背景介绍
1912 年 4 月 15 日,在她的处女航中,被广泛认为“永不沉没”的 RMS
泰坦尼克号在与冰山相撞后沉没。不幸的是,船上的每个人都没有足够的救生艇,导致
1502 名乘客和船员中有 2224 人死亡。
虽然生存下来有一些运气因素,但似乎某些群体比其他人更有可能生存下来。
要求构建一个预测模型,使用乘客数据(即姓名、年龄、性别、社会经济阶层等)回答“什么样的人更有可能生存”这个问题。
加载数据
导入需要的包
1 2 3 4 5 6 7 import warningswarnings.filterwarnings('ignore' ) import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set (style='white' , context='notebook' , palette='muted' )
加载数据
1 2 train = pd.read_csv('.../train.csv' ) test = pd.read_csv('.../test.csv' )
数据探索
查看数据整体情况
1 2 3 4 5 display(train.shape, test.shape) (891 , 12 ) (418 , 11 )
说明数据集中,训练集有891个数据,12个特征;测试集有418个数据,11个特征
测试集中少的一个特征就是我们需要预测的生死情况
查看数据的前5条数据
1 display(train.head(), test.head())
发现有以下特征:
PassengerId:游客id
Survived:是否存活(测试集无)
Pclass:社会阶层
Name:姓名,结构为:XXX, 头衔. XXX
Sex:性别(male or female)
Age:年龄
SibSp:兄弟姐妹及配偶的数量
Parch:父母孩子数量
Ticket:票号
Fare:船票价格
Cabin:舱位号
Embarked:登船港口
将训练集和测试集合并,方便数据分析
1 full = train.append(test, ignore_index=True )
查看数据统计学特征
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 输出 PassengerId Survived Pclass Age SibSp \ count 1309.000000 891.000000 1309.000000 1046.000000 1309.000000 mean 655.000000 0.383838 2.294882 29.881138 0.498854 std 378.020061 0.486592 0.837836 14.413493 1.041658 min 1.000000 0.000000 1.000000 0.170000 0.000000 25% 328.000000 0.000000 2.000000 21.000000 0.000000 50% 655.000000 0.000000 3.000000 28.000000 0.000000 75% 982.000000 1.000000 3.000000 39.000000 1.000000 max 1309.000000 1.000000 3.000000 80.000000 8.000000 Parch Fare count 1309.000000 1308.000000 mean 0.385027 33.295479 std 0.865560 51.758668 min 0.000000 0.000000 25% 0.000000 7.895800 50% 0.000000 14.454200 75% 0.000000 31.275000 max 9.000000 512.329200
根据以上输出,数据中除了有缺失值外,没有异常情况(异常值等)
查看数据信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 输出 <class 'pandas.core.frame.DataFrame'> RangeIndex: 1309 entries, 0 to 1308 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 1309 non-null int64 1 Survived 891 non-null float64 2 Pclass 1309 non-null int64 3 Name 1309 non-null object 4 Sex 1309 non-null object 5 Age 1046 non-null float64 6 SibSp 1309 non-null int64 7 Parch 1309 non-null int64 8 Ticket 1309 non-null object 9 Fare 1308 non-null float64 10 Cabin 295 non-null object 11 Embarked 1307 non-null object dtypes: float64(3), int64(4), object(5) memory usage: 122.8+ KB
通过查看数据,总的数据量为1309条,其中存在缺失数据的特征为:Age、Fare、Cabin
