从0了解机器学习:9——强化学习(完结)
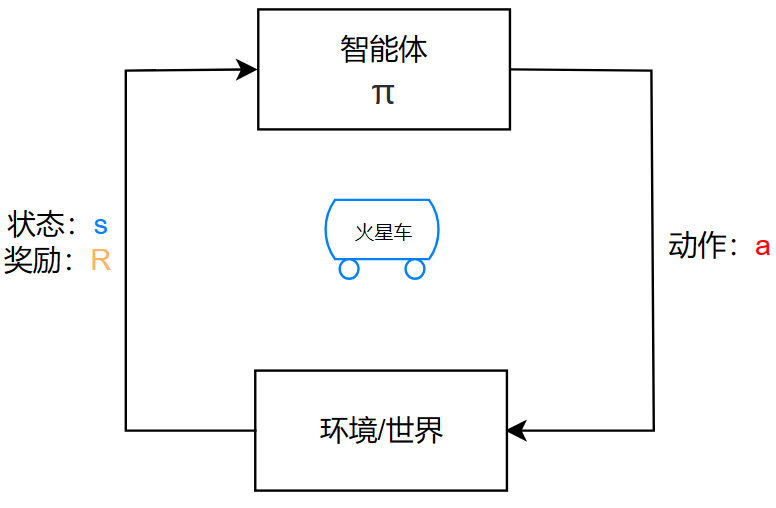
强化学习关注的是智能体(Agent)如何在环境中通过行动来学习策略,以最大化某种累积奖励。
本文章将介绍强化学习,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
强化学习(Reinforcement learning)
强化学习目前并不属于无监督学习,事实上,它已经是机器学习邻域的一个独立的类别
强化学习的灵感来源于人类和动物的学习方式,即通过与环境互动并根据反馈进行学习
强化学习在我们的生活中的应用也广泛
- 机器人(阿尔法狗,机器狗等等)
- 游戏中的人机
- 汽车自动驾驶
- ...
它是如何工作的?
通过给机器/算法一些奖励或惩罚,让机器学习一些事情/动作
就像教小狗坐起来一样,如果小狗听到你的指令,成功坐起来,那么你就会奖励小狗食物,慢慢地,小狗也就学会了你的指令
强化学习区别于其他的机器学习算法:
其他的算法是输入 \(x\) 给出一个输出 \(y\)
而强化学习是给一个状态/位置,让机器学习如何进行下一步的动作
奖励函数(Reward function)
- 正向奖励:直升机成功悬停1秒,奖励:+1
- 负向奖励(惩罚):直升机坠毁,奖励:-1000
这里给出一个例子:火星车
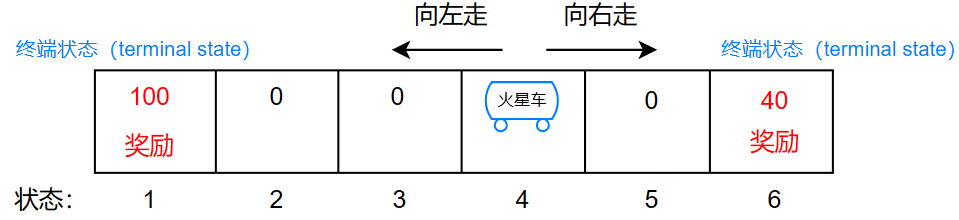
火星车的状态可能是:
4 3 2 1 (终态:可能是一天时间结束或者燃料耗尽)
0 0 0 100
或者:
4 5 6
0 0 40
或者:
4 5 4 3 2 1
0 0 0 0 0 100
我们定义一个状态函数来描绘火星车的状态、奖励、下一步的动作等: \[ (s,a,R(s),s') \]
- \(s\) :当前状态
- \(a\) :当前状态要做的动作
- \(R(s)\) :当前状态的奖励
- \(s'\) :下一时刻的新状态
例如:\((4,\leftarrow,0,3)\)
回报(The return)
回报就是一系列动作的奖励总和: \[
\sum reward
\] 
最左边 100 的奖励固然诱人,但是需要走的距离更远,如何表示距离与奖励之间的关系呢?
