从0了解机器学习:8——推荐系统
推荐系统在商业领域的关注甚至远远超过了学术界,其实际应用在我们生活中无处不在
本文章将介绍无监督学习中的推荐系统,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
推荐系统(Recommender system)
让我们举一个例子来开始我们的推荐系统之旅:
预测电影评分
用户使用1~5颗星来表示电影的喜爱程度
| 电影(纯虚构) | 1、张三 | 2、李四 | 3、王五 | 4、赵六 |
|---|---|---|---|---|
| 1、最后的爱 | 5 | 5 | 0 | 0 |
| 2、永远浪漫 | 5 | ? | ? | 0 |
| 3、可爱小狗 | ? | 4 | 0 | ? |
| 4、永不停歇 | 0 | 0 | 5 | 4 |
| 5、剑与勇士 | 0 | 0 | 5 | ? |
定义以下变量:
- \(n_u\) :用户数量
- \(n_m\) :电影数量
- \(r(i,j)\) :如果用户 \(j\) 对电影 \(i\) 进行了评分则为 1 反之为 0
- \(y^{(i,j)}\) :用户 \(j\) 给电影 \(i\) 的评分(前提是 \(r(i,j)=1\) )
则对于上面的表格来说: \[ \begin{gather} n_u=4\qquad n_m=5\qquad \\ r(1,1)=1\qquad r(3,1)=0\qquad y^{(3,2)}=4 \end{gather} \] 那么我们需要电影的什么特征呢?
我们可以一些小于1的数表示某类型在某电影中的占比
| 电影(纯虚构) | 1、张三 | 2、李四 | 3、王五 | 4、赵六 | \(x_1\) (浪漫类) | \(x_2\) (动作类) |
|---|---|---|---|---|---|---|
| 1、最后的爱 | 5 | 5 | 0 | 0 | 0.9 | 0 |
| 2、永远浪漫 | 5 | ? | ? | 0 | 1.0 | 0.01 |
| 3、可爱小狗 | ? | 4 | 0 | ? | 0.99 | 0 |
| 4、永不停歇 | 0 | 0 | 5 | 4 | 0.1 | 1.0 |
| 5、剑与勇士 | 0 | 0 | 5 | ? | 0 | 0.9 |
此时对于这个表格来说:
\(n_u=4\)
\(n_m=5\)
\(n=2\) :表示电影的特征数,表中只有浪漫和动作两种特征
那么第一部电影的特征就是:\(x^{(1)}=\begin{bmatrix}0.9 \\ 0 \end{bmatrix}\) 以此类推
对于用户 1 来说,他对电影 \(i\) 的评分预测为:\(w^{(1)}\cdot x^{(i)}+b^{(1)}\)
如果: \[ w^{(1)}= \begin{bmatrix} 5 \\ 0 \end{bmatrix} \qquad b^{(1)}=0\qquad x^{(3)}= \begin{bmatrix} 0.99 \\ 0 \end{bmatrix} \] 那么第一个用户对电影 3 的评分预测为: \[ w^{(1)}\cdot x^{(3)}+b^{(1)}=4.95 \] 所以说,预测用户 \(j\) 对电影 \(i\) 的评分为: \[ w^{(j)}\cdot x^{(i)}+b^{(j)} \]
损失函数
定义变量:
- \(r(i,j)\) :如果用户 \(j\) 对电影 \(i\) 进行了评分则为 1 反之为 0
- \(y^{(i,j)}\) :用户 \(j\) 给电影 \(i\) 的评分(前提是 \(r(i,j)=1\) )
- \(w^{(j)},b^{(j)}\) :用户 \(j\) 的参数
- \(x^{(i)}\) :电影 \(i\) 的特征向量
预测用户 \(j\) 对电影 \(i\) 的评分为: \[ w^{(j)}\cdot x^{(i)}+b^{(j)} \]
- \(m^{(j)}\) :用户 \(j\) 已经评分的电影数量
目标是学习用户参数:\(w^{(j)},b^{(j)}\)