同时也可查看数据类型如上所示,所有的object类型最终都要转为能够处理的数字类型
特征与标签的关系
港口与生存的关系
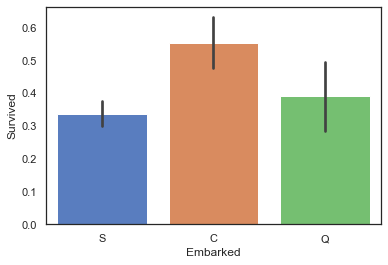
1 sns.barplot(data=train, x='Embarked' , y='Survived' )
我们发现各个港口的存活率都不一样,其中的C港口存活率最高,其中有什么奥妙还需要继续挖掘
查看各个港口登船旅客的存活率
1 2 3 4 SoE_num = train.groupby('Embarked' )['Survived' ].value_counts() SoE_present = SoE_num / SoE_num.sum (level=0 ) SoE = pd.merge(SoE_num, SoE_present, left_index=True , right_index=True , suffixes=('_num' , '_present' )) display(SoE)
1 2 3 4 5 6 7 8 9 # 输出 Survived_num Survived_present Embarked Survived C 1 93 0.553571 0 75 0.446429 Q 0 47 0.610390 1 30 0.389610 S 0 427 0.663043 1 217 0.336957
发现在C港口登船的旅客数量较少,且存活率最高,在S港口登船的旅客最多,但存活率最低
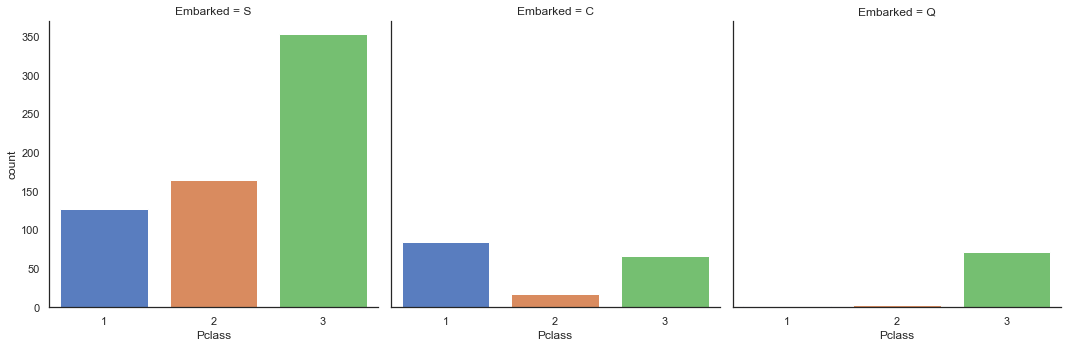
可以猜测到C港口登船的旅客中社会地位高的贵族占比最高,而S港口平民占比最高
各个港口登船旅客的社会地位
1 sns.catplot('Pclass' , col='Embarked' , data=train, kind='count' )
由上图可知,之前的猜想得到验证
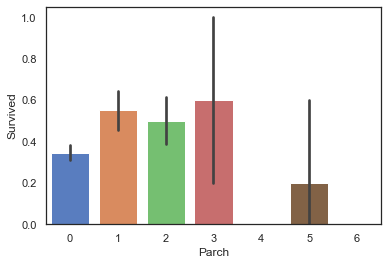
兄弟姐妹数量与生存的关系
1 sns.barplot(data=train, x='Parch' , y='Survived' )
从图中看出没有兄弟姐妹的存活率比有兄弟姐妹的低,因为可以互相帮助,而有太多的兄弟姐妹往往会成为存活路上的累赘,生存率明显更低
有兄弟姐妹且数量合适将会提高存活率
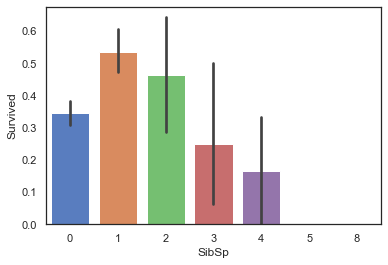
子女数量与生存的关系
不出所料,这也将满足上述关系
1 sns.barplot(data=train, x='SibSp' , y='Survived' )
有子女,且数量合适会提高存活率
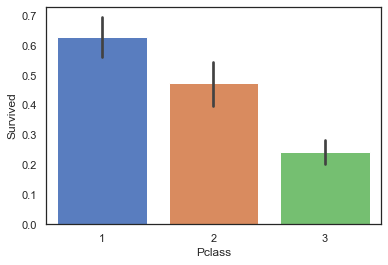
社会地位与生存的关系
1 sns.barplot(data=train, x='SibSp' , y='Survived' )
社会地位越高,存活的概率也越高,因为社会地位高的在事故发生时会受到更多的帮助与保护
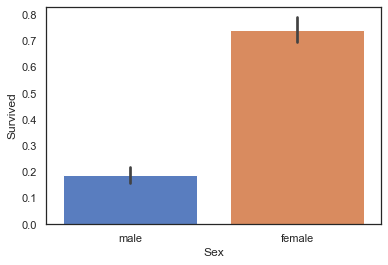
性别与生存的关系
1 sns.barplot(data=train, x='Sex' , y='Survived' )
从图中发现,女性存活的概率远远大于男性,可能在事故发生时,多数男性会帮助女性
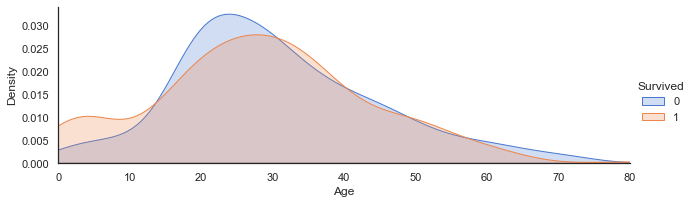
年龄与生存的关系
1 2 3 4 fareFacet = sns.FacetGrid(train, hue='Survived' , aspect=3 ) fareFacet.map (sns.kdeplot, 'Age' , shade='True' ) fareFacet.set (xlim=(0 , 80 )) fareFacet.add_legend()
从图中看出在大约14岁以下时,存活率高于死亡率,说明人们会对儿童伸出援手
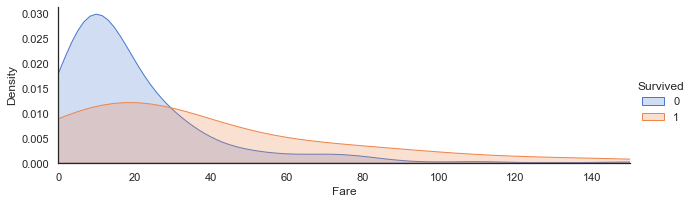
票价与生存的关系
1 2 3 4 fareFacet = sns.FacetGrid(train, hue='Survived' , aspect=3 ) fareFacet.map (sns.kdeplot, 'Fare' , shade='True' ) fareFacet.set (xlim=(0 , 150 )) fareFacet.add_legend()
从图中看出,在票价大于30时,存活率开始高于死亡率,说明票价越高所受到的服务或者舱位越好,从而在灾难发生时有更多的时间和资源
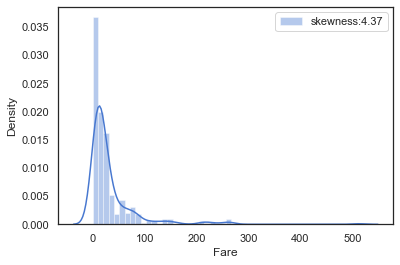
票价分布
1 2 farePlot = sns.distplot(full['Fare' ][full['Fare' ].notnull()],label='skewness:%.2f' %(full['Fare' ].skew())) farePlot.legend(loc='best' )
我们发现票价分布极度不平均,而那些高出均值的部分,对模型的预测会有影响,我们需要让其分布更加居中,呈现一个正态分布
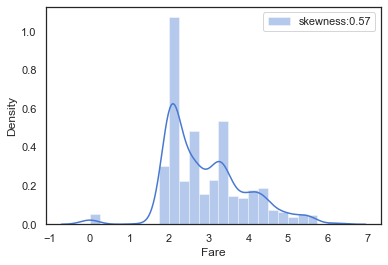
对于不均均的正态分布,我们可以对数据使用log,使其符合正态分布