折扣因子(Discount factor): \(\gamma\) 一个小于1的数
所有总回报为: \[ Return=R_1+\gamma\cdot R_2+\gamma^2\cdot R_3+...+(直到终端状态) \] 如果 \(\gamma=0.9\) ,则一直向左走的回报为: \[ return=0+(0.9)\times0+(0.9)^2\times0+(0.9)^3\times100=72.9 \] 折扣因子一般设置为:0.9,0.99,0.999...
注意:如果折扣因子过小,那么其对于距离的惩罚越大,则机器人会热衷于”快回报“,不再探索距离更长的地点
- 如果火星车一直向左走,那么各个状态的回报为:( \(\gamma\) =0.5)

- 如果火星车一直向右走,那么各个状态的回报为:( \(\gamma\) =0.5)

- 但是我们不应该每次都只往一个方向走,我们可以根据每个位置的回报来确定下一次走的方向:

一个有趣的事情是:
如果你的奖励存在负值的话,那么算法就会将其推迟到未来
比如:如果你要还给一个人10块钱,在当时看来,这是一个 -10 的收益,但是如果你推迟几年还款,那么几年后的10块钱会比当时值钱,到那时候你还的10块钱就会比当时的10块钱还少一点
决策(Policies)
给定算法不同的决策可能会有不同的结果导向:
- 距离最近的奖励决策:

- 最大奖励决策:

- 最小奖励决策:

- 基于回报的决策:
我们需要定义一个关于动作的函数,通过使用当前状态映射到将来的动作: \[ \pi(s)=a\quad\Rightarrow\quad \pi(2)=\leftarrow\quad \pi(3)=\leftarrow\quad \pi(4)=\leftarrow\quad \pi(5)=\rightarrow\quad \] 其中:
- \(s\) :当前状态
- \(a\) :当前状态要做的动作
这样,一个决策就可以通过方程 \(\pi(s)=a\) 来确定给定的状态 \(s\) 如何做出下一次的动作 \(a\)
所以说,我们应该找到一个决策 \(\pi\) ,能够给出每一个状态 \(s\) 下的下一步动作 \(a\) 使得每一个状态的回报都是最大的
例如:
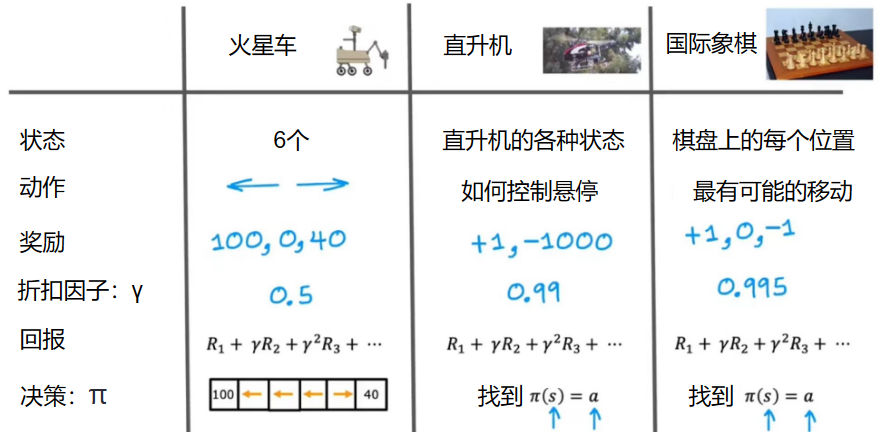
马尔可夫决策(MDP:Markov decision process)
状态动作值函数(State-action value function)
Q 方程(Q-function),有时又称作:Q星方程(Q*-function)或者 最优 Q 函数(optimal Q function)
\(Q(s,a)\) :在一个初始状态 \(s\) 中执行一个具体的动作 \(a\) 之后,按照某一策略进行下去所能够获得的累计折扣奖励的期望值
