从0了解深度学习——卷积神经网络
本文章将介绍深度学习中的卷积神经网络
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
卷积网络与全连接网络
对于全连接的前馈神经网络:
权重矩阵的参数众多:相邻的1000和10000神经元,其参数有 \(10^7\) 个
局限性:无法适配局部不变性特征
局部不变性特征:
- 自然图像中的物体都具有局部不变性特征
- 经过尺度缩放,平移,旋转等操作不影响其语义信息
- 全连接前馈神经网络很难提取这些局部不变特征
卷积神经网络(CNN)
一种前馈神经网络,受生物学上感受野(Receptive Field)的机制而提出:
- 在视觉神经系统中,一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元
卷积神经网络有三个结构上的特征:
- 局部连接
- 权重共享
- 空间或时间上的次采样(汇聚)
卷积
卷积常常用于信号处理中,用于计算信号的延迟积累
假设一个信号发生器每个时刻 \(t\) 产生一个信号 \(x_t\) ,其信息的衰减率为 \(w_k\) ,即在 \(k-1\) 个时间步长后,信息为原来的 \(w_k\) 倍
假设 \(w:\quad w_1=1\quad w_2=\frac{1}{2}\quad w_3=\frac{1}{4}\quad ...\)
时刻 \(t\) 收到的信号 \(y_t\) 为当前时刻产生的信息,和以前时刻延迟信息的叠加:
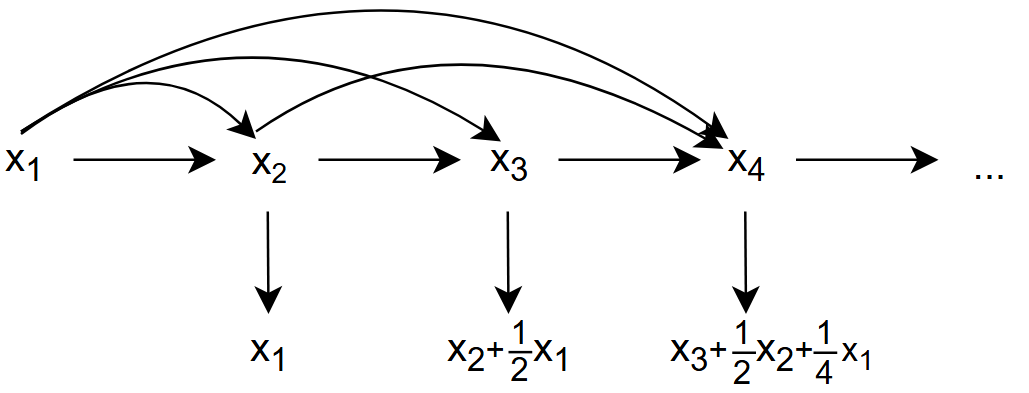 \[
\begin{gather}
y_t=x_t+\frac{1}{2}x_{t-1}+\frac{1}{4}x_{t-2} \\
=w_1x_t+w_2x_{t-1}+w_3x_{t-2} \\
=\sum_{k=1}^3w_k·x_{t-k+1}
\end{gather}
\] 我们把其中的 \(w_k\)
称为滤波器(filter) 或卷积核(convolution kernel)
\[
\begin{gather}
y_t=x_t+\frac{1}{2}x_{t-1}+\frac{1}{4}x_{t-2} \\
=w_1x_t+w_2x_{t-1}+w_3x_{t-2} \\
=\sum_{k=1}^3w_k·x_{t-k+1}
\end{gather}
\] 我们把其中的 \(w_k\)