1 2 3 full['Fare' ] = full['Fare' ].map (lambda x: np.log(x) if x > 0 else x) farePlot = sns.distplot(full['Fare' ][full['Fare' ].notnull()],label='skewness:%.2f' %(full['Fare' ].skew())) farePlot.legend(loc='best' )
数据预处理
数据清洗
在之前的数据探索中,我们知道Age、Fare、Cabin、Embarked存在缺失值,我们需要将缺失值填充
填充Cabin
由于舱位属于字符串,且缺失值过多,占总数据的80%左右,我们统一填充'Unknow'的首字母
1 2 full['Cabin' ] = full['Cabin' ].fillna('U' ) display(full['Cabin' ].head())
1 2 3 4 5 6 7 # 输出 0 U 1 C85 2 U 3 C123 4 U Name: Cabin, dtype: object
填充Embarked
对于登船港口,由于S港口的基数最大,而缺失的数值很大概率也是S港
1 2 full.groupby('Embarked' ).size() full['Embarked' ] = full['Embarked' ].fillna('S' )
填充Fare
由于Fare的缺失值只有一个,我们可以根据缺失数据旅客的其他信息,筛选出与其特征相近的旅客,对他们取票价的平均值作为缺失数据
而这位旅客的其他信息为:
Pclass:3
Cabin:U
Embarked:S
1 full['Fare' ] = full['Fare' ].fillna(full[(full['Pclass' ] == 3 ) & (full['Cabin' ] == 'U' ) & (full['Embarked' ] == 'S' )]['Fare' ].mean())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 输出 <class 'pandas.core.frame.DataFrame'> RangeIndex: 1309 entries, 0 to 1308 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 1309 non-null int64 1 Survived 891 non-null float64 2 Pclass 1309 non-null int64 3 Name 1309 non-null object 4 Sex 1309 non-null object 5 Age 1046 non-null float64 6 SibSp 1309 non-null int64 7 Parch 1309 non-null int64 8 Ticket 1309 non-null object 9 Fare 1309 non-null float64 10 Cabin 1309 non-null object 11 Embarked 1309 non-null object dtypes: float64(3), int64(4), object(5) memory usage: 122.8+ KB
四个缺失数据中的其中三个已经填充,而剩下一个年龄,由于年龄缺失数据占总数据的20%,正好可以作为一个新的模型预测问题,在之后使用模型预测其年龄,而不使用统计学方法填充
特征工程
特征工程对于模型的预测十分重要,甚至大于模型本身,这在之前的机器学习基础中讲到过,一个好的模型决定了预测的下限,而一个好的特征工程决定了模型预测的上限
名称与头衔映射
在之前的数据探索阶段,数据中'Name'特征的结构为:XXX, 头衔. XXX
而头衔在一定程度上代表着这个旅客的社会地位,或者其他信息
通过查询历史资料,发现头衔大致可以对应以下身份:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 'Mr' : 'Mr' ,'Mlle' : 'Miss' ,'Miss' : 'Miss' ,'Master' : 'Master' ,'Jonkheer' : 'Master' ,'Mme' : 'Mrs' ,'Ms' : 'Mrs' ,'Mrs' : 'Mrs' ,'Don' : 'Royalty' ,'Sir' : 'Royalty' ,'the Countess' : 'Royalty' ,'Dona' : 'Royalty' ,'Lady' : 'Royalty' ,'Capt' : 'Officer' ,'Col' : 'Officer' ,'Major' : 'Officer' ,'Dr' : 'Officer' ,'Rev' : 'Officer'
一共六类:
Mr:先生
Miss:女生
Mrs:夫人
Master:船长/硕士
Officer:官员
Royalty:皇室
