PyTorch 是一个开源的机器学习库,基于
Python,主要用于深度学习任务。它由 Facebook
的人工智能研究团队(FAIR)开发,并于 2016 年首次发布。PyTorch
以其动态计算图、易用性和灵活性而广受欢迎,是目前最流行的深度学习框架之一。
这篇文章将使用通俗易懂的语言介绍PyTorch的使用方法,以及深度学习的具体流程
在深度学习应用中,计算机视觉和自然语言处理占据了90%
在介绍时,我将使用以图片训练数据的例子进行介绍
请结合 PyTorch中文站
进行学习
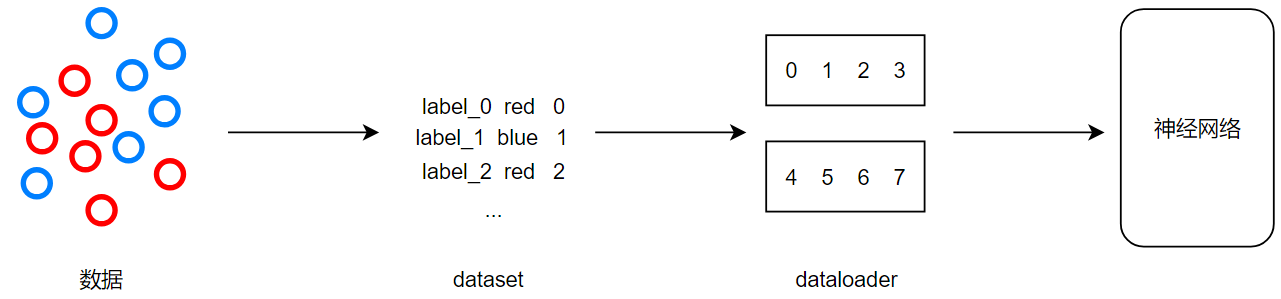
数据加载
Tensor
深度学习的一种数据类型,又称为 张量 ,实质为多维矩阵
可以进行GPU计算的矩阵
包装了反向神经网络所需参数的数据类型
张量类型:
0阶:标量 scalar
1阶:向量 vector
2阶:矩阵 matrix
m = [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
n阶:张量 tensor
t = [[[ ... ]]] (有多少个中括号就是多少阶张量)
上述的 0、1、2 阶都是张量
创建 Tensor 类型
1 2 3 import torchx = torch.tensor(数据)
Dataset
而对于计算机视觉来说,数据组织形式为:数据+标签
常见的数据组织形式:
类型一:
类型二:
训练集(train)
训练集标签(train_label)
验证集(val)
验证集标签(val_label)
无论是类型一还是二,他们都提供了数据和标签,只不过数据和标签的存储方式不同
我们要做的就是提取数据和标签
dataset:提供一种方式去获取数据及其标签
导库:
1 from torch.utils.data import Dataset
使用方法:
1 2 3 4 5 6 7 def __getitem__ (self, index ):def __init__ (self, 参数1 , 参数2 , ... ):
PIL和OS
PIL: 对于图数据而言,PIL的作用就是读取图片数据
OS:
对于存储于文件夹中的数据,使用OS库读取文件,以及相关信息
1 2 from PIL import Imageimport os
常用方法:
1 2 3 4 5 6 7 8 9 10 img = Image.open (图片路径) path = os.listdir(文件路径) new_path = os.path.join(路径1 , 路径2 ) ''' A = a/b B = c C = os.path.join(A, B) C = a/b\\c '''
重写方法:
对于数据形式1:有一个二分类的蚂蚁和蜜蜂图片数据
对于数据处理,我们一般将训练集和验证集视为不同的两组数据
所以对于训练集的数据处理方法对于验证集也是一样的
分析:
我们需要的是数据对象及其标签
对于数据对象来说,其存储在各自的文件夹中,使用OS拼接图片地址,使用PIL读取
对于标签来说,其为文件夹名称,可以直接获取
在初始化属性阶段,传入的参数可以是:数据目录+标签文件名
1 2 3 4 root_dir = '.../train' ants_label_dir = 'ants' bees_label_dir = 'bees'
在重写 getitem 方法中,我们需要返回数据对象以及标签
具体代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from torch.utils.data import Datasetfrom PIL import Imageimport osclass MyDataset (Dataset ): def __init__ (self, root_dir, label_dir ): self .root_dir = root_dir self .label_dir = label_dir self .path = os.path.join(root_dir, label_dir) self .img_path = os.listdir(self .path) def __getitem__ (self, index ): img_name = img_path(index) img_item_path = os.path.join(self .path, img_name) img = Image.open (img_item_path) label = self .label_dir return img, label def __len__ (self ): return len (self .img_path) root_dir = '.../train' ants_label_dir = 'ants' bees_label_dir = 'bees' ants_data = MyDataset(root_dir, ants_label_dir) bees_data = MyDataset(root_dir, bees_label_dir) data = ants_data + bees_data
DataLoader
为后面的网络提供不同的数据形式
说白了,就是把dataset的数据分为几组,以组为单位对神经网络进行投喂
就是之前机器学习讲的:批(batch)和小批量(mini-batch)
导库:
1 from torch.utils.data import DataLoader
常用参数
Dataloader():
dataset:加载的数据集
若为dataset类对象,其 getitem 方法必须返回:数据+标签 的格式
batch_size:几个数据为一组(默认1)
shuffle:若为 True 则每次对数据重新洗牌(默认 False)
num_workers:进程数(默认 0,win上 >0 可能报错)
drop_last:若分组不整除,余数是否丢弃(默认 False)
返回值:
imgs: 组内的图片数据
targets: 各个数据对应的标签
1 2 3 4 5 6 7 img0, target0 = dataset[0 ] img1, target1 = dataset[1 ] img2, target2 = dataset[2 ] img3, target3 = dataset[3 ] ↓ ↓ imgs targets
数据使用
1 2 for data in dataloader: imgs, targets = data
Tensorboard
TensorBoard 是一个可视化工具,最初是为 TensorFlow 设计的,但随着
PyTorch 等其他框架的流行,它也逐渐被集成到 PyTorch
中,成为深度学习中常用的可视化工具之一
TensorBoard
可以帮助用户直观地监控模型的训练过程、分析模型性能、调试代码以及展示实验结果
导库:
1 from torch.utils.tensorboard import SummaryWriter
初始化:
1 writer对象 = SummaryWriter('文件名' )
常用方法
绘图:
writer对象.add_image():单一图像数据
tag:图像名称,字符串
data:图像数据(类型:tensor,np.array,string,blobname)
global_step:步骤(图像标号)
dataformats:默认 CHW ;若不是,则需要指定
writer对象.add_images() :dataloader处理后的小批量图像数据
tag:图像名称,字符串
data:图像数据(类型:tensor,np.array,string,blobname)PIL格式不符合
global_step:步骤(图像标号)
dataformats:默认 CHW ;若不是,则需要指定
writer对象.add_scalar():散点
tag:图表名称,字符串
y:y表达式
x:x表达式
其他方法可以自行查找官方文档
在使用 add 添加图像、图表之后需要在末尾添加:
使用案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from torch.utils.tensorboard import SummaryWriterfrom PIL import Imageimport numpy as npwriter = SummaryWriter('logs' ) image_path = 'img.jpg' img = Image.open (image_path) img_array = np.array(img) writer.add_image('test' , img_array, 1 , dataformats='HWC' ) writer.close()
打开事件文件
在运行相关代码之后,会在当前文件所在位置生成一个文件夹,为事件文件夹,里面会有一个事件文件
运行:
使用conda打开pytorch环境
输入命令:
1 2 3 4 5 6 7 tensorboard --logdir=事件文件所在文件夹名 ''' 可加参数: --port=端口号 默认为6006端口,若被占用,可以指定端口 '''
随后打开网站:http://localhost:6006 就可以看到tensorboard的界面
若指定端口则最后输入指定的端口
这里介绍的是 torchvision 的 transforms
Transforms
能够对图片数据进行各种操作,例如缩放,裁切,拉伸等等操作(数据增强)
导库:
1 from torchvision import transforms
使用模板:
1 2 3 4 5 操作对象 = transforms.方法() new_data = 操作对象(data)
常用方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 transforms.ToTensor() ''' totensor = transforms.ToTensor() new_data = totensor(data) 这里的数据只能是 PIL 或 ndarray ''' transforms.ToPILImage() ''' topilimage = transforms.ToPILImage() new_data = topilimage(data) 这里的数据只能是 ndarray 或 Tensor ''' transforms.Normalize(mean, std) ''' normalize = transforms.Normalize(mean, std) new_data = normalize(data) - 这里的 mean std 为图像各个信道的数据均值和标准差 - 例如:mean = [0.5, 0.5, 0.5] std = [0.5, 0.5, 0.5] ''' transforms.Resize((shape)) ''' resize = transforms.Resize((512, 512)) 若只有一个值,则将最短边改为该值,其余等比缩放 new_data = resize(data) 这里的数据只能是 PIL 或 Tensor ''' transforms.Compose([操作对象1 ,操作对象2 ,操作对象3 ...]) ''' compose = transforms.Compose([totensor, normalize, resize]) new_data = compose(data) 对 data 顺序执行:Totensor,Normalize,Resize操作 ''' transforms.RandomCrop((shape)) ''' randomcrop = transforms.RandomCrop((256, 512)) 若只有一个值,则裁剪正方形 new_data = randomcrop(data) '''
数据集
PyTorch 有自带的数据集,可以直接使用
这里使用 torchvision 自带的数据集
导入:
1 2 3 import torchvisiondata_set = torchvision.datasets.具体数据集()
每一个数据集导入的方法略有不同,具体请查看官方文档
但是一些参数是常见的:
root:数据放在什么位置,填入相对地址(例如:./dataset)
train:True表示下载数据集的训练集,False表示下载数据集的测试集
download:True表示若本地没有则下载存入之前的地址
transform:应用 transform 对象,直接对数据进行操作
例如:
1 2 3 4 5 6 7 8 9 10 import torchvisionfrom torchvision import transformsdataset_transform = transforms.Compose([transforms.ToTensor()]) train_set = torchvision.datasets.CIFAR10(root='./data' , train=True , transform=dataset_transform, download=True ) test_set = torchvision.datasets.CIFAR10(root='./data' , train=False , transform=dataset_transform, download=True )
神经网络搭建
PyTorch中,神经网络的搭建可以模块化进行,只需要使用官方的 torch.nn
即可
导库:
1 2 3 4 import torch.nn as nnimport torch.nn.function as F
搭建模型及使用
搭建:
创建的模型类必须继承 nn.Module
重写 init 方法
重写 forward 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 class Test (nn.Module): def __init__ (self ): super ().__init__() . 自定义参数 . def forward (self, x ): . 相关操作 . return x
使用:
初始化类对象