称为滤波器(filter) 或卷积核(convolution kernel)
给定一个输入信号序列 \(x\) 和卷积核 \(w\) ,卷积的输出为: \[ y_t=\sum_{k=1}^Kw_k·x_{t-k+1} \] 信号序列 \(x\) 和卷积核 \(w\) 的卷积计算表达式为: \[ y=w\ast x\qquad (\ast表示卷积运算) \] 一般情况下卷积核的长度 \(m\) 远小于信号序列长度 \(n\) 。当卷积核 \(f_k=\frac{1}{m},1≤ k ≤m\) 时,卷积相当于信号序列的移动平均。当卷积核为 \([−1,0,1]\) ,连接边上的数字为卷积核中的权重:
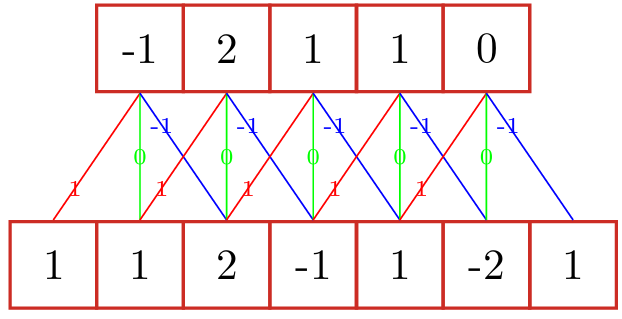
卷积的作用
- 近似微分:
当令卷积核 \(w=[\frac{1}{2},0,-\frac{1}{2}]\) 时,可以近似信号序列的一阶微分: \[ \begin{gather} \because\; y_t=\sum_{k=1}^Kw_k·x_{t-k+1} \\ \therefore\;y_t=\frac{1}{2}x_t-\frac{1}{2}x_{t-2} \\ \because\; \lim_{\epsilon\rightarrow0}\frac{f(x+\epsilon)-f(x)}{\epsilon} \\ \therefore\; y_t=\frac{1}{2}x_t-\frac{1}{2}x_{t-2}\;\Leftrightarrow\;x'(t)=\frac{x(t+1)-x(t-1)}{2} \end{gather} \] 当令卷积核 \(w=[1,-2,1]\) 时,可以近似信号序列的二阶微分: \[ \begin{gather} \because\; y_t=\sum_{k=1}^Kw_k·x_{t-k+1} \\ \therefore\;y_t=x_t-2x_{t-1}+x_{t-2} \\ \because\; x''(x)=\frac{x'(t+1)-x'(t-1)}{2} \\ \therefore\; y_t=x_t-2x_{t-1}+x_{t-2}\;\Leftrightarrow\;x''(t)=x(t+1)+x(t-1)-2x(t) \end{gather} \]
- 低通滤波/高通滤波:
当卷积核 \(w=[\frac{1}{3},\frac{1}{3},\frac{1}{3}]\) 可以检测信号序列中的低频信息
当卷积核 \(w=[1,-2,1]\) 可以检测信号序列中的高频信息
卷积扩展
引入卷积核的滑动步长 \(S\) 和零填充 \(P\)
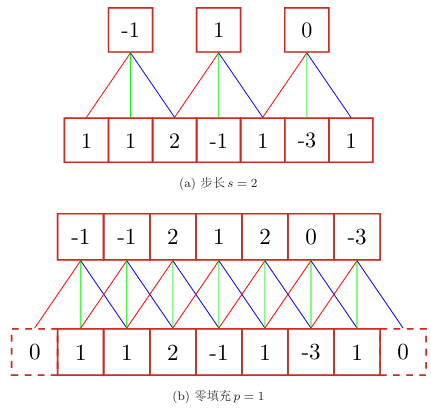
卷积类型: M:输入长度,K:卷积核长度
卷积的结果按照输出长度不同可以分为三类:
- 窄卷积:步长 stride=1,两端不补零 padding=0,输出长度:M-K+1
- 宽卷积:步长 stride=1,两端补零 padding=K-1,输出长度:M+K-1
- 等宽卷积:步长 stride=1,两端不补零 padding= \(\frac{k-1}{2}\) ,输出长度:M
在早期文献中,卷积一般默认为 窄卷积
而目前的文献中,卷积一般默认为 等宽卷积
二维卷积
在图像处理中,图像是以二维矩阵的形式输入到神经网络中,因此我们需要二维卷积
一个输入信息 \(X\) 和卷积核 \(W\) 的二维卷积定义为: \[ \begin{gather} Y=W\ast X \\ y_{ij}=\sum_{u=1}^U\sum_{v=1}^Vw_{uv}x_{i-u+1,j-v+1} \end{gather} \]
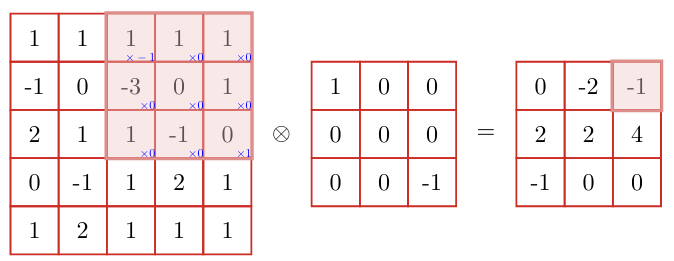
互相关
上图的卷积计算是经过翻转(旋转180度)计算的结果
而卷积目标是提取特征:也就是说翻转是不必要的
互相关
(Cross-Correlation)是一个衡量两个序列相关性的函数,通常是用滑动窗口的点积计算来实现,给定一个图像
\(X\in\mathbb{R}^{M\times N}\) 核卷积核
\(W\in\mathbb{R}^{m\times n}\) ,他们的
互相关 为: \[
y_{ij}=\sum_{u=1}^U\sum_{v=1}^Vw_{uv}x_{i+u-1,j+v-1}
\]
和之前的公式对比可以发现,互相关和卷积的区别在于卷积核仅仅是否进行翻转,因此互相关也可以称为
不翻转卷积
后续我们提到的卷积一般都是指 互相关
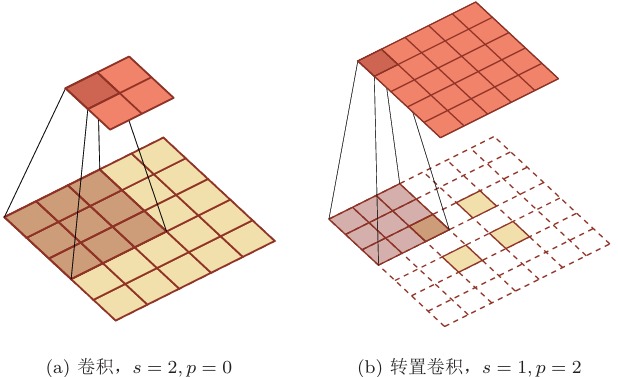
具体的不翻转卷积计算在之前的PyTorch 文章中 讲到过,这里使用文章中的图片:
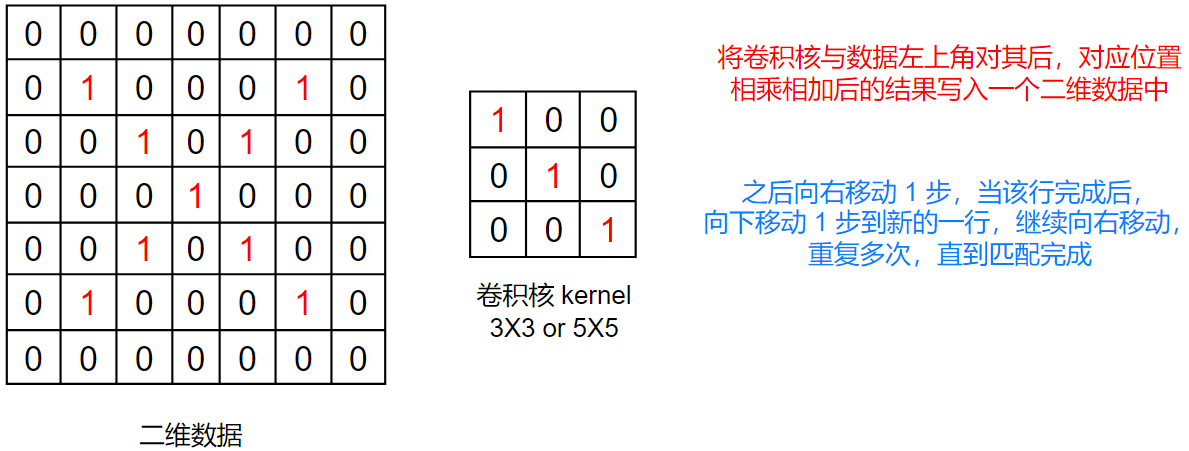