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 full['Title' ] = full['Name' ].map (lambda x: x.split(',' )[1 ].split('.' )[0 ].strip()) TitleDict={} TitleDict['Mr' ]='Mr' TitleDict['Mlle' ]='Miss' TitleDict['Miss' ]='Miss' TitleDict['Master' ]='Master' TitleDict['Jonkheer' ]='Master' TitleDict['Mme' ]='Mrs' TitleDict['Ms' ]='Mrs' TitleDict['Mrs' ]='Mrs' TitleDict['Don' ]='Royalty' TitleDict['Sir' ]='Royalty' TitleDict['the Countess' ]='Royalty' TitleDict['Dona' ]='Royalty' TitleDict['Lady' ]='Royalty' TitleDict['Capt' ]='Officer' TitleDict['Col' ]='Officer' TitleDict['Major' ]='Officer' TitleDict['Dr' ]='Officer' TitleDict['Rev' ]='Officer' full['Title' ] = full['Title' ].map (TitleDict) full['Title' ].value_counts()
1 2 3 4 5 6 7 8 # 输出 Mr 757 Miss 262 Mrs 200 Master 62 Officer 23 Royalty 5 Name: Title, dtype: int64
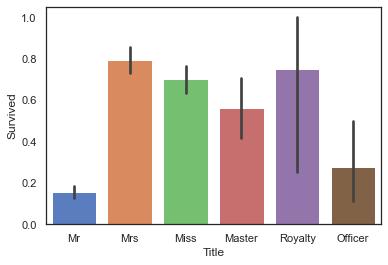
查看各头衔的生存情况
1 sns.barplot(data=full, x='Title' , y='Survived' )
我们发现先生和官员的生存率明显低于其他,推测这两类人群具有牺牲精神,选择牺牲自己帮助他人
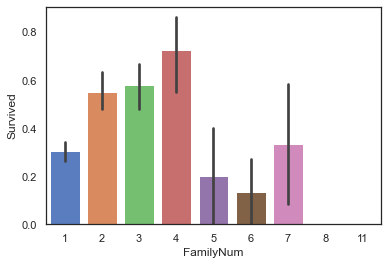
家庭合并
特征'Parch'和'SibSp'都是家庭成员,将其分开讨论和合并讨论没有区别,在灾难发生时所表现的行为一致,将其合并来看方便减少特征数量,防止过拟合,减少计算量
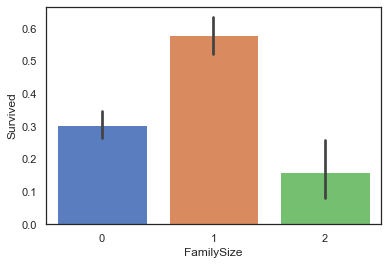
1 2 full['FamilyNum' ] = full['Parch' ] + full['SibSp' ] + 1 sns.barplot(data = full, x='FamilyNum' , y='Survived' )
图中发现有家庭成员且数量合适的情况下,存活率更高
我们可以将其分为三组
无家庭成员:0
有家庭成员且人数适中:1
有家庭成员且人数过多:2
1 2 3 4 5 6 7 8 9 10 11 def familysize (familynum ): if familynum == 1 : return 0 elif (familynum >= 2 ) & (familynum <= 4 ): return 1 else : return 2 full['FamilySize' ] = full['FamilyNum' ].map (familysize) sns.barplot(data=full, x='FamilySize' , y='Survived' )
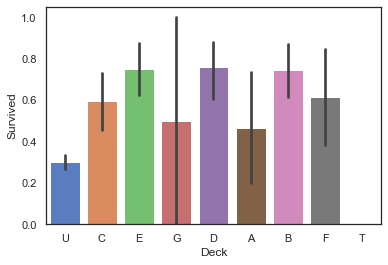
船仓类型分析
根据Cabin特征的数据看,船舱类型为舱号的首字母,因此取出首字母组成船舱号
1 2 full['Deck' ] = full['Cabin' ].map (lambda x: x[0 ]) sns.barplot(data=full, x='Deck' , y='Survived' )
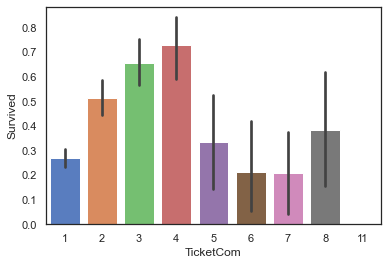
共号票分析
在船票售卖时,有套餐制,即一张票可以让多个人上船,而共用一张票的那些人,大概率应该认识,或者是非家庭成员的亲密关系
1 2 full['TicketCom' ] = full['Ticket' ].map (full['Ticket' ].value_counts()) sns.barplot(data=full, x='TicketCom' , y='Survived' )
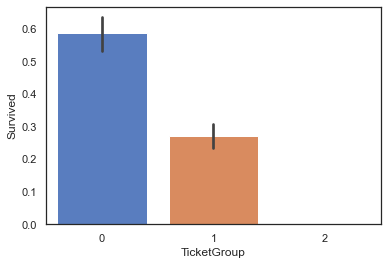
将这些数据按照家庭合并的方法,根据存活率进行区分
1 2 3 4 5 6 7 8 9 10 def ticketsize (ticketcom ): if (ticketcom >= 2 ) & (ticketcom <= 4 ): return 0 elif (ticketcom == 1 ) | (ticketcom >= 5 ) & (ticketcom <= 8 ): return 1 else : return 2 full['TicketGroup' ] = full['TicketCom' ].map (ticketsize) sns.barplot(data=full, x='TicketGroup' , y='Survived' )
对Age特征进行填充
对于结构化数据,且数据中有离散数据,决策树的效果很好,这里我们使用随机森林进行Age特征填充
分析其他特征对于Age特征的相关性系数
1 2 full[full['Age' ].notnull()].corr()