对于用户 \(j\) 损失函数: \[ \begin{gather} min \\ w^{(j)},b^{(j)} \end{gather} J(w^{(j)},b^{(j)})=\frac{1}{2m^{(j)}}\sum_{i:r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2m^{(j)}}\sum_{k=1}^n(w_k^{(j)})^2 \] 由于 \(m^{(j)}\) 是常数,可以同时去除
以上是对于单个用户的损失函数
而对于所有的用户参数:\((w^{(1)},b^{(1)}),(w^{(2)},b^{(2)}),...,(w^{(n_u)},b^{(n_u)})\) 的损失函数为: \[ J \begin{pmatrix} w^{(1)},...,w^{(n_u)} \\ b^{(1)},...,b^{(n_u)} \end{pmatrix} =\frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(w_k^{(j)})^2 \] 但是有一个问题,我们哪来的特征呢: 就像这样
| 电影(纯虚构) | 1、张三 | 2、李四 | 3、王五 | 4、赵六 | x_1 (浪漫类) | x_2 (动作类) |
|---|---|---|---|---|---|---|
| 1、最后的爱 | 5 | 5 | 0 | 0 | ? | ? |
| 2、永远浪漫 | 5 | ? | ? | 0 | ? | ? |
| 3、可爱小狗 | ? | 4 | 0 | ? | ? | ? |
| 4、永不停歇 | 0 | 0 | 5 | 4 | ? | ? |
| 5、剑与勇士 | 0 | 0 | 5 | ? | ? | ? |
我们可以假设我们已经获得了用户的参数:\(w^{(1)},...,w^{(n_u)};b^{(1)},...,b^{(n_u)}\)
假设我们有了 \(w,b\) : \[ \begin{gather} w^{(1)}= \begin{bmatrix} 5 \\ 0 \end{bmatrix} \quad w^{(2)}= \begin{bmatrix} 5 \\ 0 \end{bmatrix} \quad w^{(3)}= \begin{bmatrix} 0 \\ 5 \end{bmatrix} \quad w^{(4)}= \begin{bmatrix} 0 \\ 5 \end{bmatrix} \quad \\ b^{(1)}=0\qquad b^{(2)}=0\qquad b^{(3)}=0\qquad b^{(4)}=0\qquad \end{gather} \] 使用公式:\(w^{(j)}\cdot x^{(i)}+b^{(j)}\) \[ \begin{gather} w^{(1)}\cdot x^{(1)}+b^{(1)}\approx5 \\ w^{(2)}\cdot x^{(1)}+b^{(2)}\approx5 \\ w^{(3)}\cdot x^{(1)}+b^{(3)}\approx0 \\ w^{(4)}\cdot x^{(1)}+b^{(4)}\approx0 \end{gather} \quad\Rightarrow\quad x^{(1)}= \begin{bmatrix} 1 \\ 0 \end{bmatrix} \] 以此类推,求出所有的特征
协同过滤(Collaborative filtering)
给定参数 \(w,b\) 去学习特征 \(x^{(i)}\) \[ J(x^{(i)})=\frac{1}{2}\sum_{j:r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{k=1}^n(x_k^{(i)})^2 \] 上述公式是对于单个特征 \(x^{(i)}\) 而言
那么对于所有特征 \(x^{(1)},...,x^{(n_m)}\) 来说,损失函数: \[ J(x^{(1)},...,x^{(n_m)})=\frac{1}{2}\sum_{j=1}^{n_u}\sum_{j:r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_m}\sum_{k=1}^n(x_k^{(i)})^2 \] 到了这里为止,我们给出了学习特征的损失函数,那么这个函数是在假设已知 \(w,b\) 的情况下得到的
那么 \(w,b\) 怎么获取呢?