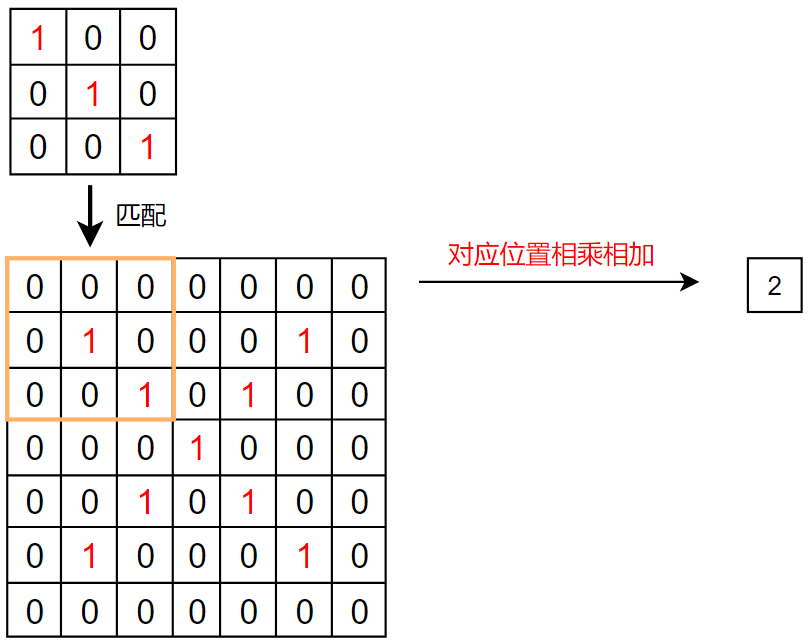
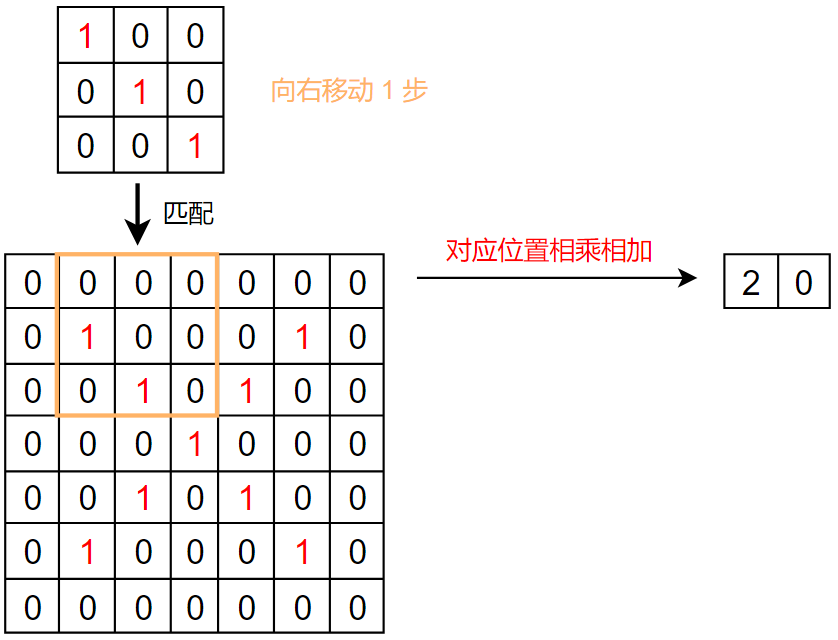
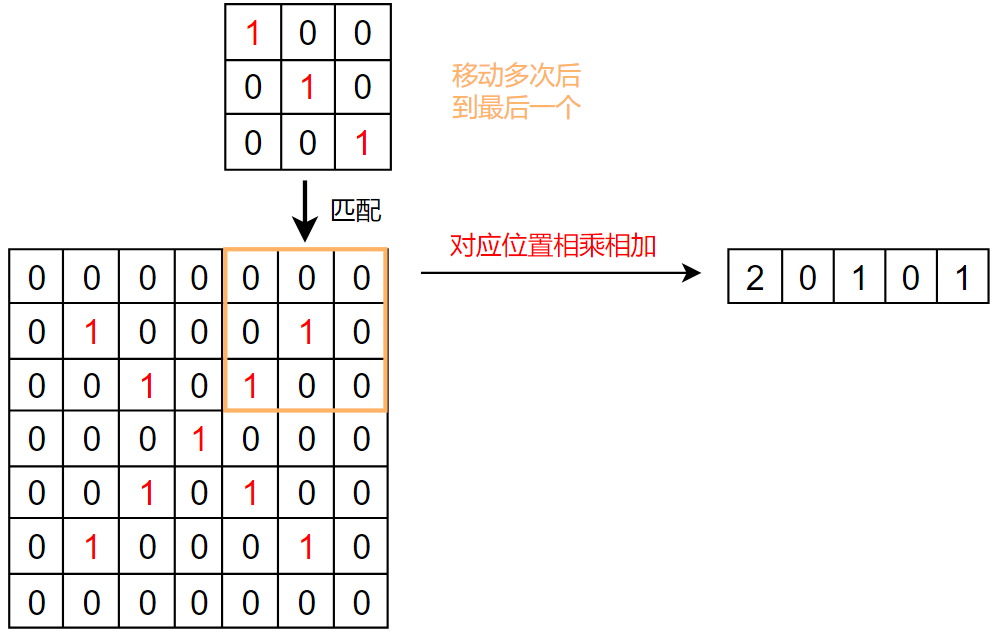
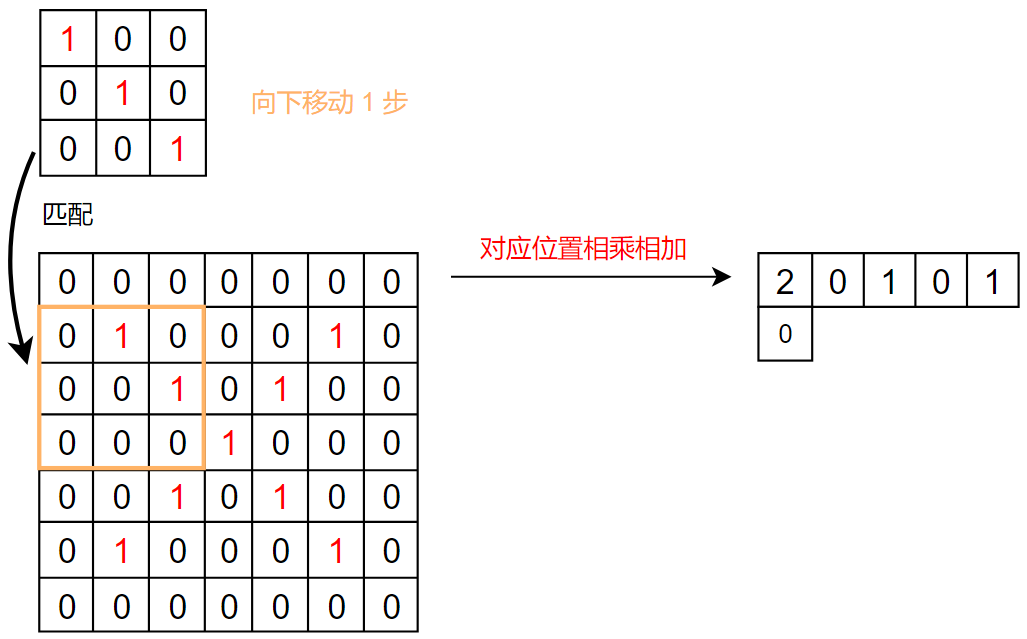
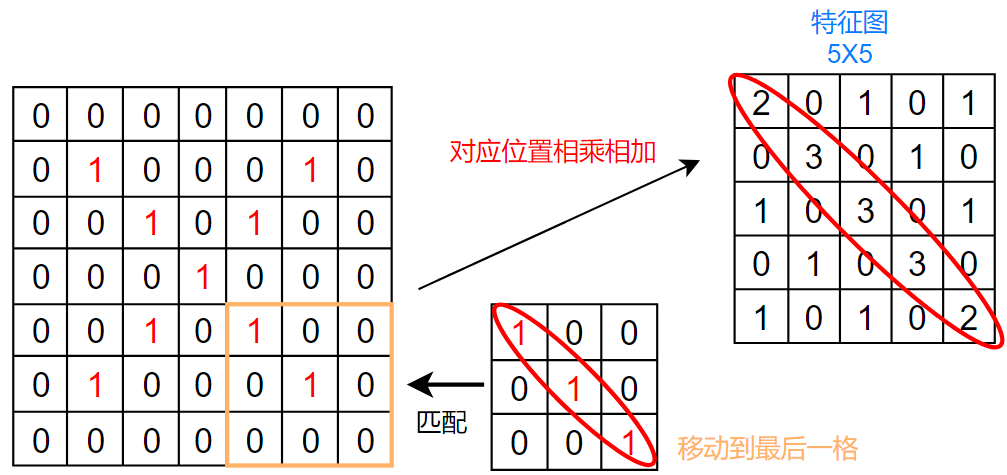
各种参数下的二维卷积:
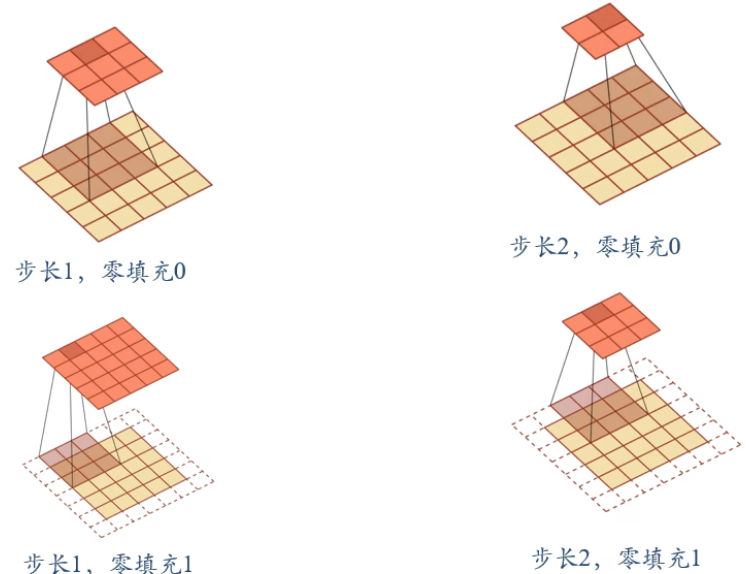
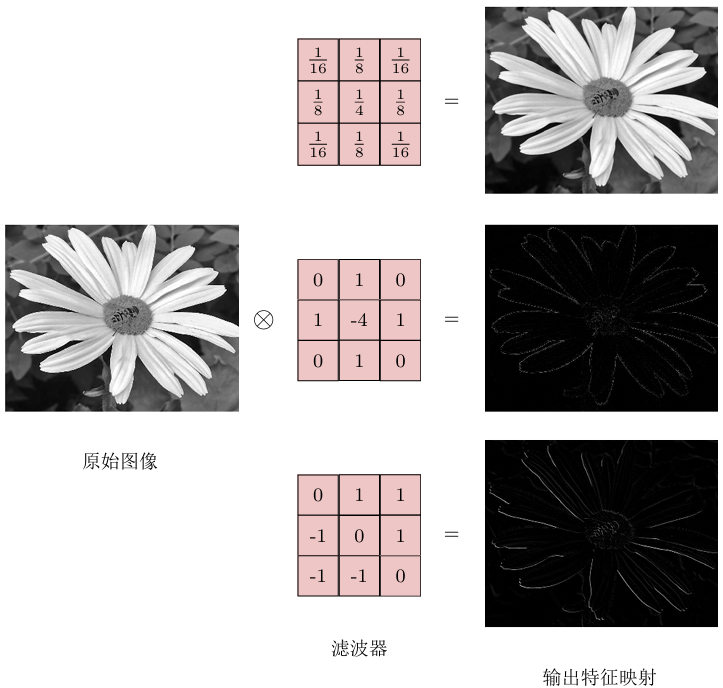
卷积作为特征提取器
在图像处理中,卷积经常作为特征提取的有效方法。一幅图像在经过卷积 操作后得到结果称为特征映射(Feature Map)。图中给出在图像处理中几种常用的滤波器(卷积核),以及其对应的特征映射。图中最上面的滤波器是常用的高斯滤波器,可以用来对图像进行平滑去噪,中间和最下面的过滤器可以用来提取边缘特征
卷积神经网络
卷积神经网络一般由卷积层、池化层和全连接层构成
用卷积层代替全连接层
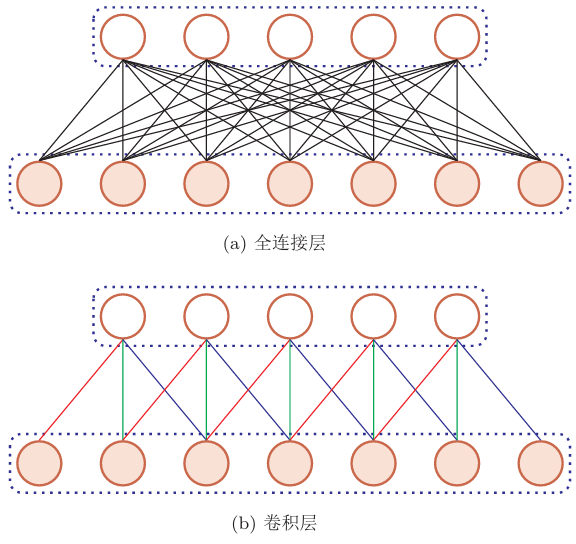
根据卷积定义,卷积层有两个很重要的性质
局部连接:在卷积层(假设是第 \(l\) 层)中的每一个神经元都只和下一层(第 \(l−1\) 层)中某个局部窗口内的神经元相连,构成一个局部连接网络。如图(b)所示, 卷积层和下一层之间的连接数大大减少,有原来的 \(n^l×n^{l−1}\) 个连接变为 \(n^l×m\) 个连接,\(m\) 为滤波器大小
权重共享:从公式之前的可以看出,作为参数的滤波器 \(w^{(l)}\) 对于第 \(l\) 层的所有的神经元都是相同的。如图(b)中,所有的同颜色连接上的权重是相同的
对于 \(l+1\) 层的神经元: \[ h^{l+1}=f(w\ast h^l+b^l) \] 其参数数量只与卷积核大小有关,与其他因素无关,根据这样的特性,卷积网络还可以应用在文本数据这样长度不一致的问题上
多卷积核
卷积作为一个特征提取器,如何提高卷积层的能力?引入多个卷积核
以二维卷积为例,若输入 \(X\in\mathbb{R}^{M\times N\times D}\) ,\(D=3\) ,卷积核尺寸 \(m\times n\) ,卷积核数量(维度) \(d=D=3\) ,其输入输出图为:
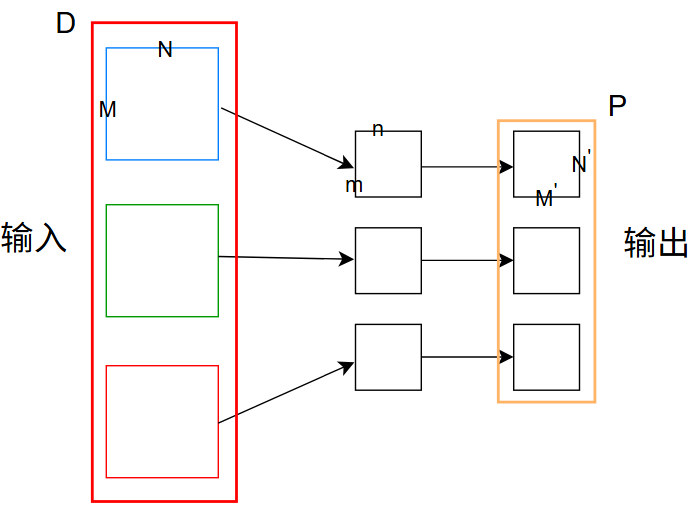
输出为 \(Y\in\mathbb{R}^{M'\times N'\times P}\) ,其中 \(P=3\)
对于二维卷积而言:
- 输入:\(D\) 个特征映射,\(M\times N\times D\)
- 卷积核数量(维度):\(d=D\)
- 输出:\(P\) 个特征映射,\(M'\times N'\times P\)
对于上图而言,还可以进行简化
将卷积核合并成三维卷积核,将输出的矩阵累加为一个全新的输出矩阵:
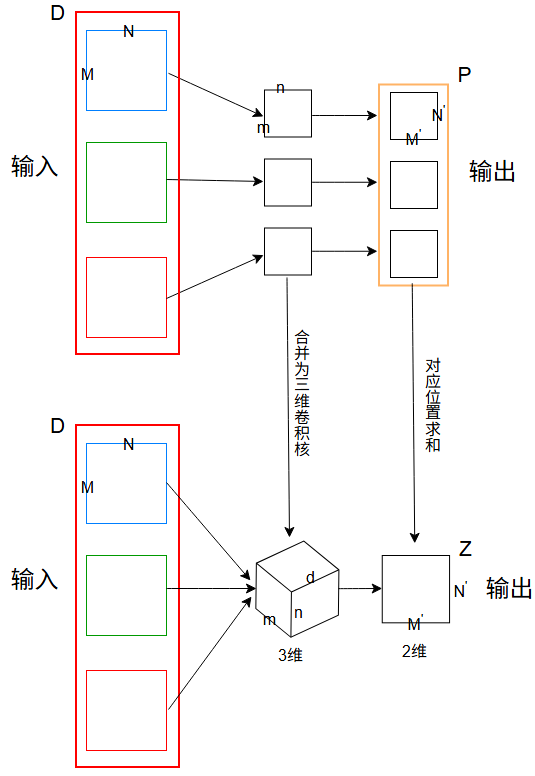
对于三维卷积且卷积核只有一个而言:
- 输入:\(D\) 个特征映射,\(M\times N\times D\)
- 卷积核维度:\(m\times n\times D\) (卷积核深度 \(D\) 与输入特征深度 \(D\) 一致)
- 输出:1个特征映射,\(M'\times N'\)
对于三维卷积且卷积核有多个情况下: 可以近似为全连接网络
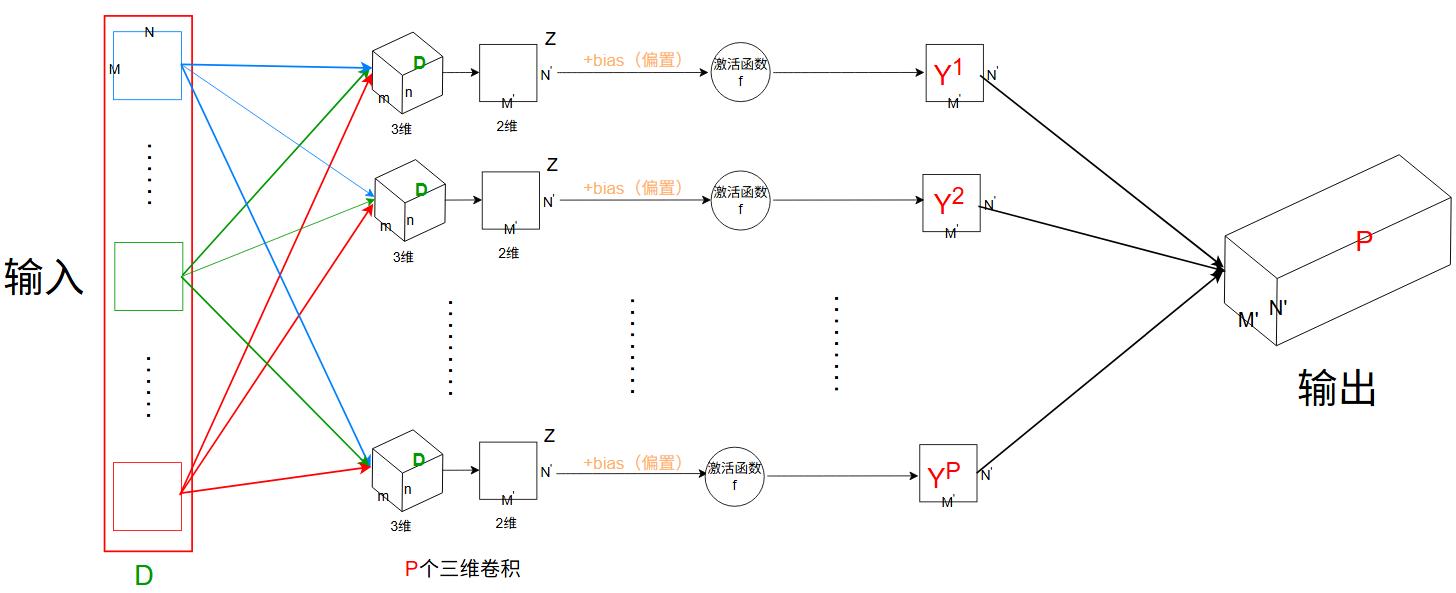
我们从上图中看到,三维的多卷积核网络,前半部分就像是全连接网络
对于三维卷积且卷积核有多个情况下:
- 输入:\(D\) 个特征映射,\(M\times N\times D\)
- 卷积核维度:\(m\times n\times D \times P\) (卷积核深度 \(D\) 与输入特征深度 \(D\) 一致)
- 输出:1个特征映射,\(M'\times N' \times P\)
我们从中可以发现以下特点:
- 单个卷积核的深度 \(D\) 等于输入的特征映射数量(深度) \(D\)
- 卷积核的数量 \(P\) 等于输出的特征深度 \(P\)
由此,我们可以得到卷积计算公式: \[ \begin{gather} Z^P=W^P\ast X+b^P=\sum_{d=1}^DW^{p,d}\ast X^d+b^P \\ Y^P=f(Z^P) \end{gather} \]
池化层/汇聚层
卷积层虽然能减少连接个数,但是每一个特征映射的神经元个数并不能显著减少(参数减少,输出数量没有显著减少)
池化层的操作和卷积一样,只不过卷积是对应位置相乘求和,而池化的操作有:
取最大值(最大池化)
取最小值(最小池化)
取平均值(平均池化)
...