传入参数(参数类型必须为 Tensor 类型)
神经网络层
神经网络层分为:卷积计算层 和 全连接层
卷积计算层
卷积层
批标准(归一)化层
激活层
池化层
Dropout 层
Flatten():从卷积计算层到全连接层过度
全连接层
卷积层
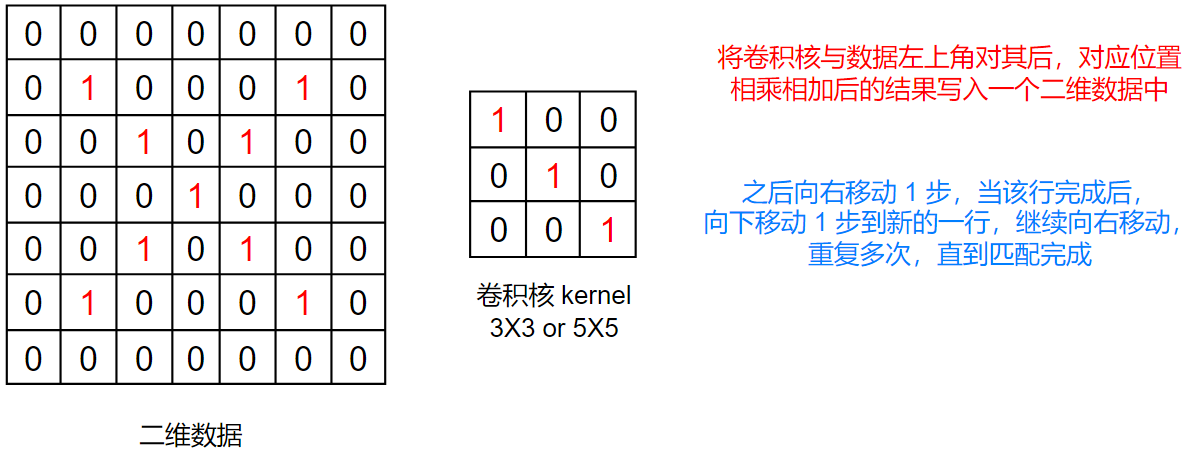
这里我们不详细介绍卷积是什么,只介绍使用方法,具体可以看之后的深度学习教程
卷积其实是特征提取器,提取图像中的特征
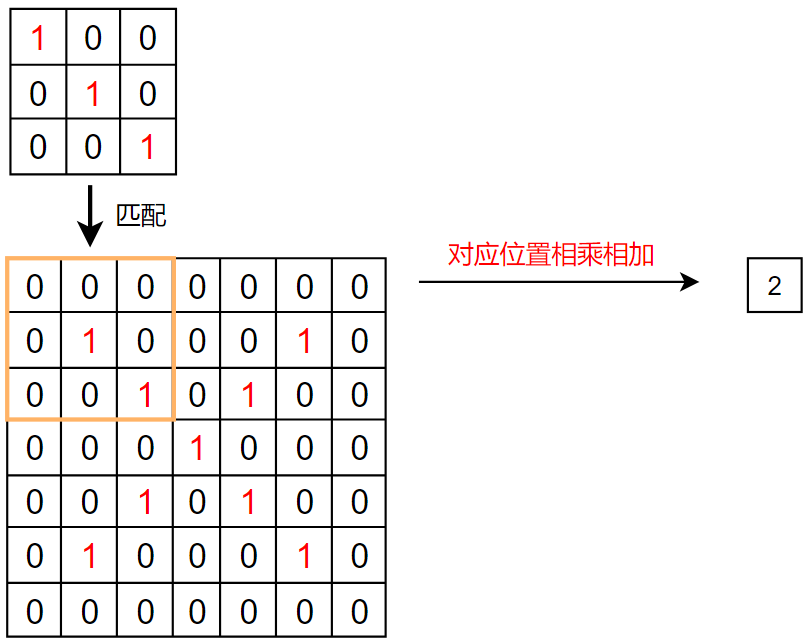
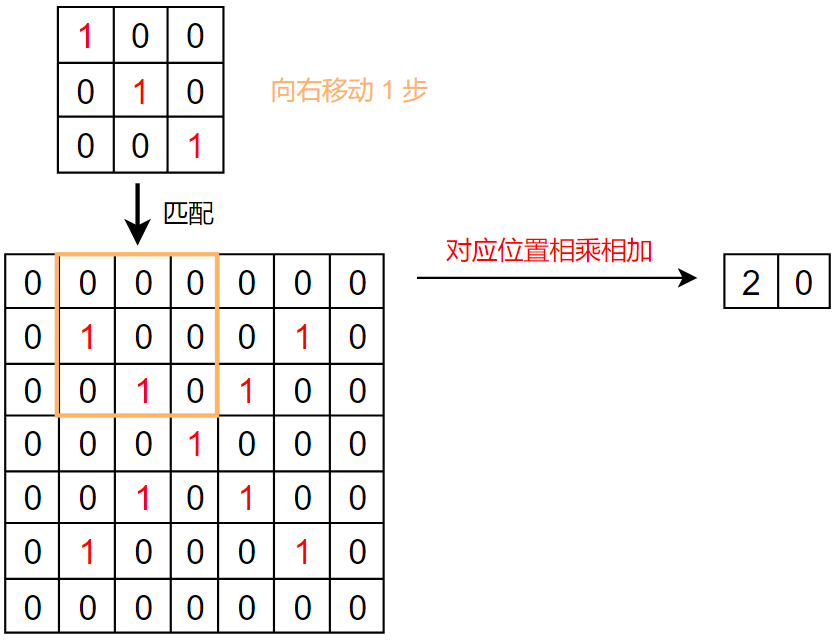
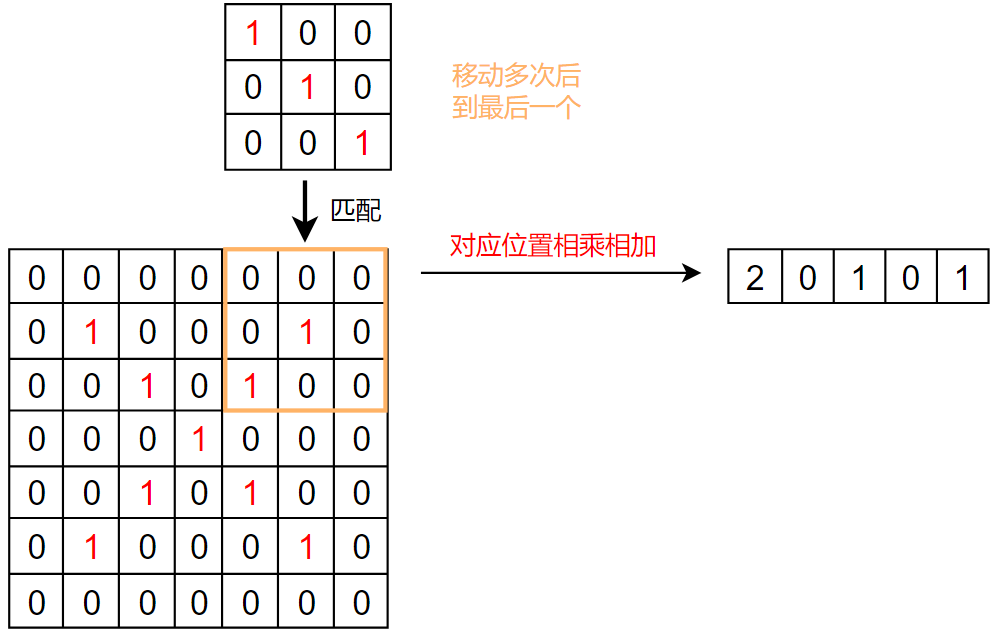
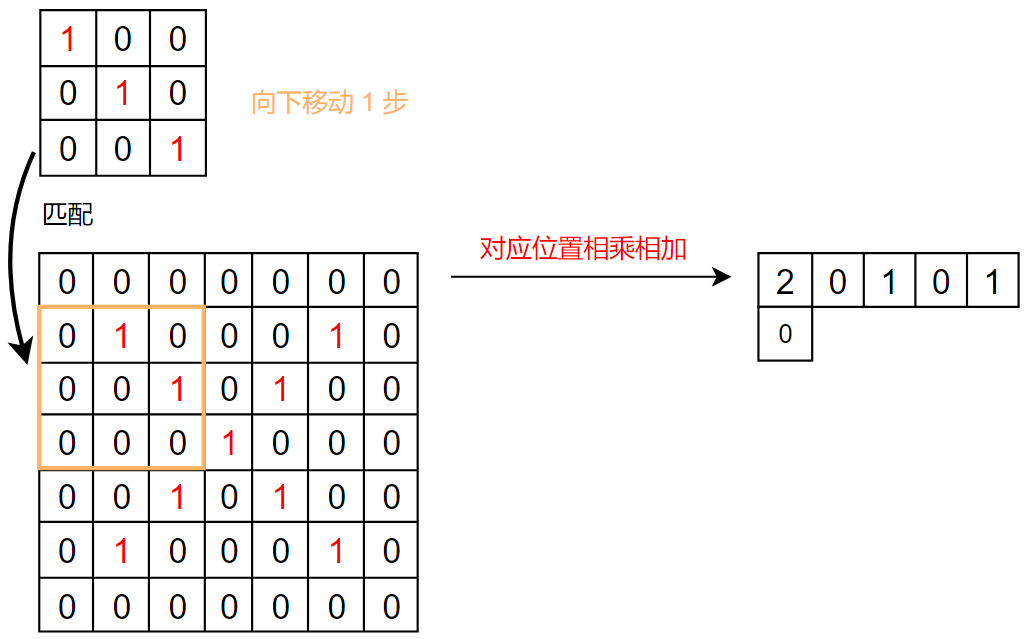
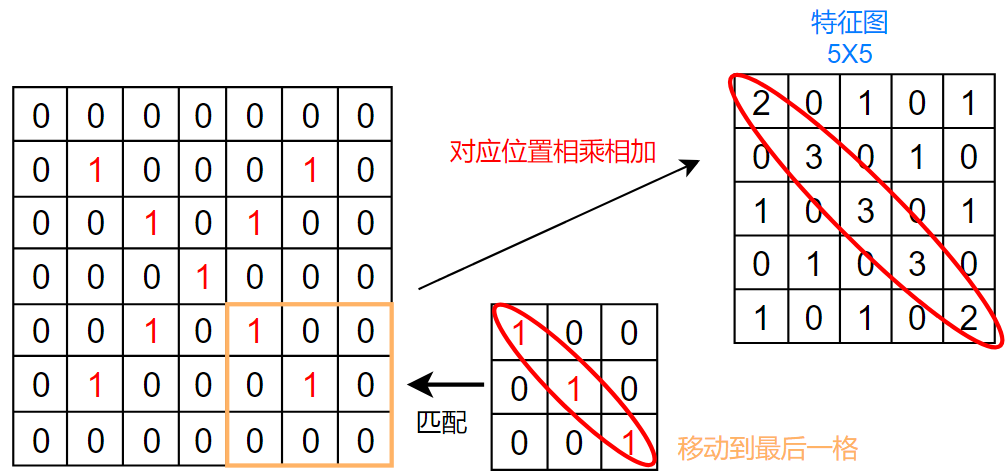
具体流程:
我们发现,生成的特征图中,从左上到右下的对角线的数值最大
这和我们的卷积核一样,卷积核也是左上到右下的数值最大,这就体现了卷积的特征提取功能
所以,卷积其实就是一个特征提取器,和我们人看见东西一样,都是先分析其特征,才能判断是什么东西
PyTorch中的卷积:
torch.nn.fuctional
中的卷积
1 2 3 import torch.nn.functional as FF.conv2d(input , weight, stride, padding)
常用参数:
input:输入格式(N, C, H, W),数据类型为Tensor
,维度为四维,各个维度对齐格式
N:一个batch内的数据数量
C:通道数
H:输入数据的高
W:输入数据的宽
weight:权重/卷积核,格式(out, C/group, H, W)
out:输出通道数/卷积核个数(一个卷积核产生一个输出)
C/group:group一般为1,所以填入通道数即可
H:卷积核高
W:卷积核宽
stride:卷积核移动的步长(默认为 1)
单个数:在高和宽的维度上移动都是 n 步
元组:(H, W)分别设置高和宽维度上的步数
padding:0填充(默认为 0)
单个数:在高和宽上同时添加一行和一列
元组:(H, W)分别设置高和宽上填充的行数和列数
可能会用到的方法:
torch.reshape(input, shape)
input:输入数据
shape:填入元组,将数据变为指定的维度,可以填入-1,自动计算该维度,且只能填一次
例如 (1, 1, 7, 7):四维,每个维度数量为 1 1 7 7
案例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import torchimport torch.nn.functional as Finput = torch.tensor([[0 , 0 , 0 , 0 , 0 , 0 , 0 ], [0 , 1 , 0 , 0 , 0 , 1 , 0 ], [0 , 0 , 1 , 0 , 1 , 0 , 0 ], [0 , 0 , 0 , 1 , 0 , 0 , 0 ], [0 , 0 , 1 , 0 , 1 , 0 , 0 ], [0 , 1 , 0 , 0 , 0 , 1 , 0 ], [0 , 0 , 0 , 0 , 0 , 0 , 0 ]]) kernel = torch.tensor([[1 , 0 , 0 ], [0 , 1 , 0 ], [0 , 0 , 1 ]]) input = torch.reshape(input , (1 , 1 , 7 , 7 )) kernel = torch.reshape(kernel, (1 , 1 , 3 , 3 )) output1 = F.conv2d(input , kernel, stride=1 ) output2 = F.conv2d(input , kernel, stride=2 ) output3 = F.conv2d(input , kernel, stride=1 , padding=1 ) print (output1)print (output2)print (output3)
torch.nn中的卷积
1 2 3 4 5 6 7 8 from torch.nn import Conv2dConv2d(in_channels, out_channels, kernel_size, stride, padding, padding_mode, dilation) --------方式二------------- import torch.nn as nnnn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, padding_mode, dilation)
常用参数:
in_channels:输入数据的通道数(输入要和前一层输出一致)
out_channels:输出数据的通道数(卷积核数量)
kernel_size:卷积核大小
单个数:n x n 的正方形卷积核
元组:(H, W) 自定义高宽的卷积核
stride:卷积核移动步长(默认 1)
单个数:在高和宽的维度上移动都是 n 步
元组:(H, W)分别设置高和宽维度上的步数
padding:填充(默认为 0)
单个数:在高和宽上同时添加一行和一列
元组:(H, W)分别设置高和宽上填充的行数和列数
padding_mode:填充的数据(默认'zeros')其余参数请查看文档
dilation:卷积核的间隔(默认1,即卷积核内各个数据相邻)
单个数:在高和宽的维度上间隔都是 n-1 格
元组:(H, W)分别设置高和宽维度上的间隔
经过卷积之后,输出的特征图的大小满足以下公式:
若想保持特征图大小不变,则在其他参数都为默认值的情况下,padding为:
padding = (kernel_size - 1) / 2
使用方法:
1 2 对象 = Conv2d(...) 返回值 = 对象(输入数据)
池化层
池化层的作用是降低数据的空间维度,提取特征值,减小参数计算量和数量
池化层的工作方式和卷积一样,只不过卷积是对所匹配窗口内的数据相乘相加,而池化是直接对所匹配的窗口内的数据进行一次全局操作
操作的不同对应了不同的池化:
最大池化 Max_pooling:对窗口内的数据取最大值(保留显著特征)
平均池化
Average_pooling:对窗口内的数据取平均值(平滑特征,减少噪声)
自适应池化 Adaptive_pooling:根据输出尺寸自适应调整窗口大小
全局池化 Global_pooling:取整个特征图的最大值或最小值
在卷积中,移动的窗口叫做卷积核,池化的窗口叫做池化核
PyTorch中的池化
1 2 3 4 5 6 7 8 from torch.nn import Maxpool2dMaxpool2d(kernel_size, stride, padding, dilation, ceil_mode) --------方式二------------- import torch.nn as nnnn.Maxpool2d(kernel_size, stride, padding, dilation, ceil_mode)
