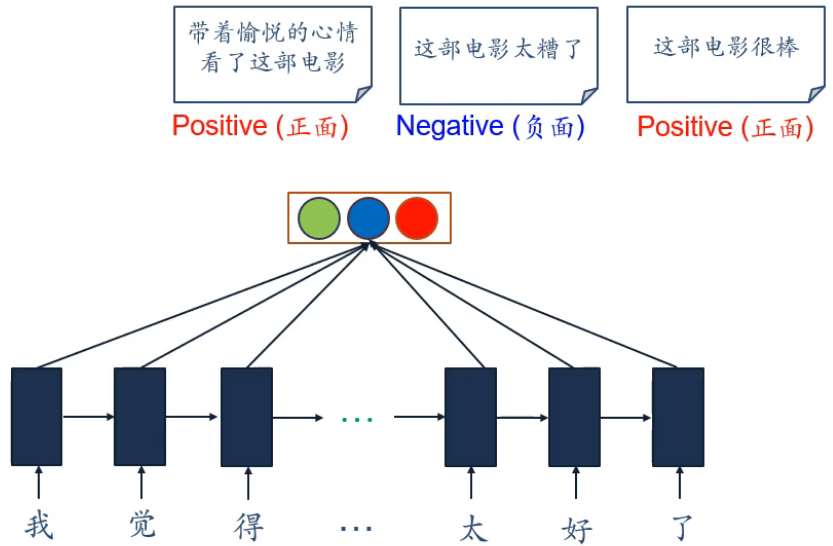
应用:情感分类
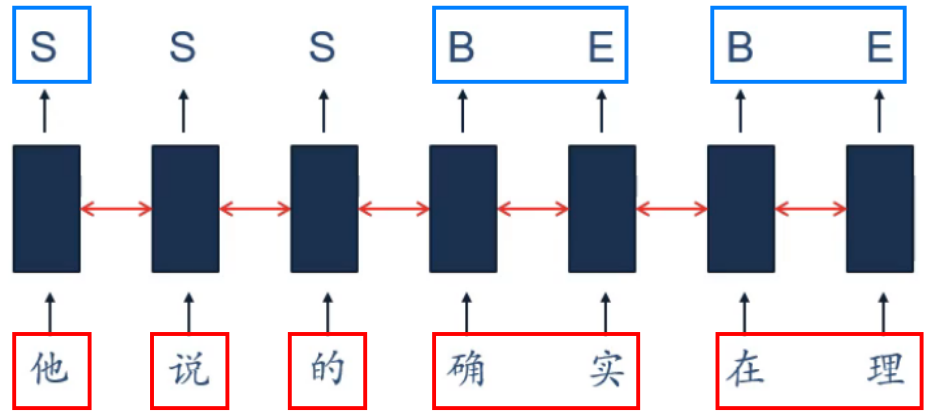
同步的序列到序列
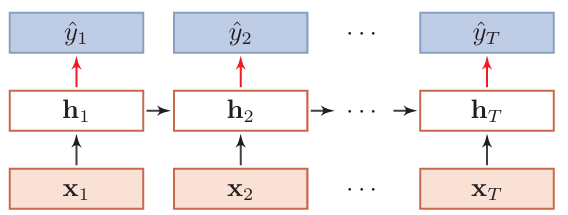
应用:中文分词
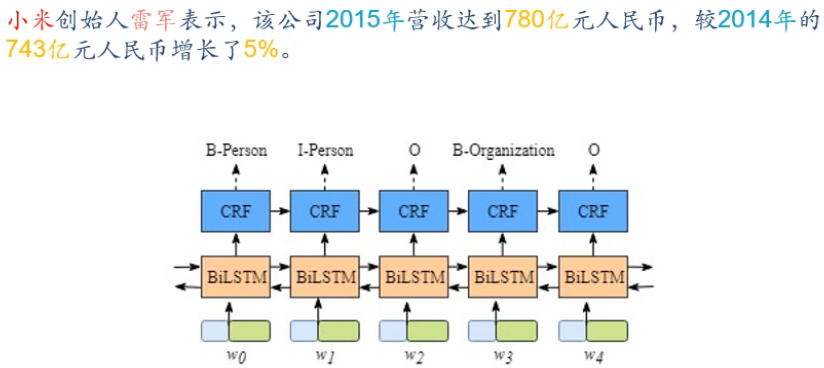
信息抽取
从无结构的文本中抽取结构化的信息,形成知识
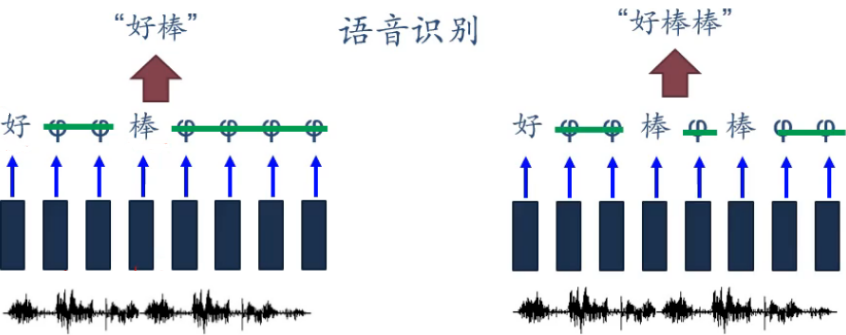
语音识别
异步的序列到序列
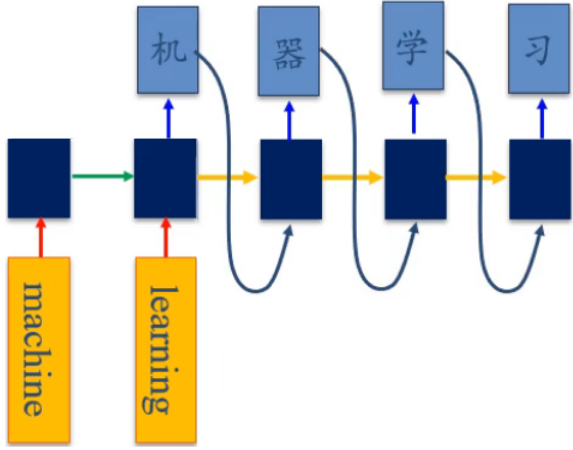
循环神经网络+自回归
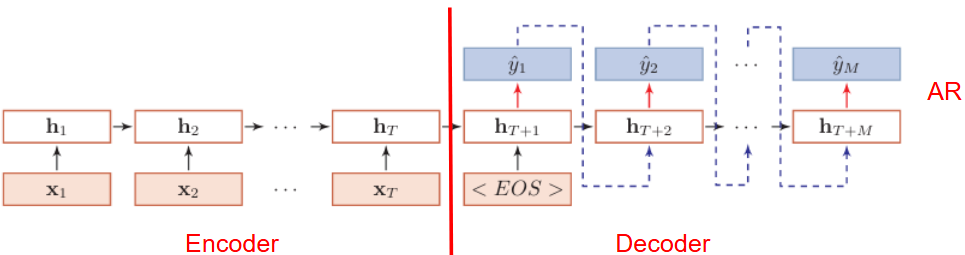
应用:机器翻译
参数学习
损失函数
给定一个训练样本 \((x,y)\) ,其中:
- 长度为 \(T\) 的输入序列 \(x=x_1,...,x_T\)
- 长度为 \(T\) 的标签序列 \(y=y_1,...,y_T\)
时刻 \(t\) 的瞬时损失函数为: \[ L_t=L(y_t,g(h_t)) \] 总损失函数: \[ L=\sum_{t=1}^TL_t \]
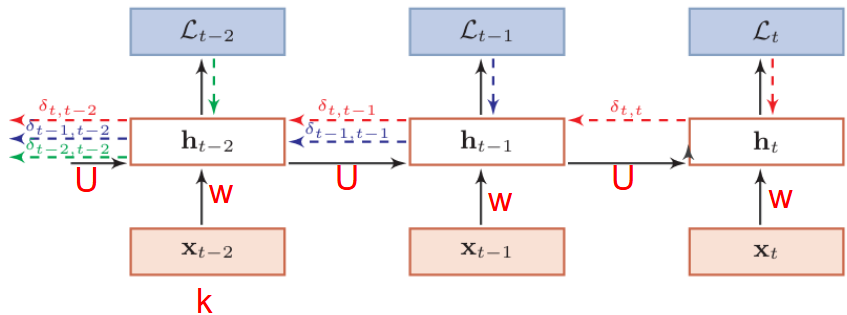
求偏导
已知: \[ \begin{gather} z_t=Uh_{t-1}+Wx_t+b \\ h_t=f(z_t) \end{gather} \] 则以 \(U\) 为例,整个序列的损失函数 \(L\) 关于参数 \(U\) 的梯度为: \[ \frac{\partial L}{\partial U}=\sum_{t=1}^T\frac{\partial L_t}{\partial U} \] 因为参数U和隐藏层在每个时刻 \(k(1≤k≤t)\) 的净输入 \(z_k=Uh_{k−1}+ Wx_k+b\) 