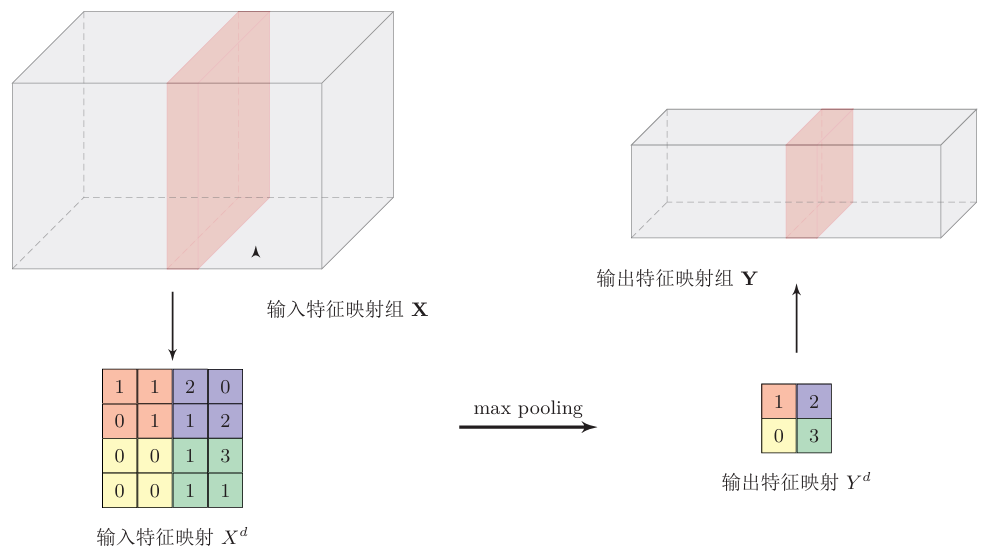
感受野
输出数据中,矩阵中每一个数据在原始输入矩阵上的映射区域大小
下图展示的是对 5X5 原始矩阵,连续使用两个 3X3 卷积所产生的图:
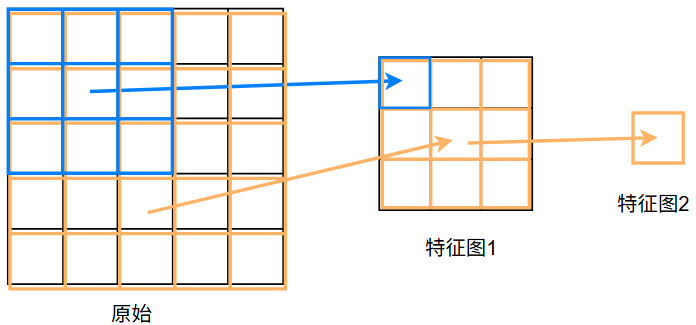
在上图中,特征图1中的蓝色 1X1 部分,他的感受野就是映射到原图,就是蓝色 3X3 部分,所以他的感受野就是 3
而特征图2中的橙色 1X1 部分,他的感受野并不是特征图的 3X3 ,因为感受野是映射在原始图像的大小,而特征图2是由特征图1通过卷积得来,而特征图1又是由原始图通过卷积得来,所以特征图2的感受野在原始图像上的映射为 5X5 ,所以他的感受野为 5
在连续的卷积过程中,感受野是越来越大的,越往后,所能感受的数据也越多,这也就解释了许多卷积神经网络中,越往后的输出图像在原图的比例越来越大:
问题: 同一个图,经过两层 3X3 和一层 5X5 卷积输出的特征图感受野都一样,都为5,说明二者的特征提取能力相同,那么该选择哪一个?
那就需要看各自的计算量
假设输入特征图宽和高均为 \(x\) ,步长为 1,偏置为0
- 两层 3X3 卷积:
每一层 3X3 卷积的参数为:9
第一层卷积在每条边的移动次数为:\(x-(k-1)\) ,其中 \(k\) 为卷积尺寸
第一层计算量为:\((x-2)^2\)
第二层卷积在每条边的移动次数为:\(x-2(k-1)\) ,其中 \(k\) 为卷积尺寸
第二层计算量为:\((x-4)^2\)
那么总计算量为:\(9(x-2)^2+9(x-4)^2=18x^2-108x+180\)
- 一层 5X5 卷积:
每一层 5X5 卷积的参数为:25
第一层卷积在每条边的移动次数为:\(x-(k-1)\) ,其中 \(k\) 为卷积尺寸
第一层计算量为:\((x-4)^2\)
总计算量为:\(25(x-4)^2=25x^2-200x+400\)
对比二者,在 \(x>10\) 时,两层 3X3 卷积的计算量更小
典型的卷积网络结构
一个典型的卷积网络结构是由:卷积层、池化层、全连接层交叉堆叠而成
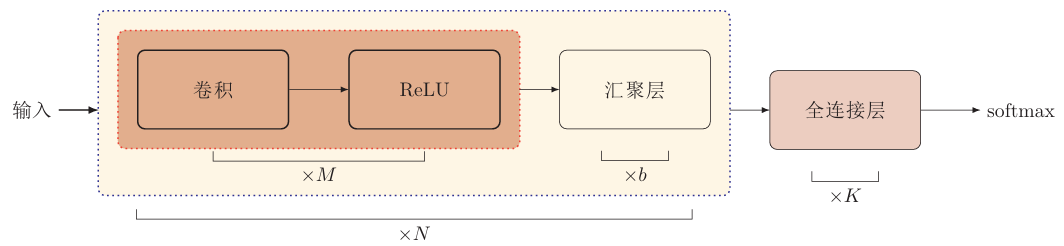
一个卷积块为连续的 \(M\) 个卷积层和 \(b\) 个池化层( \(M\) 常为2~5,\(b\) 常为 0 or 1)一个卷积网络中可以堆叠 \(N\) 个连续的卷积块,然后接着 \(k\) 个全连接层( \(N\) 的取值区间较大,如:1~100,\(k\) 为 0~2)
卷积网络也趋向于:
- 小卷积、大深度
- 全卷积(没有池化,将卷积步长设置为卷积尺寸来代替池化)
其他卷积类型
空洞卷积
如何增加输出单位的感受野
- 增加卷积核的大小
- 增加层数来实现
- 在卷积之间进行池化操作(欠采样,会丢失数据)
空洞卷积:
通过给卷积核插入“空洞”来变相地增加其大小
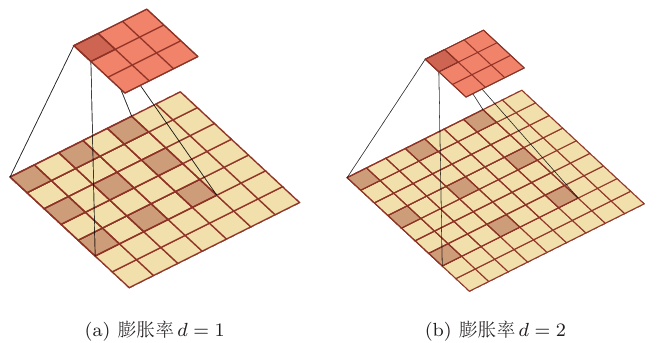
上图中,使用空洞卷积,将感受野从5变成了7
微步卷积
低维特征映射到高维特征
当卷积步长大于等于2时,从输入到输出,数据越来越小:
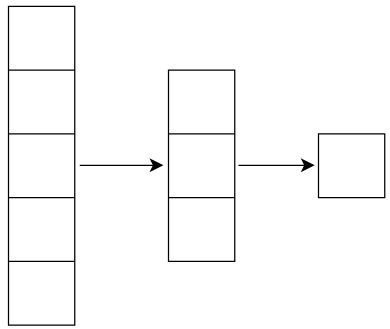
将其逆过来就是放大过程,那么要将步长设置为 \(\frac{1}{2}\) 吗?
