从0了解机器学习:7——异常检测
本文章将介绍无监督学习中的异常检测,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
异常检测(Anomaly detection)
异常检测常常用于生产中的残次品检测和金融交易中的欺诈检测等等
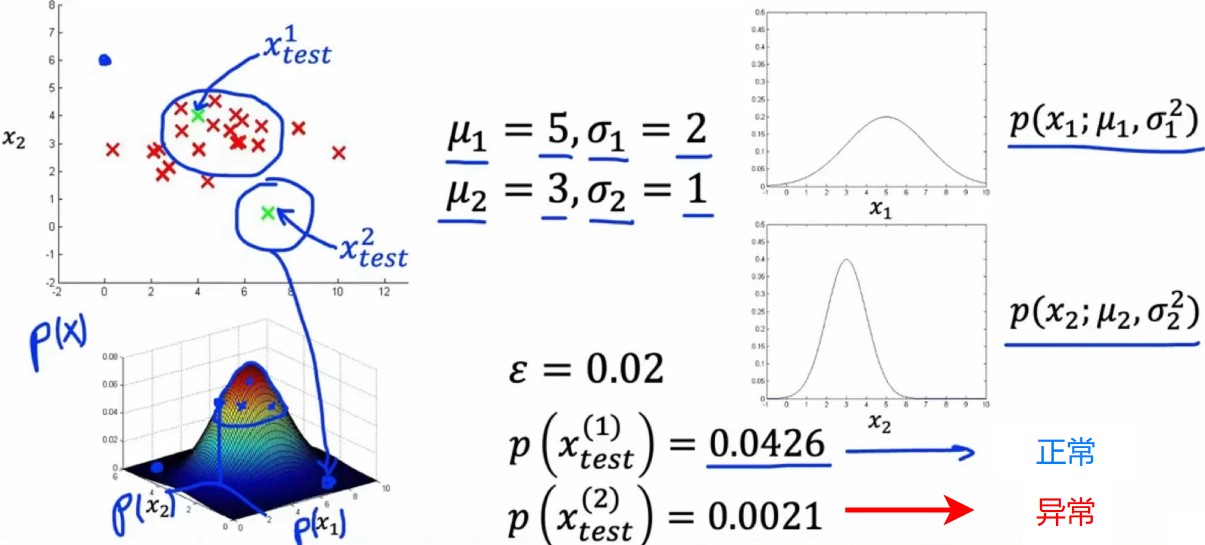
这里举出一个生产飞机引擎的例子:
飞机引擎的特征:
- \(x_1\) = 产生的热量
- \(x_2\) = 震动强度
- ...
数据集:\(\{x^{(1)},x^{(2)},...,x^{(m)} \}\)
刚刚生产出的引擎为:\(x_{test}\)

高斯(正态)分布(Gaussian/Normal distribution )
正态分布的函数表达式为: \[ p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x-\mu)^2}{x\sigma^2}} \]
函数图像为:
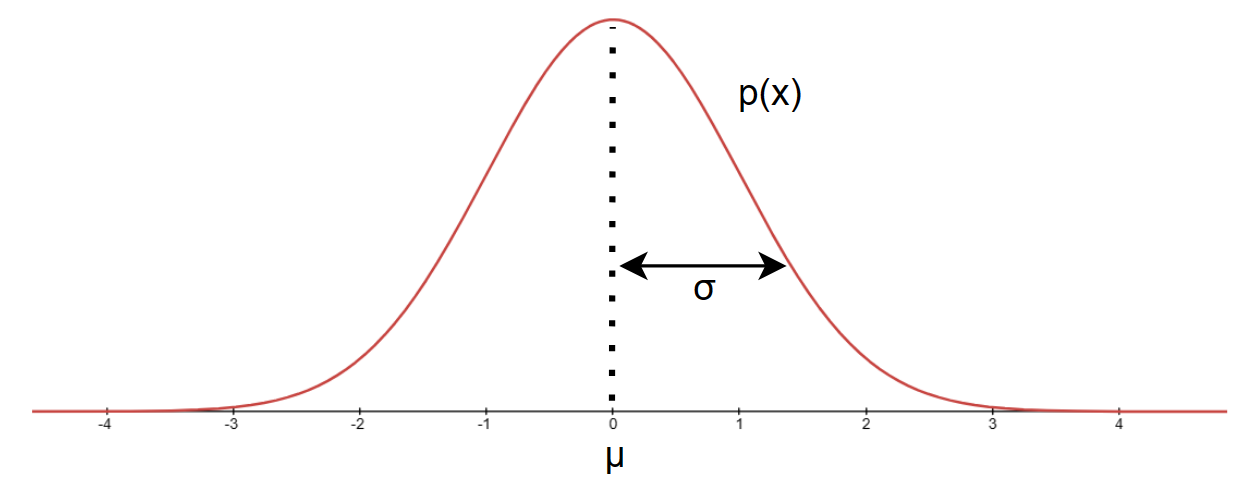
对于数据集:\(\{x^{(1)},x^{(2)},...,x^{(m)} \}\) :
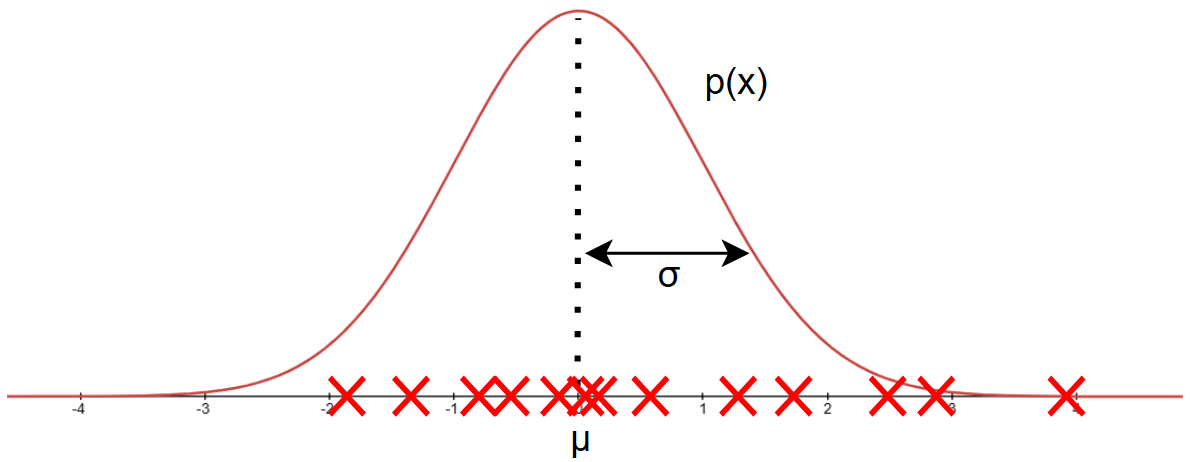
其中: \[ \mu=\frac{1}{m}\sum_{i=1}^mx^{(i)}\qquad \sigma^2=\frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)^2 \] 如果学过数理统计可能见过样本方差的分母为:\(m-1\)
但是这对于机器学习来说,二者几乎没有什么区别
异常检测算法
我们有训练集:\(\{x^{(1)},x^{(2)},...,x^{(m)} \}\)
每个训练集都有 n 个特征: \[ x^{(i)}= \begin{bmatrix} x_1 \\ x_2 \\ . \\ . \\ . \\ x_n \end{bmatrix} \] 对于单个 \(x^{(i)}\) 我们有: \[ p(x^{(i)})=p(x_1;\mu_1,\sigma_1^2)\cdotp p(x_2;\mu_2,\sigma_2^2)\cdotp p(x_3;\mu_3,\sigma_3^2)\cdot...\cdotp p(x_n;\mu_n,\sigma_n^2) \] 在统计学中,如果把式子写成这样,也就是默认了这些特征之间相互独立