输出各特征对于Age的相关度,选出其中最相关的几个特征:Age, Pclass,
SibSp, Parch, FamilyNum, TicketCom
还有字符串特征 Title 对于字符串需要使用独热码进行编码
1 2 3 4 5 agePre = full[['Age' , 'Pclass' , 'SibSp' , 'Parch' , 'FamilyNum' , 'TicketCom' , 'Title' ]] agePre = pd.get_dummies(agePre) ageCorrDf = agePre.corr() ageCorrDf['Age' ].sort_values()
开始训练随机森林
1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn.ensemble import RandomForestRegressorageKnown = agePre[agePre['Age' ].notnull()] ageUnknown = agePre[agePre['Age' ].isnull()] ageKnown_X = ageKnown.drop(['Age' ], axis=1 ) ageKnown_Y = ageKnown['Age' ] ageUnknown_X = ageUnknown.drop(['Age' ], axis=1 ) rfr=RandomForestRegressor(random_state=None ,n_estimators=500 ,n_jobs=-1 ) rfr.fit(ageKnown_X, ageKnown_Y)
预测Age
1 2 3 4 5 6 7 8 9 score = rfr.score(ageKnown_X, ageKnown_Y) print (f'模型预测得分为: {score} ' )agePredict = rfr.predict(ageUnknown_X) full.loc[full['Age' ].isnull(), ['Age' ]] = agePredict full.info()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # 输出 模型预测得分为: 0.5865997049567819 <class 'pandas.core.frame.DataFrame'> RangeIndex: 1309 entries, 0 to 1308 Data columns (total 18 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 1309 non-null int64 1 Survived 891 non-null float64 2 Pclass 1309 non-null int64 3 Name 1309 non-null object 4 Sex 1309 non-null object 5 Age 1309 non-null float64 6 SibSp 1309 non-null int64 7 Parch 1309 non-null int64 8 Ticket 1309 non-null object 9 Fare 1309 non-null float64 10 Cabin 1309 non-null object 11 Embarked 1309 non-null object 12 Title 1309 non-null object 13 FamilyNum 1309 non-null int64 14 FamilySize 1309 non-null int64 15 Deck 1309 non-null object 16 TicketCom 1309 non-null int64 17 TicketGroup 1309 non-null int64 dtypes: float64(3), int64(8), object(7) memory usage: 184.2+ KB
所有缺失数据都已经填充完毕
同组识别
一些具有明显共同特征的数据与整体模型逻辑不一致,将这些具有同组效应的数据识别出来并对其数据加以修正,就可以提高模型的准确度
提取相同姓氏的旅客及相同数量
1 2 3 4 full['Surname' ] = full['Name' ].map (lambda x: x.split(',' )[0 ].strip()) SurNameDict = full['Surname' ].value_counts() full['SurnameNum' ] = full['Surname' ].map (SurNameDict)
提取相同姓氏的12岁以上男性
1 2 3 4 5 6 MaleDf = full[(full['Age' ] > 12 ) & (full['Sex' ] == 'male' ) & (full['FamilyNum' ] >= 2 )] MSurNameDf = MaleDf.groupby(['Surname' ])['Survived' ].mean() MSurNameDf.head() MSurNameDf.value_counts()
1 2 3 4 5 # 输出 0.0 89 1.0 19 0.5 3 Name: Survived, dtype: int64
我们发现对于那些12岁以上的同姓男性中,大部分都死亡,少部分存活