事实上,之前我们就已经得到了 \(w,b\) 的损失函数,我们可以把它们一起进行训练
这是 \(w,b\) 的: \[ J \begin{pmatrix} w^{(1)},...,w^{(n_u)} \\ b^{(1)},...,b^{(n_u)} \end{pmatrix} =\frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(w_k^{(j)})^2 \] 把这两个损失函数放到一起: \[ J \begin{pmatrix} w^{(1)},...,w^{(n_u)} \\ b^{(1)},...,b^{(n_u)} \\ x^{(1)},...,x^{(n_m)} \end{pmatrix} =\frac{1}{2}\sum_{(i,j):r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(w_k^{(j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_m}\sum_{k=1}^n(x_k^{(i)})^2 \] 这样,特征与参数一起学习,就是协同过滤
参数更新: \[ \begin{gather} w_i^{(j)}=w_i^{(j)}-lr\cdot\frac{\partial }{\partial w_i^{(j)}}J(w,b,x) \\ b^{(j)}=b^{(j)}-lr\cdot\frac{\partial }{\partial b^{(j)}}J(w,b,x) \\ x_k^{(i)}=x_k^{(i)}-lr\cdot\frac{\partial }{\partial x_k^{(i)}}J(w,b,x) \end{gather} \] 其中的 \(x\) 也作为参数一起更新
二进制标签(Binary label)
二进制标签,比如:点击、点赞、订阅、关注、收藏等
| 电影(纯虚构) | 1、张三 | 2、李四 | 3、王五 | 4、赵六 |
|---|---|---|---|---|
| 1、最后的爱 | 1 | 1 | 0 | 0 |
| 2、永远浪漫 | 1 | ? | ? | 0 |
| 3、可爱小狗 | ? | 1 | 0 | ? |
| 4、永不停歇 | 0 | 0 | 1 | 1 |
| 5、剑与勇士 | 0 | 0 | 1 | ? |
表格中的
- 1:喜欢
- 0:不喜欢
- ?:未观看
许多的二进制标签其实都是类似的:
- 用户 \(j\) 在首页商品展示后购买了吗?(1,0,?)
- 用户 \(j\) 喜欢这个商品吗?(1,0,?)
- 用户 \(j\) 在这个商品花费了30秒以上时间吗?(1,0,?)
- 用户 \(j\) 点击这个商品了吗?(1,0,?)
这些分数的含义:
- 1:在商品展示之后进行正向操作
- 0:在商品展示后没有进行正向操作/进行负向操作
- ?:商品还没有给用户展示
商品其实也可以是视频、图片、博客、文章等
损失函数
二进制标签的损失函数其实和二分类的类似,都是用交叉熵
之前的损失函数为: \[ J \begin{pmatrix} w^{(1)},...,w^{(n_u)} \\ b^{(1)},...,b^{(n_u)} \\ x^{(1)},...,x^{(n_m)} \end{pmatrix} =\frac{1}{2}\sum_{(i,j):r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(w_k^{(j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_m}\sum_{k=1}^n(x_k^{(i)})^2 \] 而二进制标签的激活函数为: \[ f_{(w,b,x)}(x)=g(w^{(j)}\cdot x^{(i)}+b^{(j)})=\frac{1}{1+e^{-(w^{(j)}\cdot x^{(i)}+b^{(j)})}} \] 而单个用户的损失函数也变为: \[ L(f_{(w,b,x)}(x),y^{(i,j)})=-y^{(i,j)}\cdot log(f_{(w,b,x)}(x))-(1-y^{(i,j)})\cdot log(1-f_{(w,b,x)}(x)) \] 对于所有的用户,损失函数为: \[ J(w,b,x)=\sum_{(i,j):r(i,j)=1}L(f_{(w,b,x)}(x),y^{(i,j)}) \]
均值归一化(Mean normalization)
如果一个新用户,没有给任何一部电影评过分:
| 电影(纯虚构) | 1、张三 | 2、李四 | 3、王五 | 4、赵六 | 5、二麻子 |
|---|---|---|---|---|---|