- $ s$ 表示特点环境下的具体状态
- \(a\) 表示具体状态之下执行的具体动作
例如,在基于回报的决策之下的Q方程:
\(Q(2,\rightarrow)\) :在状态2之下,向右走一步之后达到状态3,之后的每一步都要根据”基于回报”的决策进行,在这期间获得的累计折扣奖励
所以,依据这个决策,那么 \(Q(2,\rightarrow)\) 的完整过程为:
- 从2开始,向右走一步到3
- 根据“基于回报”的决策行动
- 那么在3之下,能够获得最大的回报的动作就是向左走
- 从3向左走到2
- 在2之下,能够获得最大回报的动作就是向左走
- 那么向左走到1,达到终态
- 之后计算之前每一步所获得的折扣奖励,累加起来就是 \(Q(2,\rightarrow)\) 的值
则 \(Q(2,\rightarrow)=0+(0.5)\times0+(0.5)^2\times0+(0.5)^3\times100=12.5\)
那么,同理: \[ Q(2,\leftarrow)=0+(0.5)\times100=50 \] 写下每一个状态之下,进行的每一个动作的 Q 方程:
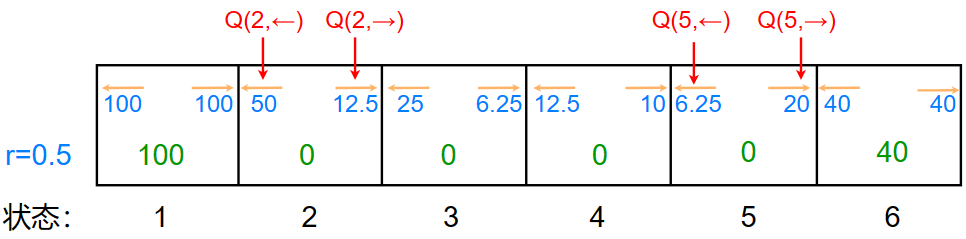
最好的回报是每个状态之下,所有Q方程中的最大值:\(maxQ(s,a)\)
最好的动作是每个状态之下,最大的Q方程中所对应的动作 :\(maxQ(s,a)\rightarrow\pi(s)=a\)
贝尔曼方程(Bellman equation)
回顾之前的定义:
- \(s\) :当前状态
- \(a\) :当前状态要做的动作
- \(R(s)\) :当前状态的奖励
- \(s'\) :下一时刻的新状态
- \(a'\) :下一时刻的新状态要做的动作
那么贝尔曼方程就是状态动作值函数的完整动作描述: \[ Q(s,a)=R(s)+\gamma\cdot maxQ(s',a') \] 解释就是:
Q函数等于:当前状态获得的奖励,加上下一时刻的最好回报
下一时刻的最好回报:下一时刻获得的奖励,加上下下时刻的最好回报
下下一时刻的最好回报:下下一时刻获得的奖励,加上下下下时刻的最好回报
...直到终态
其实就是一个递归的过程

例如: \[ \begin{gather} Q(2,\rightarrow)=R(2)+0.5\times maxQ(3,a') \\ \because\quad maxQ(3,a')=Q(3,\leftarrow) \\ \therefore\quad Q(2,\rightarrow)=R(2)+0.5\times Q(3,\leftarrow) \\ \Downarrow \\ \because\quad Q(3,\leftarrow)=R(3)+\gamma\times maxQ(2,a') \\ \because\quad maxQ(2,a')=Q(2,\leftarrow) \\ \therefore\quad Q(3,\rightarrow)=R(3)+0.5\times Q(2,\leftarrow) \\ \Downarrow \\ \because\quad Q(2,\leftarrow)=R(2)+\gamma\times maxQ(1,a') \\ \because\quad maxQ(1,a')=100\;(终态) \\ \therefore\quad Q(2,\leftarrow)=R(2)+0.5\times 100 \\ \Downarrow 递归\\ Q(2,\rightarrow)=R(2)+0.5\times [R(3)+0.5\times (R(2)+0.5\times 100)] \\ =0+(0.5)\times0+(0.5)^2\times0+(0.5)^3\times100 \\ =12.5 \end{gather} \] 其他的原理相同: \[ \begin{gather} Q(s,a)=R_1+\gamma\cdot R_2+\gamma^2\cdot R_3+\gamma^3\cdot R_4+... \\ =R_1+\gamma\cdot(R_2+\gamma^2\cdot R_3+\gamma^3\cdot R_4+...) \\ \qquad\qquad (maxQ(s',a')) \end{gather} \]
另外,在贝尔曼方程中: \[ Q(s,a)=R(s)+\gamma\cdot maxQ(s',a') \] \(R(s)\) 又被称为:即时奖励
\(\gamma\cdot maxQ(s',a')\) 又被称为:从状态 \(s\) 行动后,依据策略获得的最好回报
随机环境(Random/Stochastic environment)
在现实中,智能体执行一个动作之后,并不一定会达到下一个状态,这是由环境决定的
比如:火星车向左移动之后,有可能火星车正处在斜坡之中,而由于摩擦力不够,有可能向左走10厘米,结果却倒退了20厘米
比如在“最大回报”的决策中:
如果你的火星车正处在状态4,依据决策,你将向左走,但是有这些情况:
- 你很幸运,火星车如期执行所有的动作
- 你的位置变化:4—>3—>2—>1
- 有点不幸运,在执行动作时稍微打滑了
- 你的位置变化:4—>3—>2—>3(打滑从2滑到3)—>2—>1
- 这次很不幸,一开始就打滑了
- 你的位置变化:4—>5(打滑从4滑到5)—>6
那么我们期待的回报应该是随机的,因为环境的影响也是随机的
所以应该对执行一个动作可能会出现的所有情况所得到的回报取平均值: \[ \begin{gather} Expected\;\;Return=Average(R_1+\gamma\cdot R_2+\gamma^2\cdot R_3+\gamma^3\cdot R_4+...) \\ =E(R_1+\gamma\cdot R_2+\gamma^2\cdot R_3+\gamma^3\cdot R_4+...) \end{gather} \] 所以最终的贝尔曼方程为: \[ Q(s,a)=R(s)+\gamma\cdot E[maxQ(s',a')] \]