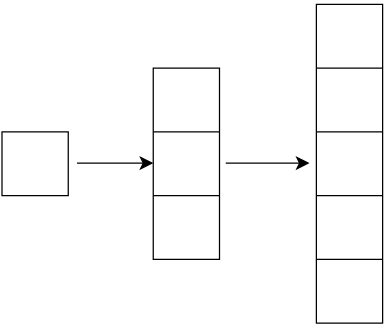
就是通过设置原数据的数据间间隔和填充即可实现
经典神经网络
LeNet-5
LeNet-5是一个非常成功的神经网络模型,基于其手写数字识别系统,在90年代被美国很多银行使用,用来识别支票上的手写数字
其结构一共有7层
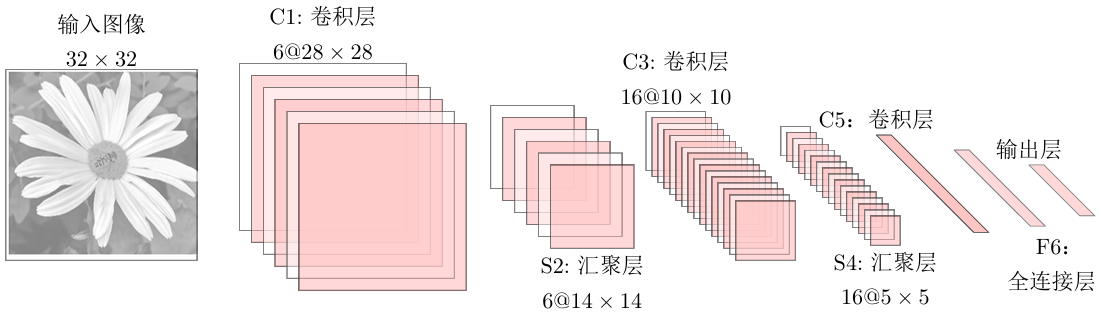
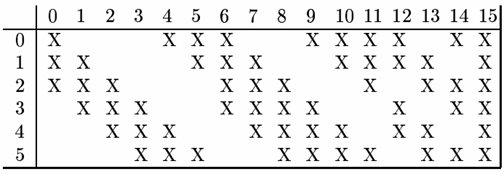
其中 S2 层到 C3 层使用连接表对其进行映射:
在当时卷积在图像处理方面被很多统计机器学习替代,直到 Large Scale Visual Recognition Challenge 比赛出现:
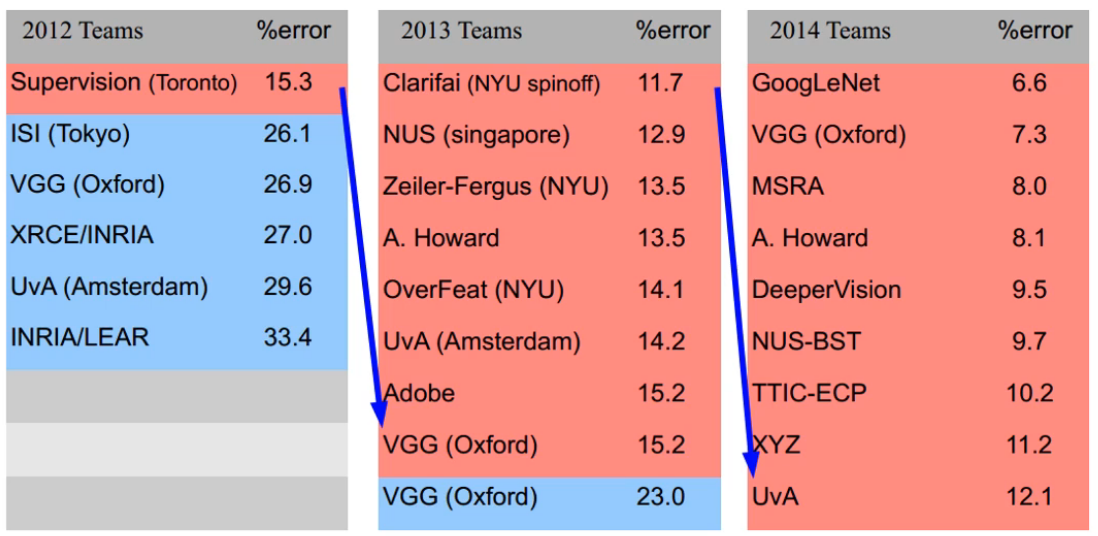
上图中,蓝色为非卷积网络,红色为卷积网络
最后该比赛在2015年由残差网络终结
可见卷积网络在特征提取和图像处理方面的优势
AlexNet
这是第一个现代深度卷积网络模型,首次使用了很多现代深度卷积网络的一些技术方法:
- 使用GPU进行并行训练
- 采用 ReLu 作为非线性激活函数
- 采用 Dropout 防止过拟合
- 使用数据增强
网络使用了5个卷积层、3个池化层和3个全连接层
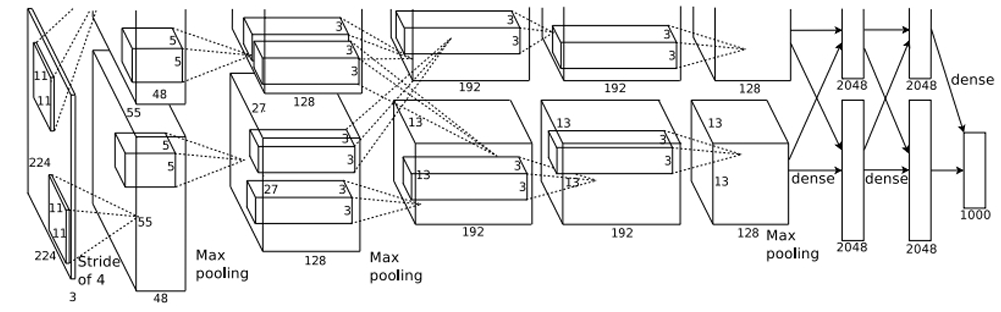
上图中分成两部分是由于当时该作者的GPU显存不足,将其分布到两块显卡上进行学习,现在很少出现这样的情况
Inception网络
在卷积网络中,如何设置卷积层的卷积核大小是一个十分关键的问题
Inception V1模块:
- 在Inception网络中,一个卷积层包含多个不同大小的卷积操作,称为Inception模块
- Inception模块同时使用 1x1、3x3、5x5等不同大小的卷积核,并将得到的特征映射在深度上拼接(堆叠)起来作为输出特征映射
1x1卷积可以看作在通道/深度维度上的特征融合
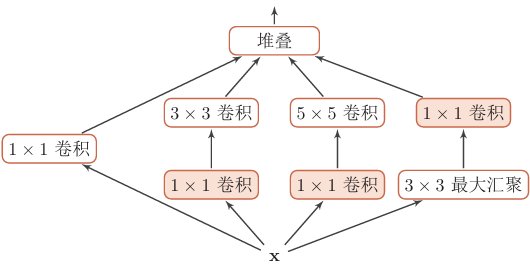
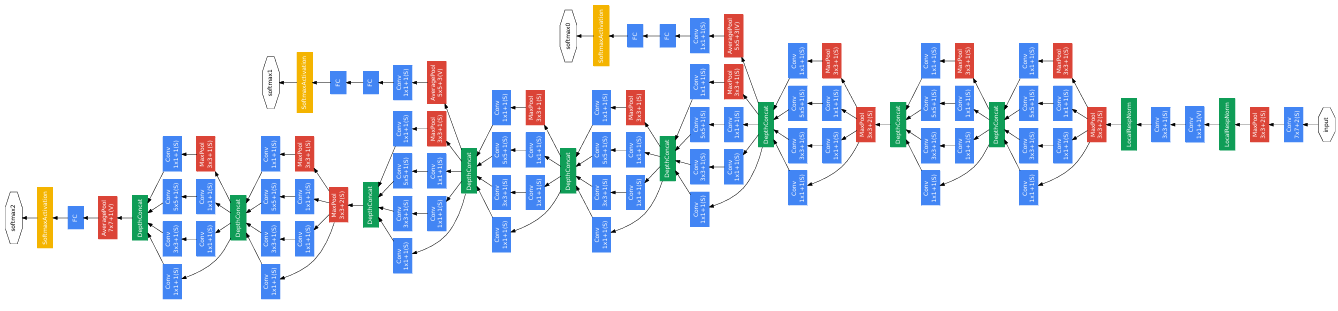
GoogLeNet由9个Inceptionv1模块和5个汇聚层以及其它一些卷积层和全连接层构成,总共为22层网络,如图所示。为了解决梯度消失问题,GoogLeNet 在网络中间层引入两个辅助分类器来加强监督信息