事实上,这些特征并不一定相互独立,但在机器学习中这样做,算法依然能够很好地工作
以上式子可以简写为: \[ p(x^{(i)})=\prod_{j=1}^np(x_j;\mu_j,\sigma_j^2) \] 什么意思呢?
比如一个飞机引擎,工作时非常热的概率为:\(\frac{1}{10}\) 而非常振动的概率为:\(\frac{1}{20}\)
那么飞机引擎工作时既非常热又非常振动的概率为:\(\frac{1}{10}\times\frac{1}{20}=\frac{1}{200}\)
算法的执行过程:
- 对于每一个数据 \(x^{(i)}\) 选择 n 个你认为会影响正常性的特征
- 拟合参数 \(\mu_1,...,\mu_n;\sigma_1^2,...,\sigma_n^2\)
- 使用公式:\(\mu_j=\frac{1}{m}\sum_{i=1}^mx^{(i)}\qquad \sigma_j^2=\frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)^2\)
- 参数都可以使用向量表示,例如:\(\vec{\mu}=\frac{1}{m}\sum_{i=1}^m\vec{x}^{(i)}=\begin{bmatrix}\mu_1 \\ \mu_2 \\ . \\ .\\ . \\ \mu_n\end{bmatrix}\)
- 给定一个新的示例 \(x\) 计算其 \(p(x)\) :
- \(p(x^{(i)})=\prod_{j=1}^np(x_j;\mu_j,\sigma_j^2)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}e^{\frac{-(x_j-\mu_j)^2}{x\sigma_j^2}}\)
- 如果 \(p(x)<\epsilon\) 认定为异常(具体小于多少自定义)
实数评估(Real-number evaluation)
怎么去评估一个异常检测算法?