提取相同姓氏的12岁以下女性
1 2 3 4 5 6 FemaleDf = full[(full['Age' ] <= 12 ) | (full['Sex' ] == 'female' ) & (full['FamilyNum' ] >= 2 )] FSurNameDf = FemaleDf.groupby(['Surname' ])['Survived' ].mean() FSurNameDf.head() FSurNameDf.value_counts()
1 2 3 4 5 6 7 # 输出 1.000000 116 0.000000 28 0.750000 2 0.333333 1 0.142857 1 Name: Survived, dtype: int64
我们发现对于12岁以下的同姓女性,大部分存活,少部分死亡
而对于那些有同组效应的数据即:12岁以上存活的男性以及12岁以下死亡的女性,对其数据进行修正
提升12岁以上男性存活的概率
提升12岁以下女性死亡的概率
因为模型更倾向于让12岁以上的男性死亡,12岁以下的女性存活,导致模型会将那些同组效应的数据预测错误
也就是将那些本来存活的12岁以上男性预测为死亡,而将那些本来死亡的女性预测为存活
我们需要强化与规律相反的一面
对于这些数据进行修正
1 2 3 4 5 6 7 8 9 10 11 12 13 14 MSurNameDict = MSurNameDf[MSurNameDf.values == 1 ] MSurNameDict FSurNameDict = FSurNameDf[FSurNameDf.values == 0 ] FSurNameDict full.loc[(full['Survived' ].isnull()) & (full['Surname' ].isin(MSurNameDict) & (full['Sex' ] == 'male' )), 'Sex' ] = 'female' full.loc[(full['Survived' ].isnull()) & (full['Surname' ].isin(MSurNameDict) & (full['Sex' ] == 'male' )), 'Age' ] = 5 full.loc[(full['Survived' ].isnull()) & (full['Surname' ].isin(FSurNameDict) & (full['Sex' ] == 'female' )), 'Sex' ] = 'male' full.loc[(full['Survived' ].isnull()) & (full['Surname' ].isin(FSurNameDict) & (full['Sex' ] == 'female' )), 'Age' ] = 60
由于模型倾向于将12岁以上的男性预测为死亡,12岁以下的女性预测为存活
那就将那些存活的12岁以上的男性修改为5岁的女性
将那些死亡的12岁以下的女性修改为60岁的男性
这样就达到了增强与规律相反的一面的目的
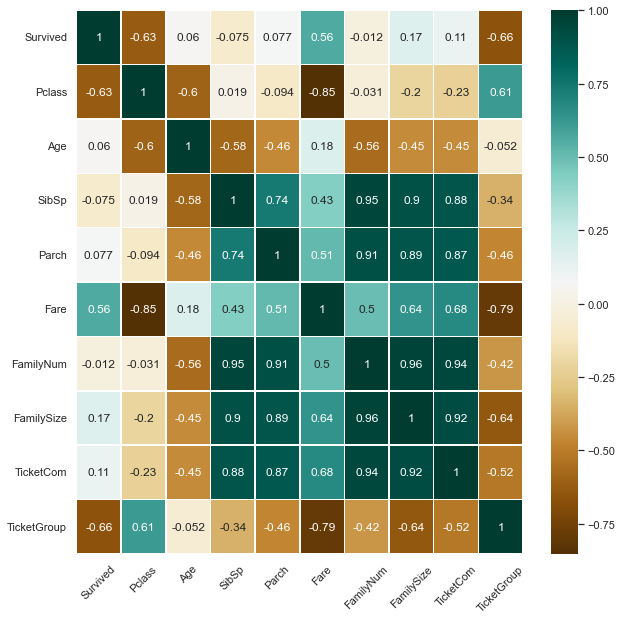
特征筛选
对于所有的特征,求其对于 Survived
的相关性系数,选出最大的几个作为最终特征
1 2 3 4 fullsel = full.drop(['Name' , 'Cabin' , 'Ticket' , 'PassengerId' , 'Surname' , 'SurnameNum' ], axis=1 ) corrDf = fullsel.corr() corrDf['Survived' ].sort_values(ascending=True )
1 2 3 4 5 6 7 8 9 10 11 12 # 输出 Pclass -0.338481 TicketGroup -0.319278 Age -0.059572 SibSp -0.035322 FamilyNum 0.016639 TicketCom 0.064962 Parch 0.081629 FamilySize 0.108631 Fare 0.331805 Survived 1.000000 Name: Survived, dtype: float64
使用热力图
去除相关性最低的几个特征:FamilyNum、Parch、SibSp、TicketCom
对字符串特征使用独热码编码
1 2 3 4 5 fullsel = fullsel.drop(['FamilyNum' , 'Parch' , 'SibSp' , 'TicketCom' ], axis=1 ) fullsel = pd.get_dummies(fullsel) fullsel
建模
使用多种模型对数据进行建模,选择效果最好的几个模型进行超参数优化
SVC:SVM支持向量机的一种模型
SVC:分类(Classification)
SVR:回归(Regression)
Decision Tree:决策树
Extra Trees:极端随机数
Gradient Boosting:梯度增强树
XGBoost:极端梯度增强树
Random Forest:随机森林
KNN:K近邻
Logistic Regression:逻辑回归
Linear Discriminant Analysis:线性判别分析
准备
数据集