kernel_size:池化核大小
单个数:n x n 的正方形池化核
元组:(H, W) 自定义高宽的池化核
stride:池化核移动步长(默认值同 kernel_size )
单个数:在高和宽的维度上移动都是 n 步
元组:(H, W)分别设置高和宽维度上的步数
padding:隐式负无穷填充(默认为 0)
单个数:在高和宽上同时添加一行和一列
元组:(H, W)分别设置高和宽上填充的行数和列数
dilation:卷积核的间隔(默认1,即卷积核内各个数据相邻)
单个数:在高和宽的维度上间隔都是 n-1 格
元组:(H, W)分别设置高和宽维度上的间隔
ceil_mode:移动超出数据矩阵后,是否保留不完整数据(默认 False)
经过池化之后,输出的特征图的大小满足以下公式:
使用方法:
1 2 对象 = Maxpool2d(...) 返回值 = 对象(输入数据)
(非线性)激活
引入非线性变换,使得能拟合复杂的线性关系,若没有非线性变换,则只能拟合线性
在之前的机器学习中,我们知道了一些激活函数:Sigmoid、ReLu 、Softmax
等等
使用:
1 2 3 4 5 6 7 8 9 10 from torch.nn import 激活函数对象 = 激活函数() 返回值 = 对象(输入数据) ----------或------------ import torch.nn as nn对象 = nn.激活函数() 返回值 = 对象(输入数据)
返回值为:对各个位置应用函数表达式后的对应输出
Dropout
顾名思义,Dropout的作用就是以一定概率舍弃元素、通道或神经元,能够降低模型过拟合的风险
具体使用可以参照 官方文档
这里不做赘述
线性层(全连接层)
从卷积计算层到全连接层,需要将高维数据展平
Flatten:
torch.flatten(input)
nn.Flatten()
使用
1 2 3 4 5 6 7 8 import torchtorch.flatten(input ) --------or -------- import torch.nn as nnnn.Flatten()
Linear
在PyTorch中,描述全连接层可以使用 Linear
导库
1 2 3 import torch.nn as nnnn.Linear(in_features, out_features, bias)
参数:
若前一层为卷积计算层,那么第一层的线性层的输入为:
in_channels = out_channels * H * W
LazyLinear(PyTorch>1.9)
若线性层上一层为卷积层,那么输入特征需要手动计算,很不方便
而 LazyLinear 很好解决了这一点,不需要填入输入特征数
常用参数:
out_features(必选;常用):输出特征维度
bias:是否学习偏置
device:设备(如:'cuda')
dtype:权重数据的数据类型
例子:
1 2 3 4 import torch.nn as nnfc = nn.LazyLinear(128 )
需要注意的是,LazyLinear本身缺少 输入特征数
这一参数,所以不能一次数据都不跑就直接保存参数,否则会出错
顺序容器
Sequential
和 Transform 中的 Compose
方法一样,神经网络也有自己的顺序执行容器
Sequential()导入:
1 2 3 4 5 6 7 from torch.nn import SequentialSequential() import torch.nn as nnnn.Sequential()
Sequential()使用:
1 2 3 4 5 6 7 8 9 10 from torch.nn import Sequential对象 = Sequential( 相关方法1 , 相关方法2 , 相关方法3 , ... ) out = 对象(输入)
案例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchimport torch.nn as nnfrom torch.nn import Sequential, Linear, Conv2d, MaxPool2d, Flattenclass Net (nn.Module): def __init__ (self ): super (Net, self ).__init__() self .model1 = Sequential( Conv2d(3 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 64 , 5 , padding=2 ), MaxPool2d(2 ), Flatten(), Linear(1024 , 64 ), Linear(64 , 10 ) ) def forward (self, x ): return self .model1(x) net = Net() test = torch.ones((64 , 3 , 32 , 32 )) out = net(test) print (out.shape)
使用 Tensorboard 可视化网络
在建立一个模型之后,我们可以使用 Tensorboard
来查看模型的结构以及参数
使用:
1 2 3 4 5 6 7 8 9 10 from torch.utils.tensorboard import SummaryWriternet = Net() test = torch.ones((64 , 3 , 32 , 32 )) out = net(test) writer = SummaryWriter('log' ) writer.add_graph(net, test) writer.close()
之后按照正常的 Tensorboard 的操作就可以查看网络结构和参数
损失函数
在之前的机器学习中我们详细介绍过各种损失函数,这里不再对每一个损失函数进行介绍
我们只介绍其在 PyTorch 中的对应函数以及使用方法
我们只介绍三种常用损失函数,其他的可以去 官方文档
了解
L1Loss:绝对误差
MSELoss:均方误差
CrossEntropyLoss:交叉熵(分类)
L1Loss
使用:
1 2 3 4 from torch.nn import L1Loss损失函数对象 = L1Loss(reduction) 输出 = 损失函数对象(经过网络后的输出, 标签)
参数:
reduction:决定输出的方式
'sum':输出为所有数据的误差总和
'mean':输出为所有数据的误差均值(默认)
MSELoss
使用:
1 2 3 4 from torch.nn import MSELoss损失函数对象 = MSELoss(reduction) 输出 = 损失函数对象(经过网络后的输出, 标签)
参数:
reduction:决定输出的方式
'sum':输出为所有数据的误差总和
'mean':输出为所有数据的误差均值(默认)
CrossEntropyLoss
使用:
1 2 3 4 5 6 7 8 9 from torch.nn import CrossEntropyLoss损失函数对象 = CrossEntropyLoss() 输出 = 损失函数对象(经过网络后的输出, 标签) ''' 输入格式:(N, C) or C N:类别数量 C:各个类别的输出 (若要单独使用,则数据必须是二维) '''
案例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torchfrom torch.nn import L1Loss, MSELoss, CrossEntropyLosstest = torch.tensor([1. , 2 , 3 ]) target = torch.tensor([1. , 2 , 5 ]) loss = L1Loss(reduction='sum' ) out = loss(test, target) print (out)mse_loss = MSELoss() out1 = mse_loss(test, target) print (out1)ce_loss = CrossEntropyLoss() x = torch.tensor([0.2 , 0.7 , 0.1 ]) x = torch.reshape(x, (1 , 3 )) y = torch.tensor([1 ]) out = ce_loss(x, y) print (out)
参数更新
反向传播
在 PyTorch
中实现参数更新,需要对损失函数的输出使用反向传播,生成梯度为后面的优化器更新参数做准备
例如:
1 2 3 4 5 损失函数对象 = xxLoss() 输出 = 损失函数对象(x, y) 输出.backward()
优化器
优化器的作用就是更新参数,不同优化器更新参数的方式略有不同
常见的优化器有:SGD、SGDM、Adam等等
在 PyTorch 中,优化器需要对模型参数使用,之后配合 backward()
进行参数更新
具体使用:
1 2 3 4 5 6 7 8 9 10 11 模型对象 = 模型类() 优化器对象 = torch.optim.具体的优化器(模型对象.parameters(), lr=学习率, ...其他参数) 优化器对象.zero_grad() 输出.backward() 优化器对象.step()
以上完成后记为一次学习,一般要配合 for 循环来进行
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import torchimport torch.nn as nnimport torchvisionfrom torch.nn import Sequential, Linear, Conv2d, MaxPool2d, Flatten, CrossEntropyLossfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterfrom torchvision import transformsfrom tqdm import tqdm, trangedataset = torchvision.datasets.CIFAR10(root='./data' , train=True , download=True , transform=transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=1 ) class Net (nn.Module): def __init__ (self ): super (Net, self ).__init__() self .model1 = Sequential( Conv2d(3 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 64 , 5 , padding=2 ), MaxPool2d(2 ), Flatten(), Linear(1024 , 64 ), Linear(64 , 10 ) ) def forward (self, x ): return self .model1(x) net = Net() optimizer = torch.optim.SGD(net.parameters(), lr=0.001 ) for i in range (20 ): loss = 0 for imgs, labels in tqdm(dataloader): output = net(imgs) ex_loss = CrossEntropyLoss() output_loss = ex_loss(output, labels) loss += output_loss optimizer.zero_grad() output_loss.backward() optimizer.step() print (f'loss: {loss} ' )
测试部分
在训练之后,我们需要对已经训练的参数进行测试,查看训练效果
而测试部分的代码和训练时一样,只不过多了一件和少了一件东西
多了一件:循环外需要包裹:with torch.no_grad():
少了一件:不需要训练时的参数更新部分
就像这样:
1 2 3 4 with torch.no_grad(): for imgs, targets in test: out = net(imgs) loss_out = loss(out, targets)
以上是最基本的测试写法,根据需求还可以加上正确率的计算等等
其他网络模型
网络模型下载
除了自己构建网络模型,也可以从网络下载其他模型来使用,对于常用的模型
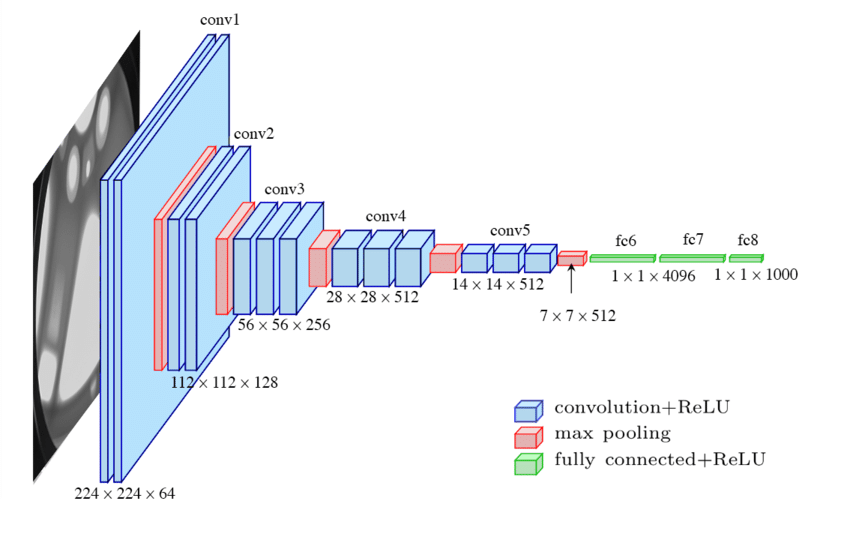
VGG16 来说,如何下载它
首先需要更新模型参数的下载地址:
1 2 3 import osos.environ['TORCH_HOME' ] = '下载路径'
这里模型 VGG16 举例,其他 TorchVision 模型可以查看 文档
使用:
1 2 3 4 5 6 7 8 import torchvision模型对象 = torchvision.models.vgg16(weight, progress) import torchvision.models as models模型对象 = models.vgg16(weight, progress)
参数:
weight:是否使用预训练参数
progress:是否显示下载进度条
迁移学习
对已经预训练过的模型应用到本地进行训练
我们继续使用 vgg16 举例
对于 vgg16 ,最后一层输出层的输出有1000个,如果要应用到 CIFAR10
数据集中,需要将最后一层输出改为10个
那么我们可以在 vgg16 模型的后面加一个输入为1000,输出为10的线性层
添加模型
add_module操作:
1 模型对象.add_module('新一层的名称' , 要添加的层/其他函数)
vgg16示例:
1 2 3 4 5 6 7 8 9 vgg_net = torchvision.models.vgg16(False ) vgg_net.add_module('add_linear' , nn.Linear(1000 , 10 )) print (vgg_net)