| 1、最后的爱 | 5 | 5 | 0 | 0 | ? |
| 2、永远浪漫 | 5 | ? | ? | 0 | ? |
| 3、可爱小狗 | ? | 4 | 0 | ? | ? |
| 4、永不停歇 | 0 | 0 | 5 | 4 | ? |
| 5、剑与勇士 | 0 | 0 | 5 | ? | ? |
由于新用户没有进行评分所以他的 \(r(i,j)=0\) ,而对于损失函数: \[ J \begin{pmatrix} w^{(1)},...,w^{(n_u)} \\ b^{(1)},...,b^{(n_u)} \\ x^{(1)},...,x^{(n_m)} \end{pmatrix} =\frac{1}{2}\sum_{(i,j):r(i,j)=1}(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(w_k^{(j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_m}\sum_{k=1}^n(x_k^{(i)})^2 \] \(r(i,j)=0\) 意味着损失函数的第一项失效,而此时损失函数只剩下 \(w,x\) 的正则化项,那么它就会一直对 \(w\) 进行最小化,最后 \(w\) 很可能等于0,并且 \(b\) 也很大概率等于0
而带入评分预测的函数中 \(w^{(j)}\cdot x^{(i)}+b^{(j)}\) 中,就会发现评分等于0
一个新用户不可能对每一个电影都打0分,这是不寻常的
使用均值归一化: \[ \begin{gather} M= \begin{bmatrix} 5\quad5\quad0\quad0\quad? \\ 5\quad?\quad?\quad0\quad? \\ ?\quad4\quad0\quad?\quad? \\ 0\quad0\quad5\quad4\quad? \\ 0\quad0\quad5\quad0\quad? \end{bmatrix} \qquad 求出每行均值\Rightarrow\qquad \mu= \begin{bmatrix} 2.5 \\ 2.5 \\ 2 \\ 2.25 \\ 1.25 \end{bmatrix} \\ M-\mu= \begin{bmatrix} 2.5\quad2.5\quad-2.25\quad-2.25\qquad? \\ 2.5\qquad?\;\qquad?\qquad-2.25\qquad? \\ ?\qquad2\qquad-2\quad\qquad?\quad\qquad? \\ -2.25\quad-2.25\quad2.75\quad1.75\qquad? \\ -1.25\quad-1.25\quad3.75\quad-1.25\quad? \end{bmatrix} \end{gather} \] 最后得到的 \(M-\mu\) 就是新的 \(y^{(i,j)}\)
对于用户 \(j\) 对于电影 \(i\) 的预测值为: \[ w^{(j)}\cdot x^{(i)}+b^{(j)}+\mu_i \] 加上的 \(\mu_i\) 是为了让预测结果为正值
那么对于新用户 二麻子 他的预测值为: \[ w^{(5)}= \begin{bmatrix} 0 \\ 0 \end{bmatrix} \quad b^{(5)}=0 \qquad w^{(5)}\cdot x^{(1)}+b^{(5)}+\mu_i=2.5 \] 让新用户的评分为均值,这起码比预测新用户评分全为0更为合理
同时,均值归一化也会加快算法的运行速度
此外,协同过滤算法一般不会使用神经网络,因为协同过滤算法不能很好地拟合进神经网络里
寻找相关特征(Finding related items)
在之前的内容里,我们提到了一个电影的特征 \(x^{(i)}\) ,比如:爱情片,动作片
但是这些特征都是我们人为加以解释的,就像神经网络一样,可能算法它并不知道,这个特征代表什么含义
所以说,通过特征的含义寻找相似的电影,或者相似的特征是比较困难的
其实我们可以使用之前聚类算法的原理,如果两个对象是相似的,那么他们的特征也应该是相似的,也就是说,他们的对应特征值的差值不会太大,这样就好办了
为了找到和对象 \(i\) 相似的特征的对象 \(k\) ,只需要这样做:将二者的特征作差并平方 \[ \sum_{l=1}^n(x_l^{(k)}-x_l^{(i)})^2\quad\Leftrightarrow\quad|| x_l^{(k)}-x_l^{(i)} ||^2 \] 只需要找到特征之间距离最短的,那么他们就是相似的
冷启动问题:
- 怎么给一个刚刚发布的,几乎没有人评分的内容进行排名?
- 怎么给一个只评分很少内容的用户推荐内容?