- 假设我们有一些带标签的数据,既有正常也有异常数据(正常:y=0,异常:y=1)
- 训练集:\(x^{(1)},x^{(2)},...,x^{(m)}\) (训练集中只含有正常数据,也就是训练集标签都是 y=0)
等一下!!!
Q:怎么有标签了,难道这也是无监督学习?
A:你说的对,因为在训练集中,所有的数据都只有一个标签,换句话说,每个数据都是一样的标签,那不就是等同于没有标签了吗,所以还是可以看作无监督学习
- 验证:
- 使用交叉验证集:\((x_{cv}^{(1)},y_{cv}^{(1)},...,(x_{cv}^{(m_{cv})},y_{cv}^{(m_{cv})})\)
- 测试集:\((x_{test}^{(1)},y_{test}^{(1)},...,(x_{test}^{(m_{test})},y_{test}^{(m_{test})})\)
交叉验证集和测试集中都有少量的异常数据(y=1)
注意:
即使在训练集中含有异常数据也不要紧,算法也可以很好地工作(也就是数据本身是异常数据,但是标签为正常数据的标签 y=0)
我们使用飞机引擎作为例子:
正常引擎数据:10000个 标签为 y=0 的引擎数据
异常引擎数据:20个 标签为 y=1 的异常引擎数据
划分数据集:
训练集:6000个全为正常引擎的数据(y=0)
交叉验证集:2000个正常引擎数据(y=0)和 10 个异常引擎数据(y=1)
测试集:2000个正常引擎数据(y=0)和 10 个异常引擎数据(y=1)
可选操作:如果异常引擎数据很少的话
训练集:6000个全为正常引擎的数据(y=0)
交叉验证集:4000个正常引擎数据(y=0)和 20个 (或者更少,比如:2个)异常引擎数据(y=1)
测试集:没有测试集
在交叉验证集/测试集中的数据 \(x\) 预测为: \[ y= \begin{cases} 1\qquad if\quad p(x)<\epsilon\;(异常) \\ 0\qquad if\quad p(x)\geq\epsilon\;(正常) \end{cases} \] 可以使用一些评估手段:混淆矩阵,精确率和召回率,F1-score等
同时也可以使用交叉验证集来选择参数 \(\epsilon\)
选择合适的特征
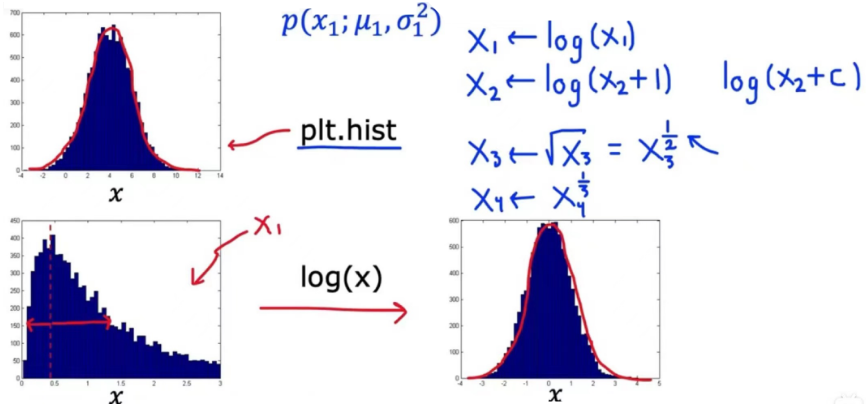
在异常检测算法中,我们应该尽量避免那些 非正态分布的数据
如何将非正态分布数据变成正态分布的数据呢?
进行数学变换:
- 使用对数
- 使用开根号等等
如果在使用算法时出现以下情况:
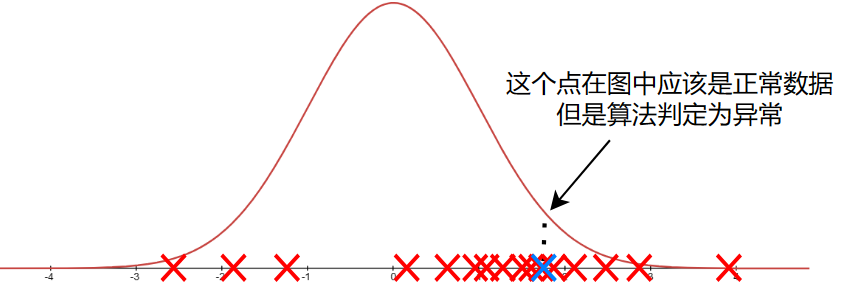
你会觉得这是算法出错了吗?