修改模型
如果不想要在末尾添加模型,那可以修改模型指定的层
这是vgg16的网络结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 VGG( (features): Sequential( (0 ): Conv2d(3 , 64 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (1 ): ReLU(inplace=True ) (2 ): Conv2d(64 , 64 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (3 ): ReLU(inplace=True ) (4 ): MaxPool2d(kernel_size=2 , stride=2 , padding=0 , dilation=1 , ceil_mode=False ) (5 ): Conv2d(64 , 128 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (6 ): ReLU(inplace=True ) (7 ): Conv2d(128 , 128 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (8 ): ReLU(inplace=True ) (9 ): MaxPool2d(kernel_size=2 , stride=2 , padding=0 , dilation=1 , ceil_mode=False ) (10 ): Conv2d(128 , 256 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (11 ): ReLU(inplace=True ) (12 ): Conv2d(256 , 256 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (13 ): ReLU(inplace=True ) (14 ): Conv2d(256 , 256 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (15 ): ReLU(inplace=True ) (16 ): MaxPool2d(kernel_size=2 , stride=2 , padding=0 , dilation=1 , ceil_mode=False ) (17 ): Conv2d(256 , 512 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (18 ): ReLU(inplace=True ) (19 ): Conv2d(512 , 512 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (20 ): ReLU(inplace=True ) (21 ): Conv2d(512 , 512 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (22 ): ReLU(inplace=True ) (23 ): MaxPool2d(kernel_size=2 , stride=2 , padding=0 , dilation=1 , ceil_mode=False ) (24 ): Conv2d(512 , 512 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (25 ): ReLU(inplace=True ) (26 ): Conv2d(512 , 512 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (27 ): ReLU(inplace=True ) (28 ): Conv2d(512 , 512 , kernel_size=(3 , 3 ), stride=(1 , 1 ), padding=(1 , 1 )) (29 ): ReLU(inplace=True ) (30 ): MaxPool2d(kernel_size=2 , stride=2 , padding=0 , dilation=1 , ceil_mode=False ) ) (avgpool): AdaptiveAvgPool2d(output_size=(7 , 7 )) ->(classifier): Sequential( | (0 ): Linear(in_features=25088 , out_features=4096 , bias=True ) | (1 ): ReLU(inplace=True ) | (2 ): Dropout(p=0.5 , inplace=False ) | (3 ): Linear(in_features=4096 , out_features=4096 , bias=True ) | (4 ): ReLU(inplace=True ) | (5 ): Dropout(p=0.5 , inplace=False ) --> (6 ): Linear(in_features=4096 , out_features=1000 , bias=True ) ) )
如果不想在末尾添加,那么我们可以修改上述模型的最后一层的输出,将其由1000改为10
而最后一层对应的模块为:classifier[6]
修改方法为:
1 模型对象.具体模块[具体位置] = 网络层/函数
对于上述例子:
1 2 3 vgg_net = torchvision.models.vgg16(False ) vgg_net.classifier[6 ] = nn.Linear(4096 , 10 )
如果知道了模型的结构,那么 add_module
还有一个玩法,那就是在指定模块末尾添加网络层
1 2 3 4 5 模型对象.具体模块.add_module(...) vgg_net.classifier.add_module(...)
模型保存与加载
模型的保存方式有两种:
方式一:
1 torch.save(模型对象, '保存路径' )
1 模型对象 = torch.load('模型文件路径' )
方式二: (推荐,保存的文件大小更小)
1 torch.save(模型对象.state_dict(), '保存路径' )
1 2 模型对象 = 模型类/models中的模型 模型对象.load_state_dict(torch.load('保存路径' ))
上述两种方法都需要在加载前初始化模型结构,或者将带有模型结构的文件导入需要加载的文件中
注意!
如果保存的模型是在GPU上训练的,而加载时的设备却是CPU设备,那么就需要加上参数
1 2 torch.load('保存路径' , map_location=torch.device('CPU' ))
完整的模型训练
完整的模型训练模板为:
加载数据集
输出数据长度(有利于后面根据长度划分batch)
加载DataLoader