可以使用一些附加信息来加以优化:
- 对于内容来说:可以根据发布内容的作者,工作室,甚至IP地址作为特征
- 对于用户来说:可以根据用户的性别,年龄,地址,如果可以获取用户的其他信息,这样也可以(隐私协议)
基于内容的过滤(Content-based filtering)
协同过滤算法:
向你推荐那些别人评分和你相似的内容
基于内容过滤算法:
基于你个人的特征和内容的特征向你推荐(个性化)
定义变量:
\(r(i,j)\) :用户 \(j\) 对内容 \(i\) 进行了评分,则为1,反之为0
\(y^{(i,j)}\) :用户 \(j\) 给内容 \(i\) 的评分(前提是 \(r(i,j)=1\) )
用户特征:
- 年龄
- 性别
- 国家
- 已观看的电影数
- ...
用户特征使用 \(x_u^{(j)}\) 表示用户 \(j\) 的个人特征
电影(内容)特征:
- 年份
- 类型
- 评论
- 平均分
- ...
电影特征使用 \(x_m^{(i)}\) 表示电影 \(i\) 的特征
对于 \(x_u^{(j)},x_m^{(i)}\) 来说,其向量的尺寸可以不同
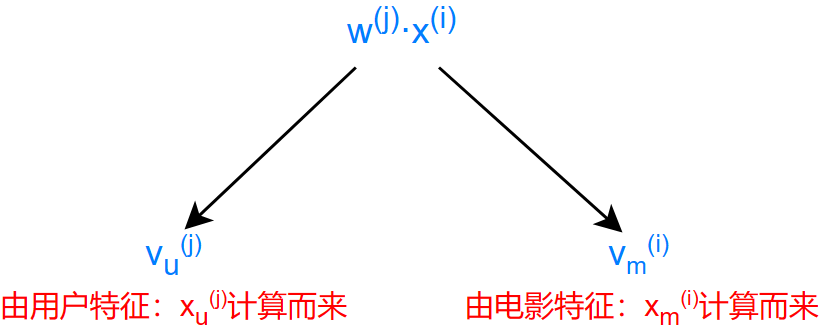
预测用户 \(j\) 对电影 \(i\) 的评分:
使用评分预测函数:\(w^{(j)}\cdot x^{(i)}+b^{(j)}\)
这里我们可以去除 \(b^{(j)}\) ,事实上,这样做不会影响算法
 \[
用户偏好:v_u=
\begin{bmatrix}
4.9 \\
0.1 \\
. \\
. \\
. \\
3.0
\end{bmatrix}
\qquad
电影特征:v_m=
\begin{bmatrix}
4.5 \\
0.2 \\
. \\
. \\
. \\
3.5
\end{bmatrix}
\] 通过计算 \(v_u\cdot v_m\)
来获得预测值
\[
用户偏好:v_u=
\begin{bmatrix}
4.9 \\
0.1 \\
. \\
. \\
. \\
3.0
\end{bmatrix}
\qquad
电影特征:v_m=
\begin{bmatrix}
4.5 \\
0.2 \\
. \\
. \\
. \\
3.5
\end{bmatrix}
\] 通过计算 \(v_u\cdot v_m\)
来获得预测值
注意: 两向量 \(v_u,v_m\) 的尺寸是相同的
那么,怎么将两个尺寸不相同的向量 \(x_u^{(j)},x_m^{(i)}\) 转化为尺寸相同的向量 \(v_u,v_m\) 呢?