1 2 3 4 5 6 model_train = fullsel[fullsel['Survived' ].notnull()] model_test = fullsel[fullsel['Survived' ].isnull()] train_X = model_train.drop('Survived' , axis=1 ) train_Y = model_train['Survived' ] test_X = model_test.drop('Survived' , axis=1 )
导库
1 2 3 4 5 6 7 8 9 10 11 from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, ExtraTreesClassifierfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysisfrom sklearn.linear_model import LogisticRegressionfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.svm import SVCfrom xgboost import XGBClassifierfrom sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFoldkfold = StratifiedKFold(n_splits=10 )
模型拟合
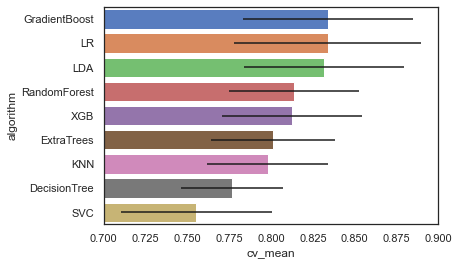
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 classifiers = [] classifiers.append(SVC()) classifiers.append(DecisionTreeClassifier()) classifiers.append(RandomForestClassifier()) classifiers.append(ExtraTreesClassifier()) classifiers.append(GradientBoostingClassifier()) classifiers.append(KNeighborsClassifier()) classifiers.append(LogisticRegression()) classifiers.append(LinearDiscriminantAnalysis()) classifiers.append(XGBClassifier()) cv_results = [] for classifier in classifiers: cv_results.append(cross_val_score(classifier, train_X, train_Y, cv=kfold, scoring='accuracy' , n_jobs=-1 )) cv_means = [] cv_std = [] for cv_result in cv_results: cv_means.append(cv_result.mean()) cv_std.append(cv_result.std()) cvResultDf = pd.DataFrame({'cv_mean' : cv_means, 'cv_std' : cv_std, 'algorithm' : ['SVC' , 'DecisionTree' , 'RandomForest' , 'ExtraTrees' , 'GradientBoost' , 'KNN' , 'LR' , 'LDA' , 'XGB' ]}) cvResultDf
1 2 3 4 5 6 7 8 9 10 11 # 输出 cv_mean cv_std algorithm 0 0.755406 0.050727 SVC 1 0.776717 0.055970 DecisionTree 2 0.813745 0.047722 RandomForest 3 0.801398 0.038931 ExtraTrees 4 0.833933 0.041794 GradientBoost 5 0.798015 0.037036 KNN 6 0.833920 0.036025 LR 7 0.831673 0.030415 LDA 8 0.812634 0.044882 XGB
可视化
1 2 bar = sns.barplot(data=cvResultDf.sort_values(by='cv_mean' , ascending=False ), x='cv_mean' , y='algorithm' , **{'xerr' : cv_std}) bar.set (xlim = (0.7 , 0.9 ))
超参数优化
选出最好的几个模型:Gradient Boosting、LR、LDA 对其进行超参数优化
我们使用网格搜索(Grid Search)对超参数进行优化
GBC