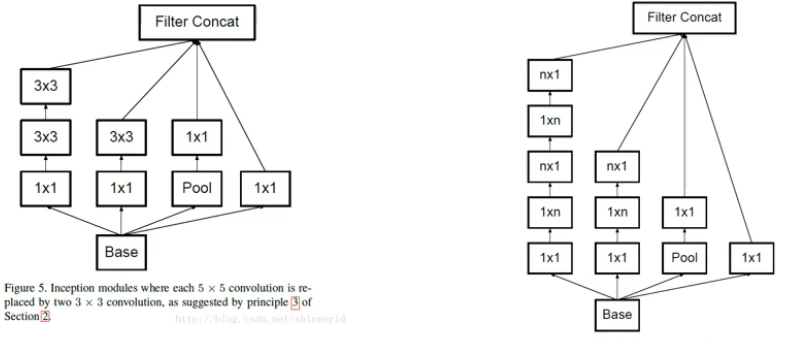
Inception V3模块:
用多层的小卷积核来替换大的卷积核,以减少计算量和参数量
- 用两层 3x3 的卷积来替换 V1 中的 5x5 的卷积
- 用连续的 nx1 和 1xn 来代替 nxn 的卷积
残差网络
残差网络是通过给非线性的卷积层增加 直连边 (shortcut
connection)的方式来提高信息的传播效率
假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的卷积层)\(f(x,\theta)\) 去逼近一个目标函数 \(h(x)\)
将目标函数拆成两部分:恒等函数和残差函数 \[ \begin{gather} h(x)=x+(h(x)-x) \\ x:\;恒等函数 \\ (h(x)-x):\;f(x,\theta) \end{gather} \] 当 \(h(x)=x\) 为恒等函数时,非线性单元(卷积网络)很难去拟合
故将目标 \(h(x)\) 分为恒等部分 \(x\) 和其与 \(h(x)\) 的拟合差距 \(h(x)-x\) 作为 \(f(x)\) 让非线性单元去拟合 \[ h(x)=x+f(x,\theta) \]
残差单元
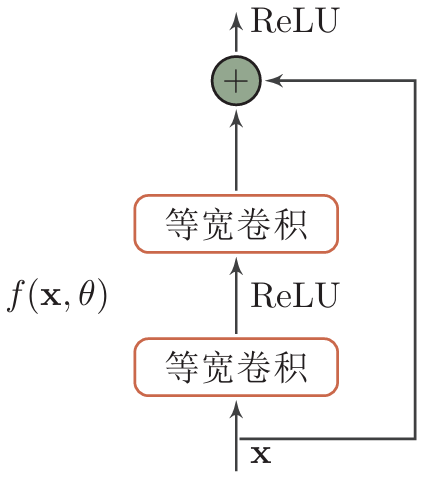
非线性单元内的网络可以自定义
由于反向传播算法,参数的更新必然需要连乘,而残差网络中: \[ \begin{gather} \because\; h(x)=x+f(x,\theta) \\ \\ \therefore\; \frac{\partial h(x)}{\partial x}=1+\frac{\partial f(x,\theta)}{\partial x} \end{gather} \] 梯度为 1 加上非线性单元的梯度,可以避免太深的深度引起梯度过小导致的梯度消失问题
根据残差网络的特性,使其能够堆叠很多层,例如 ResNet为152层
而之后的神经网络若要堆叠很深的层数,即使不是残差网络,都要和残差网络一样,使用直连边来避免梯度消失现象
其已然成为深层网络必不可少的技术
从0了解深度学习——卷积神经网络