有关,因此第 \(t\) 时刻损失的损失函数 \(L_t\) 关于参数 \(U\) 的梯度为: \[ \begin{gather} \frac{\partial L_t}{\partial U}=\sum_{t=1}^t\frac{\partial L_t}{\partial z_k}·\frac{\partial z_k}{\partial U} \\ =\sum_{t=1}^T\frac{\partial L_t}{\partial z_k}·h_{k-1}^T\quad (h^T 表示转置) \\ =\sum_{t=1}^T\delta_{t,k}·h_{k-1}^T \end{gather} \] 误差项 \(\delta_{t,k}\) 为第 \(t\) 时刻的损失函数对第 \(k\) 步隐藏神经元的净输入 \(z_k\) 的导数
对于 \(\delta_{t,k}\) : \[ \begin{gather} \delta_{t,k}=\frac{\partial L_t}{\partial z_k} \\ =\frac{\partial h_k}{\partial z_k}·\frac{\partial z_{k+1}}{\partial h_k}·\frac{\partial L_t}{\partial z_{k+1}} \\ =diag(f'(z_k))·U^T·\delta_{t,k+1} \end{gather} \] 这就是随时间反向传播算法(BPTT)
求梯度
第 \(t\) 时刻损失的损失函数 \(L_t\) 关于参数 \(U\) 的梯度为: \[ \frac{\partial L_t}{\partial U}=\sum_{t=1}^T\delta_{t,k}·h_{k-1}^T \] 误差项 \(\delta_{t,k}\) : \[ \begin{gather} \delta_{t,k}=diag(f'(z_k))·U^T·\delta_{t,k+1}\qquad (将\delta_{t,k}反复嵌套) \\ =\prod_{\tau=k}^{t-1}(diag(f'(z_\tau)·U^T))·\delta_{t,t} \\ 令: diag(f'(z_\tau)·U^T)\approx r \\ \delta_{t,k}=\prod_{\tau=k}^{t-1}r·\delta_{t,t} \\ \approx r^{t-k}·\delta_{t,t} \end{gather} \] 因为 \(diag(f'(z_\tau)·U^T)\) 是共享参数,使用 \(\delta_{t,k}\) 嵌套之后,该参数可以直接连乘,将其令为新参数 \(r\) ,所以: \[ \delta_{t,k}\approx r^{t-k}·\delta_{t,t} \]
长程依赖问题(Long-Term Dependencies Problem)
但是,根据观察发现: \[
\delta_{t,k}\approx r^{t-k}·\delta_{t,t}
\begin{cases}
r>1\;,\qquad t-k\rightarrow\infty\quad梯度爆炸 \\
r<1\;,\qquad t-k\rightarrow\infty\quad梯度消失
\end{cases}
\] 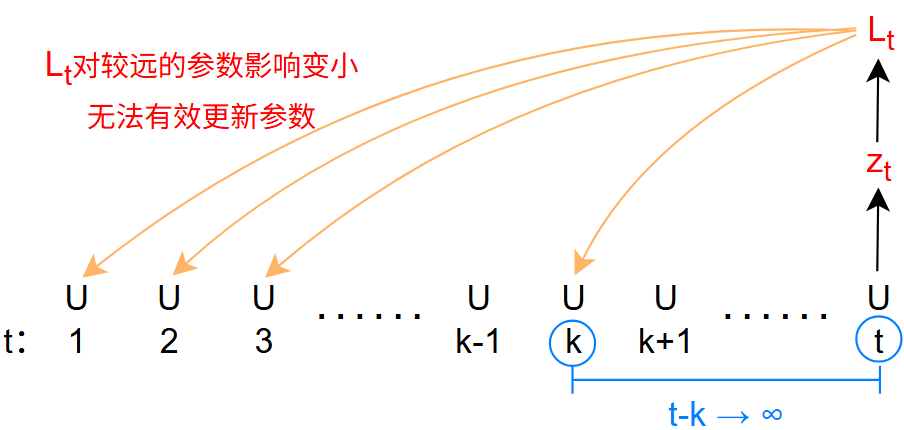
注意: 其中的梯度并没有完全消失,只是里 \(L_t\) 越远,梯度越异常 \[ \begin{gather} \frac{\partial L_t}{\partial U}\rightarrow0/\infty\qquad t-k\rightarrow\infty\qquad \times \\ \\ \frac{\partial L_t}{\partial U^k}\rightarrow0/\infty\qquad t-k\rightarrow\infty\qquad\checkmark \end{gather} \] 长程依赖问题: 由于梯度爆炸/消失,实际上只能学习到短周期的依赖关系