1 2 3 4 5 6 7 8 9 10 GBC = GradientBoostingClassifier() gbc_param_grid = {'loss' : ["exponential" ], 'n_estimators' : [100 , 200 , 300 , 400 ], 'learning_rate' : [0.01 , 0.05 , 0.1 , 0.15 ], 'max_depth' : [8 , 10 , 12 ], 'min_samples_leaf' : [50 , 100 , 150 ]} gsGBC = GridSearchCV(GBC, gbc_param_grid, cv=kfold, scoring='accuracy' , n_jobs=-1 , verbose=1 ) gsGBC.fit(train_X, train_Y) gsGBC.best_score_
LR
1 2 3 4 5 6 7 LR = LogisticRegression() lr_param_grid = {'C' : [1 , 2 , 3 ], 'penalty' : ['l1' , 'l2' ]} gsLR = GridSearchCV(LR, lr_param_grid, cv=kfold, scoring='accuracy' , n_jobs=-1 , verbose=1 ) gsLR.fit(train_X, train_Y) gsLR.best_score_
LDA
1 2 3 4 5 6 7 lda = LinearDiscriminantAnalysis() lda_param_grid = {'solver' : ['eigen' , 'lsqr' , 'svd' ], 'tol' : [1e-5 , 1e-4 , 1e-3 , 1e-2 , 1e-1 ]} gsLDA = GridSearchCV(lda, lda_param_grid, cv=kfold, scoring='accuracy' , n_jobs=-1 , verbose=1 ) gsLDA.fit(train_X, train_Y) gsLDA.best_score_
选出得分最高的:GBC模型
模型评估
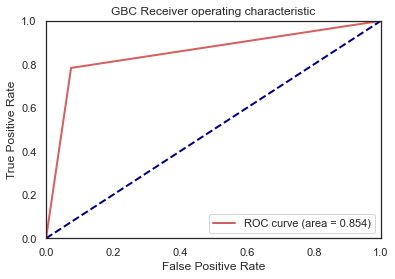
使用ROC-AUC进行模型评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 gbc_train_pre = gsGBC.predict(train_X).astype(int ) from sklearn.metrics import roc_curve, aucfpr, tpr, thresholds = roc_curve(train_Y, gbc_train_pre) roc_auc = auc(fpr, tpr) plt.figure() lw = 2 plt.plot(fpr, tpr, color='r' , lw=lw, label='ROC curve (area = %0.3f)' % roc_auc) plt.plot([0 , 1 ], [0 , 1 ], color='navy' , lw=lw, linestyle='--' ) plt.xlim([0.0 , 1.0 ]) plt.ylim([0.0 , 1.0 ]) plt.xlabel('False Positive Rate' ) plt.ylabel('True Positive Rate' ) plt.title('GBC Receiver operating characteristic' ) plt.legend(loc="lower right" ) plt.show()
使用混淆矩阵评估
1 2 from sklearn.metrics import confusion_matrixprint (f'GBC的混淆矩阵为:\n{confusion_matrix(train_Y, gbc_train_pre)} ' )
1 2 3 4 5 # 输出 GBC的混淆矩阵为: [[508 41] [ 74 268]]
模型预测
使用最终的模型对测试数据进行预测,并保存预测数据为CSV,在Kaggle官网提交答案
1 2 3 4 5 6 7 y_ = gsGBC.predict(test_X).astype(int ) xgb_result_df = pd.DataFrame() xgb_result_df['PassengerId' ] = full['PassengerId' ][full['Survived' ].isnull()] xgb_result_df['Survived' ] = y_ xgb_result_df xgb_result_df.to_csv('./data/titanic/gbc_titanic_output.csv' , index=False )
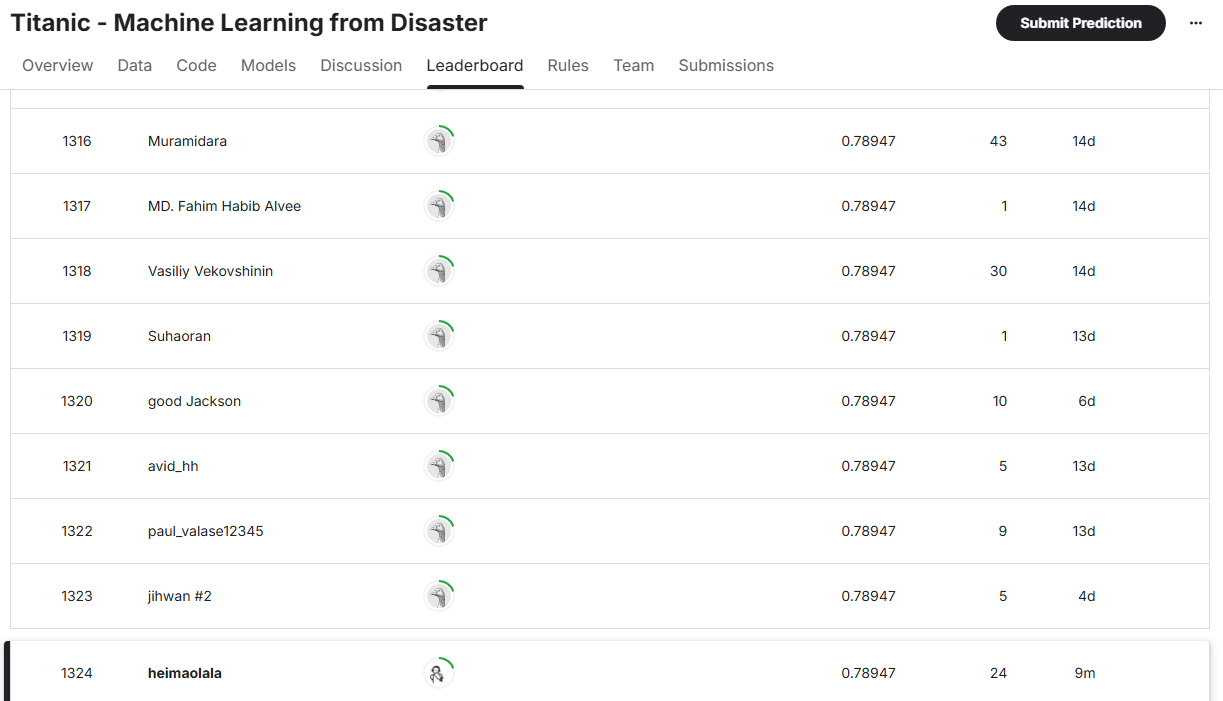
我的最终成绩为
由于泰坦尼克号的测试集较少,很多Kaggle用户滥用数据集,将模型预测率提高到了100%
这是没有意义的,因为预测生死本就是一个没有任何把握的事情,其他问题也一样,这些问题是随机的,没有任何模型能够达到100%准确率,上帝来了也不行
除去那些1.00的成绩共209人,以及共分人数,我的排名为873,全球前6%
总结
通过泰坦尼克号生死预测竞赛,掌握机器学习的基本流程,以及Kaggle的使用
而在建模过程中,我也发现了特征的重要性,一个好的特征能够对准确率有巨大提升,而榨干模型的性能换来的准确率的提升远远不如做好特征工程
而此次竞赛中使用了sklearn和seaborn,我在将来会更新这两个库的使用教程,敬请期待...
如有任何问题可以留言或者点击左侧邮箱联系...