事实上,出现这样的错误,看起来是算法的问题,但是有可能是出现了新的未发现的异常或特征
例如:
在金融交易中检测机器人:
如果我们只有一个特征:交易数量
那么函数看起来可能会像上图一样:

此时假设我们引入了另一个特征:操作速度
那么重新描述这些数据,可能是这样:
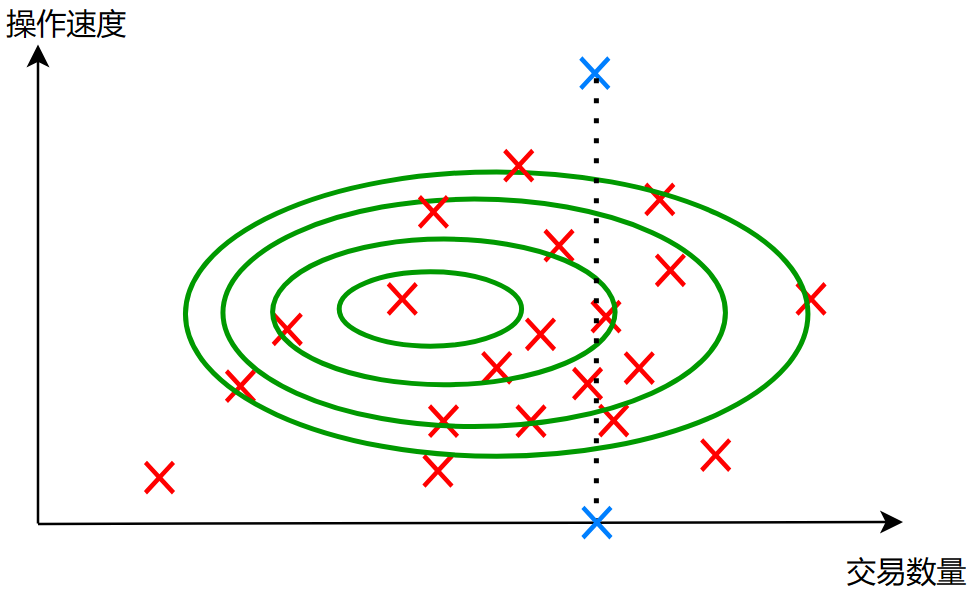
在之前只有一个特征的时候,这个蓝色的数据看起来是正常的,但是我们加入一个操作速度的特征时,我们发现这个数据的操作速度快的飞起,根本不是一个正常人有的操作速度,所以说算法将其判断为异常
所以说,当我们发现有这些类似的问题时,可能是出现了新的异常或者可以加入一个新的特征
异常检测VS监督学习
对于异常检测来说:
在训练方面:异常检测可以在拥有很少的异常数据(<20),和大量的正常数据下进行训练
算法方面:
异常检测可以对于那些人类很难发现的异常进行检测
并且一些异常我们可能现在不能发现,但是如果在未来,一旦我们之前没有发现的异常出现了,异常检测算法也能迅速地找出
它常常能够发现没有被人们发现的异常,这对于一些领域是有用的
应用:
金融交易的欺诈检测
- 人们往往只能对那些已经被曝光的骗局进行防范,但是聪明的人们总是擅长发明新的金融欺诈手段,而异常检测模型就十分擅长发现人们之前从未见过的异常,即使在训练这个模型时,没有这样的训练数据出现,但它就是可以发现
数据中心的数据异常检测
对于监督学习来说:
在训练方面:可能需要大量的正常和异常数据
算法方面:
大量的数据训练,使得监督学习能够敏锐地发现与训练时的异常数据相似的异常
但是对于那些没有经过训练的异常数据,监督学习往往不能很容易地发现
应用:
垃圾邮件分类
天气预测,疾病预测
关键区别:
- 异常检测:善于发现那些未被发现异常,或者未来可能会出现但是现在没有出现的异常
- 监督学习:善于检测那些已经被发现的异常,对于未被发现的异常显得乏力
总结
本文章讲了无监督学习中的异常检测,同时也讲了一些其他概念:实数评估等
在接下来,我们将开始学习无监督学习中的第三个算法——推荐系统(Recommender system)
从0了解机器学习:7——异常检测