解决: 让 \(r=1\) 即可
解决长程依赖问题
循环神经网络在时间维度上非常深,会导致梯度消失或爆炸
改进:
- 梯度爆炸:易
- 权重衰减
- 梯度截断
- 梯度消失:改进模型
方法: \[ \begin{cases} z_t=Uh_{t-1}+Wx_t+b \\ h_t=f(z_t) \\ \delta_{t,k}=\prod_{\tau=k}^{t-1}(diag(f'(z_\tau)·U^T))·\delta_{t,t} \\ diag(f'(z_\tau)·U^T)=r=1 \end{cases} \] 要使得 \(r=1\) ,要么修改参数,要么修改模型定义
修改模型定义: \[ \begin{cases} h_t=U·h_{t-1}+Wx_t+b \\ \cancel{h_t=f(z_t)} \\ U=1 \end{cases} \] 通过以上修改能够使得 \(r\overset{\sim}{=}1\) ,也就是将循环边改为线性依赖关系: \[ \begin{gather} h_t=h_{t-1}+g(x_t;\theta) \\ or\quad h_t=h_{t-1}+g(Wx_t+b) \end{gather} \] \(h_t\) 与 \(h_{t-1}\) 之间没有非线性关系,会导致模型变差
增加非线性: \[ \begin{gather} h_t=h_{t-1}+g(x_t,h_{t-1};\theta) \\ \Leftrightarrow \quad h_t=h_{t-1}+\sigma(Uh_{t-1}+Wx_t+b) \end{gather} \] 问题: 若 \(\sigma\) 为非负函数,则 \(g(x_t,h_{t-1};\theta)\rightarrow0/1\) 饱和,导致每次增加/减少的信息很少