连续状态空间应用
离散空间VS连续空间:
- 离散空间:
- 连续空间:
- 汽车:

则该汽车的状态为: \[ s= \begin{bmatrix} x \\ y \\ \theta \\ \dot{x} \\ \dot{y} \\ \dot{\theta} \end{bmatrix} \] 其中头上有点的表示该变量的变化速度(类似于加速度)
例如:
\(\dot{x}\) :表示在 x 轴上的变化速度
\(\dot{\theta}\) :表示角度的变化速度
- 连续空间
- 直升机
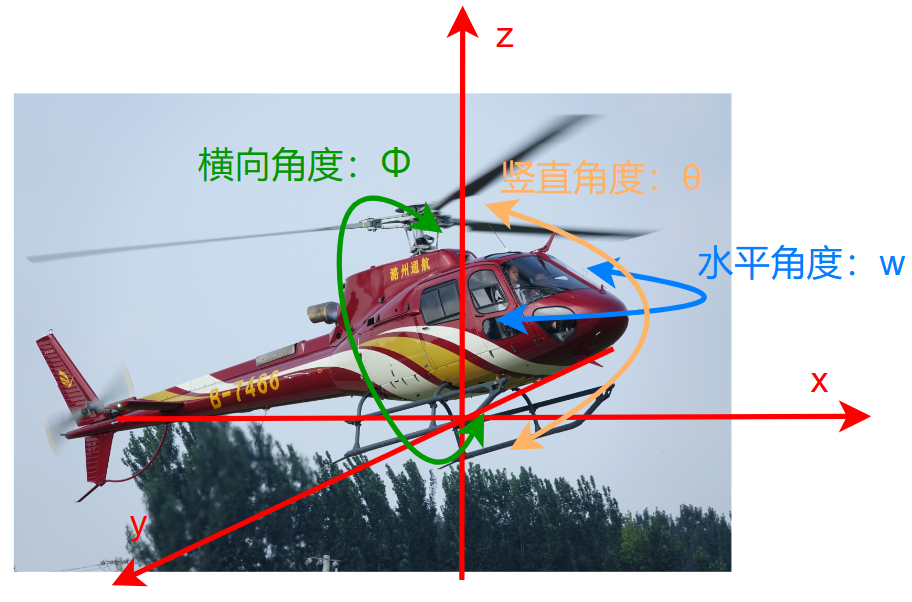
则该直升机的状态为: \[ s= \begin{bmatrix} x \\ y \\ z \\ \phi \\ \theta \\ \omega \\ \dot{x} \\ \dot{y} \\ \dot{z} \\ \dot{\phi} \\ \dot{\theta} \\ \dot{\omega} \end{bmatrix} \]
月球着陆器
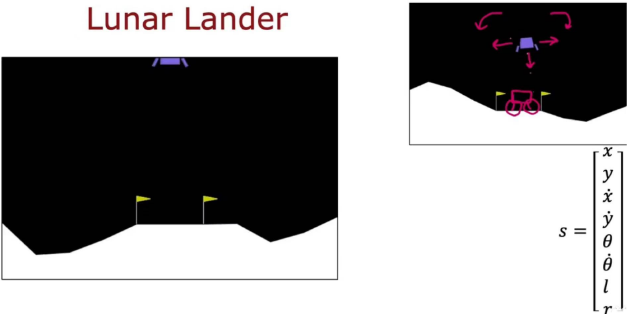
其中:
\(\theta\) :着陆器旋转的角度
\(l\) :着陆器是否左脚着地
\(r\) :着陆器是否右脚着地
奖励函数:
- 在着陆点着陆:+100~140
- 靠近着陆点或远离着陆点:适当加分或减分
- 坠毁:-100
- 软着陆:+100
- 每只脚着陆:+10
- 开启缓冲发动机:-0.3
- 开启左/右发动机:-0.03
对于状态,一共8个状态: \[ s= \begin{bmatrix} x \\ y \\ \dot{x} \\ \dot{y} \\ \theta \\ \dot{\theta} \\ l \\ r \end{bmatrix} \] 选取折扣因子:\(\gamma=0.985\)
动作有4种:不动(nothing)、开启左发动机(left)、开启右发动机(right)、开启缓冲发动机(main)
学习状态动作值函数
输入为:\((s,a)\) 一共12个输入
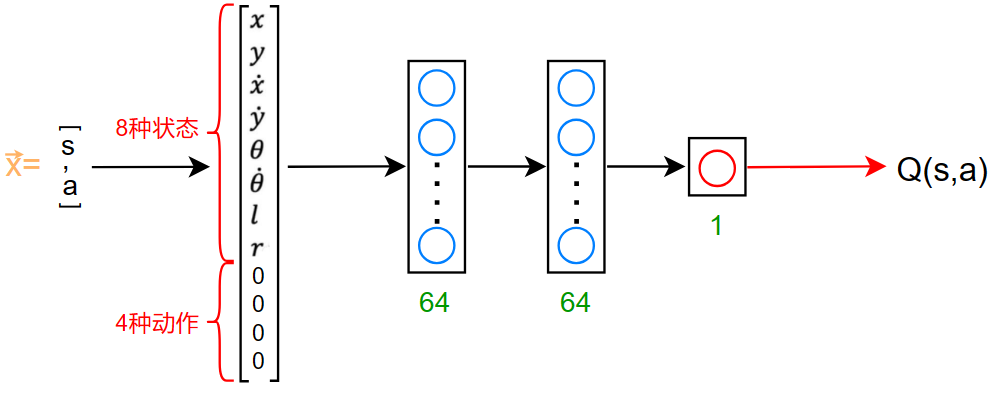
在某一状态 \(s\) 中,使用神经网络计算所有的动作: \[ Q(s,nothing)\qquad Q(s,left)\qquad Q(s,right)\qquad Q(s,main) \] 获取此时满足 \(maxQ(s,a)\) 的动作 \(a\) 作为此状态即将要做的动作
如何获取训练集呢?