构建神经网络(一般处于另一个文件中,使用时导包即可)
创建网络模型对象
创建损失函数
创建优化器
设置网络模型训练参数
(可选)Tensorboard可视化
开始训练(两层循环)
外层为总训练次数
训练
测试(在with torch.no_grad()中包裹,表示仅训练不调参)
内层为循环读取数据进行训练
(可选)保存训练模型
示例代码
文件一:模型文件——Net.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import torchfrom torch.nn import Sequential, Linear, Conv2d, MaxPool2d, Flatten, CrossEntropyLossimport torch.nn as nnclass Net (nn.Module): def __init__ (self ): super (Net, self ).__init__() self .model1 = Sequential( Conv2d(3 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 64 , 5 , padding=2 ), MaxPool2d(2 ), Flatten(), Linear(1024 , 64 ), Linear(64 , 10 ) ) def forward (self, x ): return self .model1(x) if __name__ == '__main__' : test = torch.ones((64 , 3 , 32 , 32 )) net = Net() output = net(test) print (output.shape)
文件二:主文件——Main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 from torch.utils.tensorboard import SummaryWriterimport torchimport torchvisionfrom torch.utils.data import DataLoaderfrom torch.nn import Sequential, Linear, Conv2d, MaxPool2d, Flatten, CrossEntropyLossimport torch.nn as nnfrom Net import * from torch.nn import CrossEntropyLosstrain_set = torchvision.datasets.CIFAR10(root='./data' , train=True , download=True ,transform=torchvision.transforms.ToTensor()) test_set = torchvision.datasets.CIFAR10(root='./data' , train=False , download=True ,transform=torchvision.transforms.ToTensor()) len_train = len (train_set) len_test = len (test_set) print (f'训练数据长度:{len_train} ' ) print (f'测试数据长度:{len_test} ' ) train_loader = DataLoader(train_set, batch_size=64 ) test_loader = DataLoader(test_set, batch_size=64 ) net = Net() ce_loss = CrossEntropyLoss() learning_rate = 0.005 optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate) epoch = 10 writer = SummaryWriter('train_logs' ) for i in range (epoch): train_loss_sum = 0 train_num = 0 test_num = 0 right_num = 0 total_right_num = 0 for imgs, targets in train_loader: out = net(imgs) loss_out = ce_loss(out, targets) optimizer.zero_grad() loss_out.backward() optimizer.step() train_loss_sum += loss_out.item() train_num += 1 print (f'第{i+1 } 次训练结束,LOSS = {train_loss_sum / train_num} ' ) writer.add_scalar('train_loss' , train_loss_sum / train_num, i) test_loss_sum = 0 with torch.no_grad(): for imgs, targets in test_loader: out = net(imgs) loss_out = ce_loss(out, targets) test_loss_sum += loss_out.item() test_num += 1 right_num = (out.argmax(1 ) == targets).sum () total_right_num += right_num print (f'第{i+1 } 次测试结束,LOSS = {test_loss_sum / test_num} ' ) print (f'准确率:{total_right_num / len_test} ' ) writer.add_scalar('test_loss' , test_loss_sum / test_num, i) writer.add_scalar('test_right' , total_right_num / len_test, i) torch.save(net, f'train/net_train{i+1 } .pth' ) writer.close()
补充
分类问题的正确率计算:
由于输出是:
1 2 3 4 5 6 out = ([[0.1 , 0.2 ], [0.3 , 0.4 ]]) target = ([0 , 1 ])
由于out的每一行都匹配一个标签,那么可以取出out每行的最大值,看看是否和标签相同,再使用bool计数:
1 2 3 4 right_num = (out.argmax(1 ) == targets).sum ()
训练和测试注意事项
在之前我们介绍神经网络层时,没有重点关注的两个层是
批标准(归一)化层(BatchNorm)
Dropout层
如果你的网络用了上述的某个层,那么在编写训练和测试的循环代码前,需要加上:
1 2 3 4 5 网络模型对象.train() 网络模型对象.eval ()