上述式子很像残差网络
门控的循环神经网络
门控机制:控制信息的积累速度,包括有选择地加入新信息,并有选择地遗忘之前积累的信息
基于门控的循环神经网络(Gated RNN)
- 门控循环单元:GRU
- 长短期记忆网络:LSTM
GRU(Gated Recurrent Unit)
引入门控 \(z_t\) ,控制新信息和旧信息的占比: \[ \begin{gather} h_t=h_{t-1}+g(x_t,h_{t-1};\theta) \\ \Downarrow \\ h_t=z_t\odot h_{t-1}+(1-z_t)g(x_t,h_{t-1};\theta) \end{gather} \] 其中:\(z_t\in(0,1)^d\)
\(z_t\) 被称为 更新门
: \[
z_t=\sigma(W_zx_t+U_zh_{t-1}+b_z)
\] 我们将新信息 \(g(x_t,h_{t-1};\theta)\) 定义为 \(\hat{h}\) : \[
\hat{h}=tanh(W_h·x_t+U_h·h_{t-1}+b_h)
\] 使用 Tanh 函数是因为:
- 值域有正有负,防止饱和
- 中间斜率很大,防止梯度消失
问题: 若只依赖旧信息 \(h_{t-1}\) ,则可以令 \(z_t=1\) ,但若只依赖新信息 \(x_t\) ,令 \(z_t=0\) ,\(\hat{h}\) 中仍然有 \(h_{t-1}\) ,任然受到旧信息的影响,无法实现
那么我们可以引入 \(r_t\) 单独控制
\(\hat{h}\) 中的 \(h_{t-1}\) : \[
\hat{h}=tanh(W_h·x_t+U_h·(r_t\odot h_{t-1})+b_h)
\] \(r_t\) 被称为
重置门 : \[
r_t=\sigma(W_rx_t+U_rh_{t-1}+b_r)
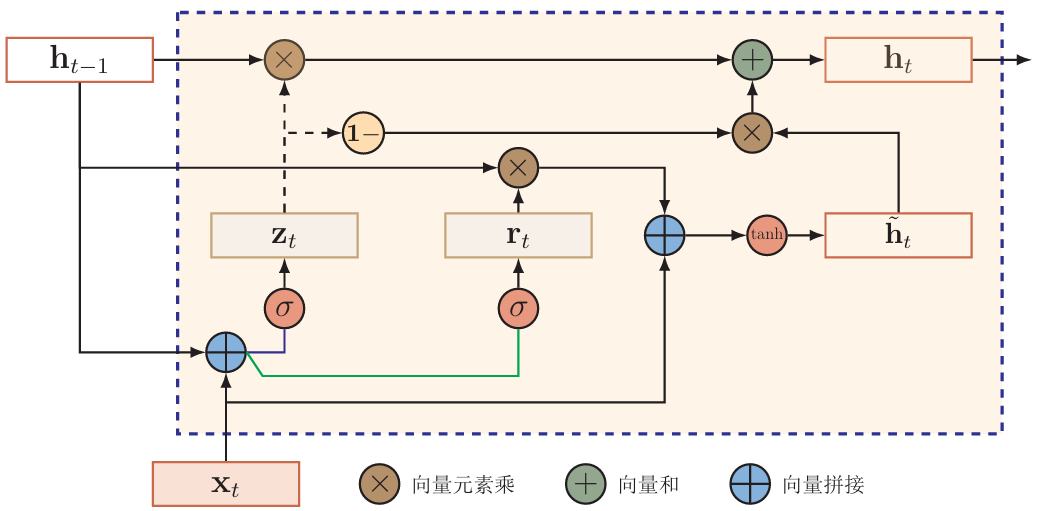