在其他机器学习算法中,我们一般会让预测值逐渐逼近标准值: \[ f_{w,b}(x)\approx y \]
其中的训练数据:
x:输入
y:标准答案
而在这里,我们使用贝尔曼方程: \[ Q(s,a)=R(s)+\gamma\cdot maxQ(s',a') \] 其中:
\(Q(s,a)\) :输入,相当于x
\(R(s)+\gamma\cdot maxQ(s',a')\) :标准答案,相当于y
那么我们就可以控制月球着陆器进行模拟,让他在随机的位置 \(s\) 做随机的动作 \(a\) 即使这些动作可能不是最佳的
我们可能进行了几万次的模拟,最后获得了一系列数据,数据的格式就像: \[ (s,a,R(s),s') \] 这个式子之前讲过:
- \(s\) :当前状态
- \(a\) :当前状态要做的动作
- \(R(s)\) :当前状态的奖励
- \(s'\) :下一时刻的新状态
而这些数据: \[ \begin{gather} (s^{(1)},a^{(1)},R(s^{(1)}),s'^{(1)}) \\ (s^{(2)},a^{(2)},R(s^{(2)}),s'^{(2)}) \\ (s^{(3)},a^{(3)},R(s^{(3)}),s'^{(3)}) \\ . \\ . \\ . \\ (s^{(n)},a^{(n)},R(s^{(n)}),s'^{(n)}) \end{gather} \] 其中的每个元组,都可以组成一对训练数据: \[ \begin{gather} x^{(1)}=(s^{(1)},a^{(1)}) \\ x^{(2)}=(s^{(2)},a^{(2)}) \\ x^{(3)}=(s^{(3)},a^{(3)}) \\ . \\ . \\ . \\ x^{(n)}=(s^{(n)},a^{(n)}) \\ \\ y^{(1)}=R(s^{(1)})+\gamma\cdot maxQ(s'^{(1)},a') \\ y^{(2)}=R(s^{(2)})+\gamma\cdot maxQ(s'^{(2)},a') \\ y^{(3)}=R(s^{(3)})+\gamma\cdot maxQ(s'^{(3)},a') \\ . \\ . \\ . \\ y^{(n)}=R(s^{(n)})+\gamma\cdot maxQ(s'^{(n)},a') \end{gather} \] 学习过程:
初始化神经网络的所有参数,作为函数 \(Q(s,a)\) 的猜测
重复以下过程:
- 使用月球着陆器进行模拟,随机采取行动,获得数据 \((s,a,R(s),s')\)
- 存储最近模拟的 10000 个 \((s,a,R(s),s')\) 元组数据(重放缓冲区:Replay buffer)
- 训练神经网络:
- 使用之前的 10000 个元组数据构建训练集:\(x=(s,a)\qquad y=R(s)+\gamma\cdot maxQ(s',a')\)
- 训练预测输出 \(Q_{new}\) 使得:\(Q_{new}(s,a)\approx y\) (类似于其他模型的 \(f_{w,b}(x)\approx y\) )
- 赋值:\(Q=Q_{new}\) (这里的 \(Q\) 就是一开始初始化参数时的猜测的 \(Q(s,a)\) )
改进学习过程
之前的神经网络只有一个输出,对于四种动作,每个动作都需要单独进行推理计算
我们可以改进神经网络,使得其可以直接输出四种动作的Q值
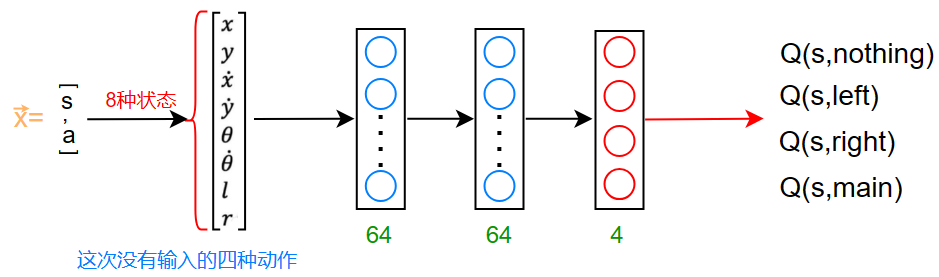