基于内容过滤的深度学习(DL for content-based filtering)
为了将两个尺寸不相同的向量 \(x_u^{(j)},x_m^{(i)}\) 转化为尺寸相同的向量 \(v_u,v_m\) ,深度学习是一个好的选择
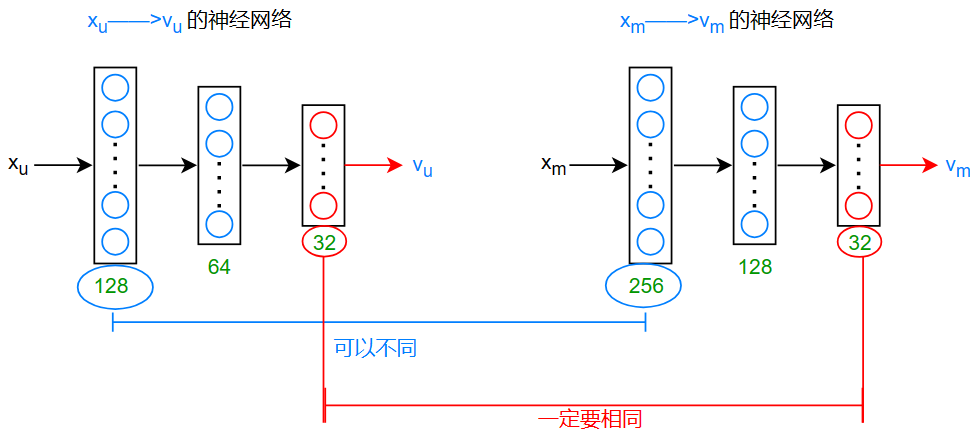
预测:\(v_u\cdot v_m\) (预测评价的分数)
如果要预测一个二进制标签:喜欢、收藏、订阅等:
那么可以使用 sigmoid 函数作为激活函数:\(g(v_u^{(j)}\cdot v_m^{(i)})\)
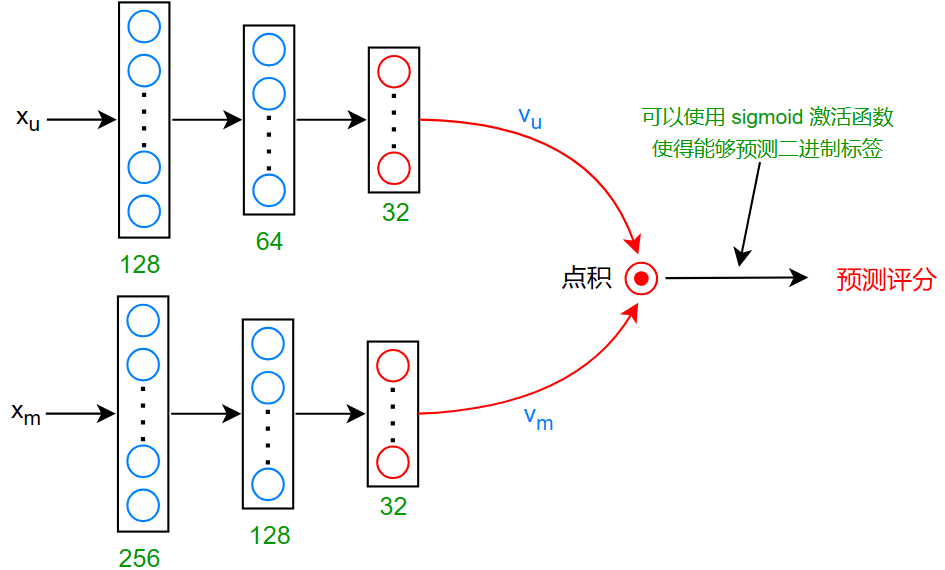
损失函数: \[ J=\sum_{(i,j):r(i,j)=1}(v_u^{(j)}\cdot v_m^{(i)}-y^{(i,j)})^2+正则化项 \] 查找相关内容(电影):
\(v_u^{(j)}\) 是一个大小为32的,描述用户特征 \(x_u^{(j)}\) 的向量
\(v_m^{(j)}\) 是一个大小为32的,描述电影特征 \(x_m^{(j)}\) 的向量
去查找与电影 \(i\) 相关的电影 \(k\) : \[ || v_m^{(k)}-v_m^{(i)} ||^2 \] 使得上述式子最小的电影 \(k\) 就是与电影 \(i\) 相关的电影
如果在现实应用中,一般可以通过夜间运行计算服务器来计算(更新)这些特征,以便第二天给用户更好的推荐体验
从大型目录中推荐(Recommending from a large catalogue)
在应用时,我们会遇到从成百万上千万的内容中选出极少数几个内容进行推荐
- 数以百万的音乐?
- 数以千万的广告?
- 数以百万的电影?
- 数以亿的商品?