\] 所以,GRU的门控和输出为: \[
\begin{cases}
h_t=z_t\odot h_{t-1}+(1-z_t)·tanh(W_h·x_t+U_h·(r_t\odot h_{t-1})+b_h) \\
z_t=\sigma(W_zx_t+U_zh_{t-1}+b_z) \\
r_t=\sigma(W_rx_t+U_rh_{t-1}+b_r) \\
z_t,r_t\in(0,1)^d
\end{cases}
\] GRU循环单元结构:
LSTM(Long Short-Term Memory)
引入内部记忆单元 \(c_t\) ,将 \(h_t\) 释放出来去做更好的非线性,提高非线性建模能力: \[ \begin{gather} \hat{c_t}=tanh(W_cx_t+U_ch_{t-1}+b_c) \\ \\ c_t=f_t\odot c_{t-1}+i_t\odot \hat{c_t} \\ \Downarrow \\ h_t=o_t\odot tanh(c_t) \end{gather} \] 其中的 \(\hat{c_t}\) 为新信息
输入门 \(i_t\) : \[ i_t=\sigma(W_ix_t+U_ih_{t-1}+b_i) \] 遗忘门 \(f_t\) : \[ f_t=\sigma(W_fx_t+U_fh_{t-1}+b_f) \] 输出门 \(o_t\) : \[ o_t=\sigma(W_ox_t+U_oh_{t-1}+b_o) \] 这些门都是控制各部分占比,值域为 \((0,1)\)
所以,LSTM的门控和输出为: \[ \begin{cases} c_t=f_t\odot c_{t-1}+i_t\odot \hat{c_t} \\ h_t=o_t\odot tanh(c_t) \\ f_t=\sigma(W_fx_t+U_fh_{t-1}+b_f) \\ i_t=\sigma(W_ix_t+U_ih_{t-1}+b_i) \\ o_t=\sigma(W_ox_t+U_oh_{t-1}+b_o) \\ f_t,i_t,o_t\in(0,1)^d \end{cases} \] LSTM的循环单元结构:
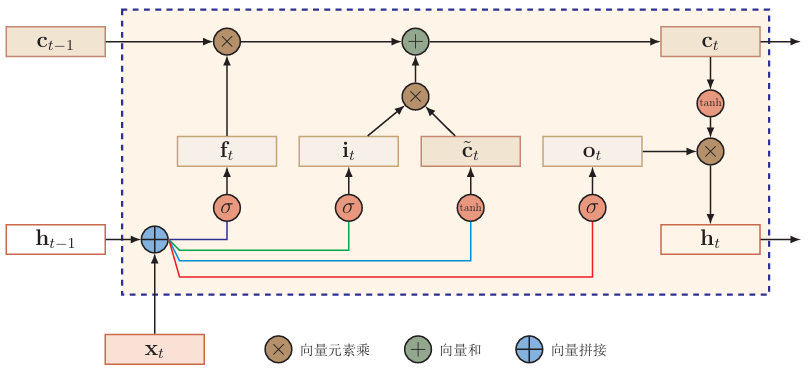
LSTM各种变体
没有遗忘门: \[ c_t=c_{t-1}+i_t\odot \hat{c_t} \] 耦合输入门和遗忘门: \[ \begin{gather} f_t=1-i_t \\ c_t=(1-i_t)\odot c_{t-1}+i_t\odot \hat{c_t} \end{gather} \] peephole连接:(不常用) \[ \begin{gather} i_t=\sigma(W_ix_t+U_ih_{t-1}+V_ic_{t-1}+b_i) \\ f_t=\sigma(W_fx_t+U_fh_{t-1}+V_fc_{t-1}+b_f) \\ o_t=\sigma(W_ox_t+U_oh_{t-1}+V_oc_{t-1}+b_o) \\ \end{gather} \]
深层循环神经网络
堆叠循环神经网络
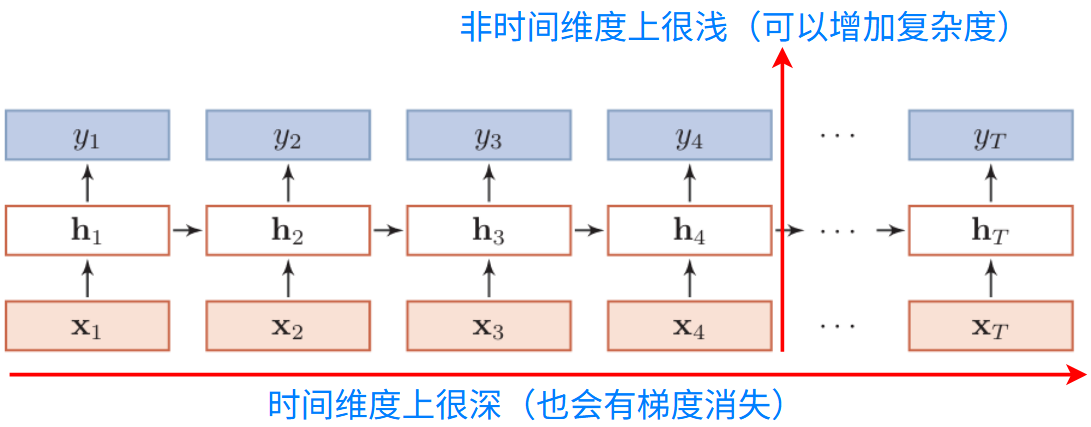
RNN在时间维度上很深,也可以在层数上堆叠:
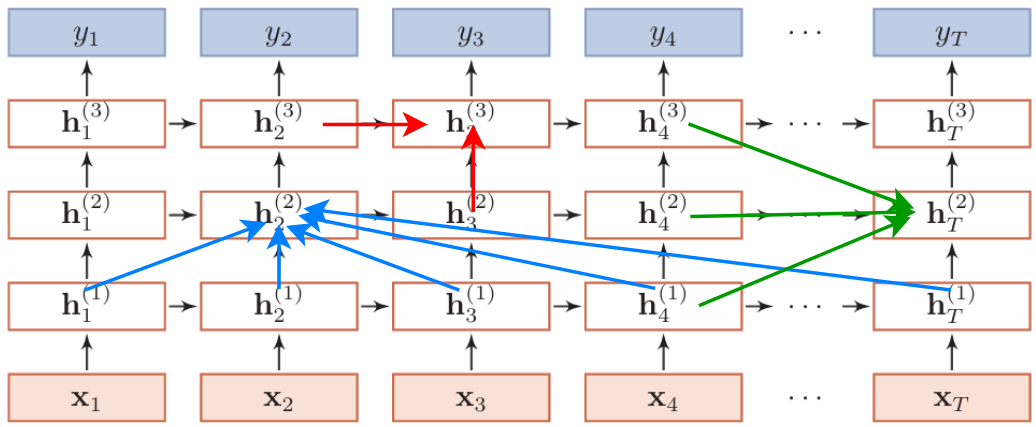
记忆加深方式:
- 同一层的前一时刻 + 同一时刻的下一层(图中红色箭头)
- 来自于下一层的所有时刻信息(图中蓝色箭头)
- 来自于上一时刻的所有信息(图中绿色箭头)
三种一般不能同时出现,太复杂
双向循环神经网络
时间顺序 + 时间逆序建模,输出既有左边信息,又有右边信息
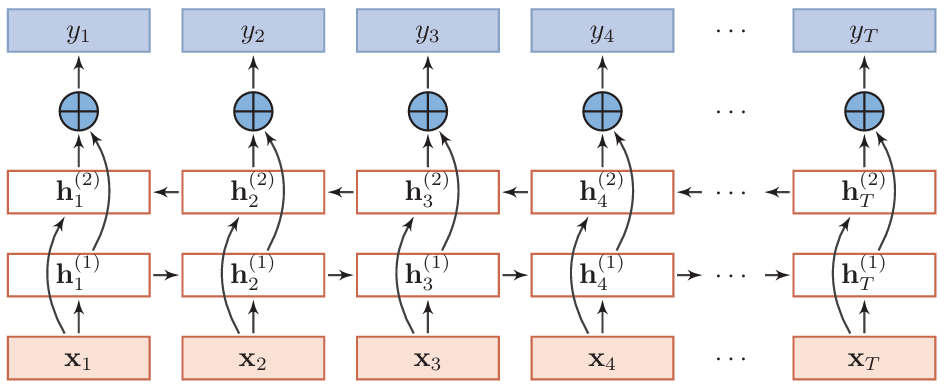
循环神经网络总结
优点:
- 引入(短期)记忆
- 图灵完备
缺点:
- 长程依赖问题
- 记忆容量问题
- 并行能力
从0了解深度学习——循环神经网络