这次我们输入的只有状态 \(s\) ,且直接输出当前状态做出四种动作的Q函数的值
这样就可以直接从输出的四个值中选择一个作为当前状态 \(s\) 需要进行的动作 \(a\)
\(\epsilon\) - 贪婪策略( \(\epsilon\) - greedy policy)
在之前的策略中,我们都是这样:
- 进行的动作 \(a\) 都是能够使得 \(Q(s,a)\) 最大
而这样会导致一个问题,如果智能体发现某一个动作能够一直给他奖励,那么智能体就会重复做一个动作
没有智能体该有的探索性
而 \(\epsilon\) -贪婪策略就是让智能体有自我探索的能力
现在改进策略为:
- 有 0.95 的概率:进行的动作 \(a\) 都是能够使得 \(Q(s,a)\) 最大 (贪婪)
- 有 0.05 的概率:进行一个随机动作 \(a\) (探索)
这里的 0.05 就是 \(\epsilon\) 的值
也就是这个 \(\epsilon\) -贪婪策略的 \(\epsilon=0.05\)
在应用时,可以以一个很高的 \(\epsilon\) 作为开始,之后随着时间的推移逐渐降低 \(\epsilon\) 的值
比如从 1 开始 逐渐降低到 0.01
小批量和软更新(Mini batch and Soft updates)
小批量
这个操作同样广泛应用在监督学习中
例如有这样的数据:
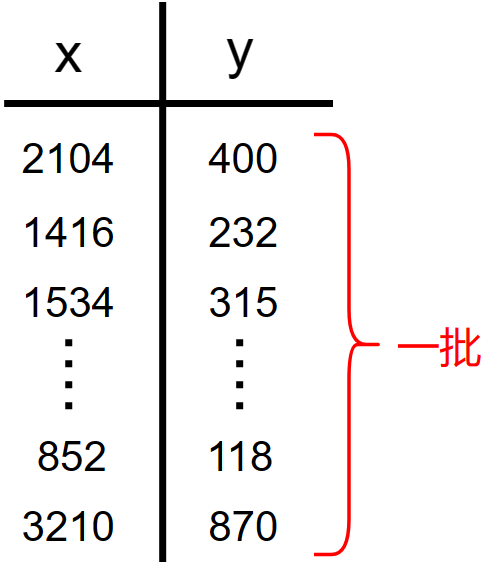
如果使用回归的损失函数: \[ J(w,b)=\frac{1}{2m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)})^2 \] 我们知道:公式中的 \(m\) 是训练数据的数量
那么如果 \(m\) 的值非常大,比如:\(m=100000000\)
那么在梯度下降参数更新时: \[ \begin{gather} w=w-lr\cdot \frac{\partial}{\partial w}\frac{1}{2m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)})^2 \\ b=b-lr\cdot \frac{\partial}{\partial b}\frac{1}{2m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)})^2 \end{gather} \] 我们发现更新公式里有常数项:\(\frac{1}{2m}\)
如果 \(m\) 的值非常大,那么这个常数项就会非常小,这就导致参数更新得很慢,每次循环,参数就只更新了 0.0000001 甚至更少
这样会极大地减慢梯度下降的速度,花费的时间也会变得很长
所以在小批量中:
我们可以设置新的训练集的子集 \(m'=1000\) 或者其他值(这个值要远小于原始数据集的数量)
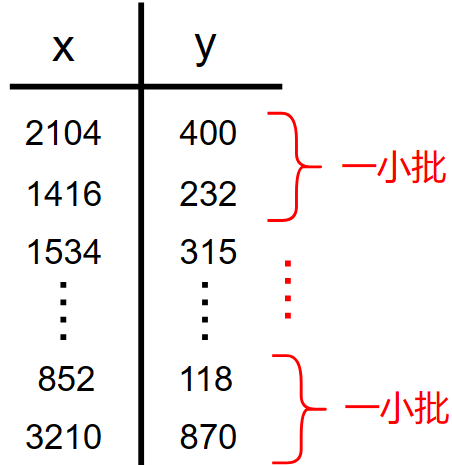
并且参数更新公式中的 \(m\) 全部替换为 \(m'\) : \[ \begin{gather} w=w-lr\cdot \frac{\partial}{\partial w}\frac{1}{2m'}\sum_{i=1}^{m'}(f_{w,b}(x^{(i)})-y^{(i)})^2 \\ b=b-lr\cdot \frac{\partial}{\partial b}\frac{1}{2m'}\sum_{i=1}^{m'}(f_{w,b}(x^{(i)})-y^{(i)})^2 \end{gather} \] 但是小批量有一个缺点:
由于一次训练的数据不是整个数据集,那么就会出现局部拟合
在原来的大批量数据集中,算法能够一次学习所有的数据以及数据的趋势或特征
而在小批量中,每一次学习,都只是学习到数据中的一部分,导致算法无法很快参透数据的趋势或特征。
比如:第一次学习,算法则拟合第一批数据,但是一旦第二批数据和之前的第一批数据的特征差距比较大,那么算法就只能重新拟合第二批的数据,导致梯度下降不稳定
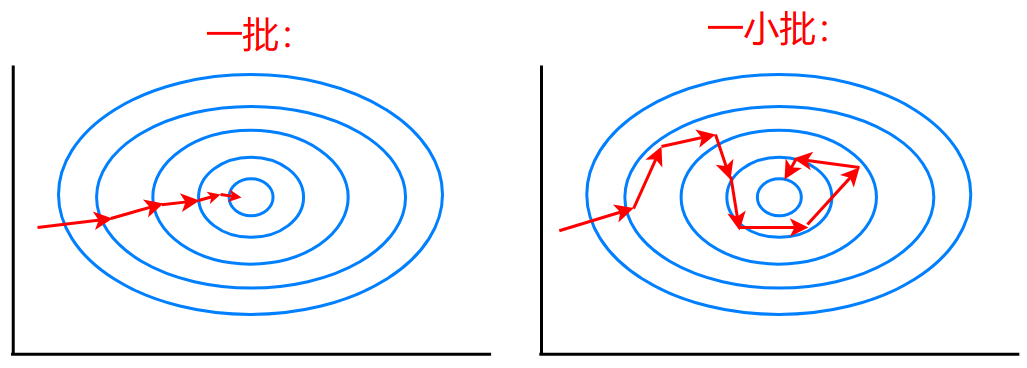
当然,实际的波动还是很小的,图中只是为了体现这种波动性,画的夸张了
而在之前的强化学习中,我们也可以使用小批量:
初始化神经网络的所有参数,作为函数 \(Q(s,a)\) 的猜测
重复以下过程:
- 使用月球着陆器进行模拟,随机采取行动,获得数据 \((s,a,R(s),s')\)
- 存储最近模拟的 10000 个 \((s,a,R(s),s')\) 元组数据(重放缓冲区:Replay buffer)
- 训练神经网络:
- 使用之前的 \(\bcancel{10000}\;\rightarrow\;1000\) 个元组数据构建训练集:\(x=(s,a)\qquad y=R(s)+\gamma\cdot maxQ(s',a')\)
- 训练预测输出 \(Q_{new}\) 使得:\(Q_{new}(s,a)\approx y\) (类似于其他模型的 \(f_{w,b}(x)\approx y\) )
- 赋值:\(Q=Q_{new}\) (这里的 \(Q\) 就是一开始初始化参数时的猜测的 \(Q(s,a)\) )
软更新
在前面的强化学习中,最后一步:
- 赋值:\(Q=Q_{new}\) (这里的 \(Q\) 就是一开始初始化参数时的猜测的 \(Q(s,a)\) )
如果你的 \(Q_{new}\) 这次训练得不好,那么当 \(Q=Q_{new}\) 时,那么你的神经网络将会有一个糟糕的噪声
你可以这样设置: \[ \begin{gather} Q\rightarrow w,b \\ Q_{new}\rightarrow w_{new},b_{new} \\ w=0.01\cdot w_{new}+0.99\cdot w \\ b=0.01\cdot b_{new}+0.99\cdot b \end{gather} \] 也就是不那么快地将新的数值更新,而是每一次都更新一点点,防止某一次出错,导致网络中存在噪声
具体每一次更新多少,这个自己决定
强化学习的现状
- 尽管强化学习在实验室环境中取得了显著成就,但在实际硬件上的部署仍然面临许多挑战,包括实时性能、硬件兼容性和安全性等问题
- 强化学习被越来越多地应用于复杂的大规模系统中,比如自动驾驶汽车、机器人控制和游戏AI等领域,但是其应用仍然比监督学习和无监督学习更少
- 现如今,机器学习的理论基础仍然在不断完善中,正处于一个快速发展且充满潜力的阶段
后话
恭喜你完成了机器学习的基础理论知识!!!这一路走来,相信你一定不容易,为自己鼓个掌吧
我也希望你今后能够从事机器学习的相关工作或者研究,毕竟要对得起你这段时间的努力!
我们的机器学习之旅可以告一段落了
之后我会抓紧更新其他内容:
深度学习基础知识
深度学习框架:PyTorch、TensorFlow2.0
...
敬请期待吧...
不过在更新这些内容之前的一段时间,我也会更新一些其他的内容,具体是什么,我只能说,看我当时的兴趣吧,哈哈哈...
从0了解机器学习:9——强化学习(完结)