如果这些数据全部进入神经网络:
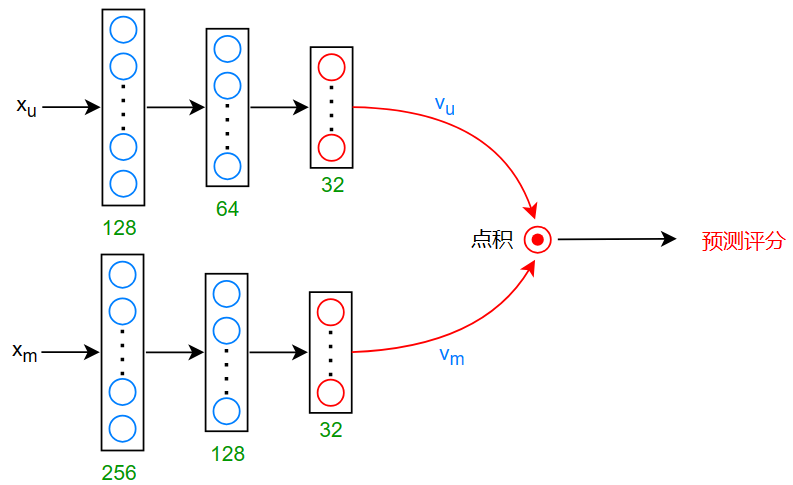
那么神经网络就会进行数以千万数以亿计的推理计算,如果每次新用户登录的话,计算这些将变得不可能
为了解决这个问题,我们一般有两个步骤:检索和排名
检索(Retrieval) :生成大量的用户可能感兴趣(也许有讨厌的)的内容列表,例如:
- 选出用户最后观看过的10部电影,找出与这些电影相似的电影
- 对于用户经常观看的3种类型,找出这三种类型电影中,平均评分最高的10部电影
- 用户所在国家/地区排名前20的电影
上述的例子也可更换为商品,文章,视频等等
通过以上的步骤(也可以根据情况,添加一些检索的步骤)你大概可以找到数百个电影
虽然听起来也挺多的,但是对于百万,千万甚至是亿来说,根本不算什么
找出的这数百个电影之后,再进行去重,并移除用户已经观看过的电影
剩下的电影就可以进入下一步:
排名(Ranking)
- 将这数百个电影与用户特征输入神经网络中计算
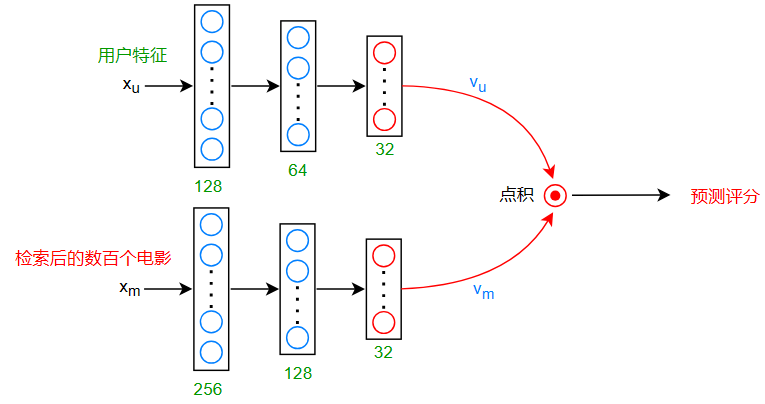
- 计算出各个电影对于用户的预测评分后,将这些电影的评分进行排名,选出排名最高的几个电影进行推荐
当然,就像之前提到的,如果你在夜晚就已经将所有的电影的特征计算好了,那么在输入神经网络的时候,就只需要执行用户特征的计算即可
当然,检索步骤中,检索越多的内容可能会在推荐内容时表现得更好,但是这也会使得推荐的速度变慢
总结
本文章讲了无监督学习中的推荐系统,同时也讲了一些其他概念:协同过滤等
在接下来,我们将开始学习一个特殊的机器学习算法——强化学习(Reinforcement learning)
强化学习目前已经作为单独的一类机器学习领域
从0了解机器学习:8——推荐系统