就像这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 net = Net() for i in range (epoch): net.train() for imgs, targets in train_loader: ...省略... net.eval () with torch.no_grad(): for imgs, targets in test_loader: ...省略...
使用GPU训练
使用GPU时需要你的环境支持GPU计算
1 2 torch.cuda.is_available()
使用GPU计算很简单,只需要在原代码基础上添加一些东西即可:
对网络模型调用 .cuda()
对损失函数调用 .cuda()
对数据调用 .cuda()
就像这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 net = Net() if torch.cuda.is_available(): net = net.cuda() loss = xxLoss() if torch.cuda.is_available(): loss = loss.cuda() for i in range (epoch): for imgs, targets in train_loader: -> if torch.cuda.is_available(): | imgs = imgs.cuda() -> targets = targets.cuda() out = net(imgs) loss_out = loss(out, targets) ...省略... with torch.no_grad(): for imgs, targets in test_loader: -> if torch.cuda.is_available(): | imgs = imgs.cuda() -> targets = targets.cuda() out = net(imgs) loss_out = ce_loss(out, targets) ...省略...
再优化一下,其实对模型和损失函数不需要再次赋值,直接调用cuda即可
优化后:
1 2 3 4 5 6 7 net = Net() if torch.cuda.is_available(): net.cuda() loss = xxLoss() if torch.cuda.is_available(): loss.cuda()
指定设备训练
如果电脑上有多个设备,而你又需要指定某一个设备进行训练,那么就需要使用以下方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 设备对象 = torch.device('cpu' ) ------------------------- 设备对象 = torch.device('cuda' ) ------------------------- 设备对象 = torch.device('cuda:0' ) ------------------------- 设备对象 = torch.device('cuda:1' ) ------------------------- 设备对象 = torch.device('cuda:2' ) ....以此类推 net.to(设备对象) loss.to(设备对象) imgs = imgs.to(设备对象) targets = targets.to(设备对象)
更建议把定义设备对象写成如下形式
1 2 设备对象 = torch.device('cuda' if torch.cuda.is_available() else 'cpu' )
模型的使用
当你训练了一个良好的模型,是时候将其应用在现实领域了
我们以图像分类为例
一般图片不会和训练时的图片一致,需要将图片转为训练时输入的格式,通过缩放等手段转换
例如:网络图片为:1920*1080的RGBA图片,而训练时的训练数据为 32*32
的RGB图片,那么就需要进行格式转换和缩放
怎么把RGBA转为RGB?
1 图片对象 = 图片对象.convert('RGB' )
有时还需要对图片数据进行维度变换:
例如,训练时输入的数据为:(N, C, H,
W),那么就需要将已经转为Tensor类型的图片数据的维度变为此形式
喂入模型时,也需要套上一层 with torch.no_grad():
1 2 3 net.eval () with torch.no_grad(): output = net(img)
1 output = output.argmax(1 ).item()
案例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import torchfrom torch.nn import Sequential, Linear, Conv2d, MaxPool2d, Flatten, CrossEntropyLossimport torch.nn as nnfrom PIL import Imagefrom torchvision import transformsimg = Image.open ('img.png' ) img1 = Image.open ('img1.png' ) img = img.convert('RGB' ) img1 = img1.convert('RGB' ) transform = transforms.Compose([transforms.Resize((32 , 32 )), transforms.ToTensor()]) img = transform(img) img1 = transform(img1) img = img.reshape(1 , 3 , 32 , 32 ) img1 = img1.reshape(1 , 3 , 32 , 32 ) net = torch.load('train/net_train20.pth' , map_location=torch.device('cpu' )) net.eval () with torch.no_grad(): output = net(img) output1 = net(img1) output = output.argmax(1 ).item() output1 = output1.argmax(1 ).item() dic = {0 : '飞机' , 1 : '汽车' , 2 : '鸟' , 3 : '猫' , 4 : '鹿' , 5 : '狗' , 6 : '青蛙' , 7 : '房子' , 8 : '船' , 9 : '卡车' } print (f'img为:{dic[output]} ' )print (f'img1为:{dic[output1]} ' )
总结
学习 PyTorch
时需要多多查看其官方文档,大多数还是用到什么就去找什么
深度学习框架也需要一些深度学习和机器学习的基础,如果没有了解过,那么也可以去了解,这会对学习框架有很大的帮助
如果文章中有哪些地方错误请留言或者邮箱联系我
Tensorflow 2.0 的入门教程也会速速更新~~~
敬请期待