从0了解机器学习:6——聚类
本文章将介绍无监督学习中的聚类,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
聚类(Clustering)
在监督学习的分类中,我们是这样的:
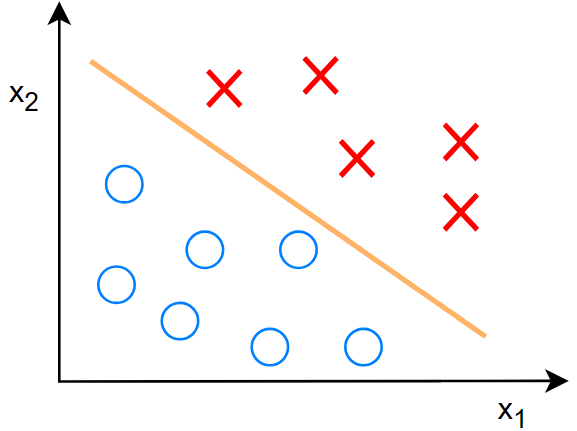
对于训练集:\(\{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),(x^{(3)},y^{(3)}),...\}\) :
每一个输入都有对应的标签,在图中反映为不同的颜色
而在无监督学习中:
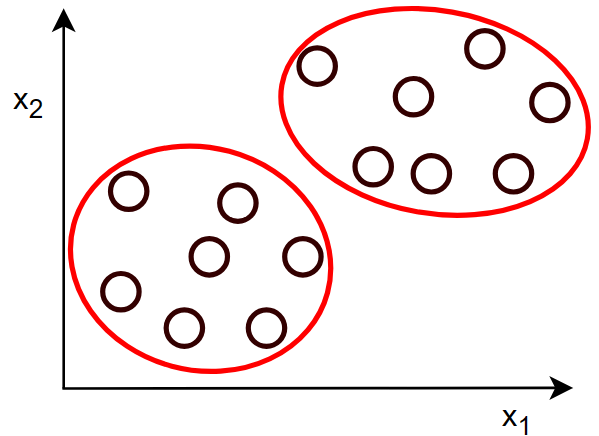
对于训练集:\(\{x^{(1)},x^{(2)},x^{(3)},x^{(4)},... \}\) :
没有标签,在图中反映为数据都是同样的颜色
目标是找出数据中的一些有趣的东西或者规律,像图中的就是将两簇数据聚为两类,也就是聚类
聚类的具体应用在之前的文章《从0了解机器学习:1——机器学习的基本分类》中有提到,这里不做赘述
K-means
这是在聚类中使用最广泛的算法,让我们看看是怎么实现的
这里给出一个例子:
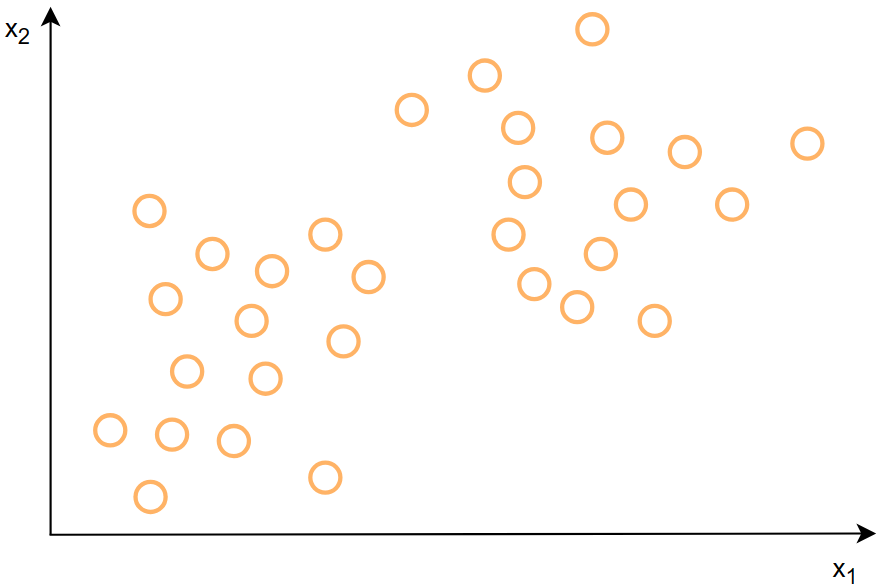
上图是一堆数据的分布,怎么将左下和右上两类数据进行聚类呢
我们可以先在图上随机生成两个点,这两个点作为两簇数据的中心,让这个点自己去找他们的同类
这两个点可以称为:簇质心(cluster centroid)
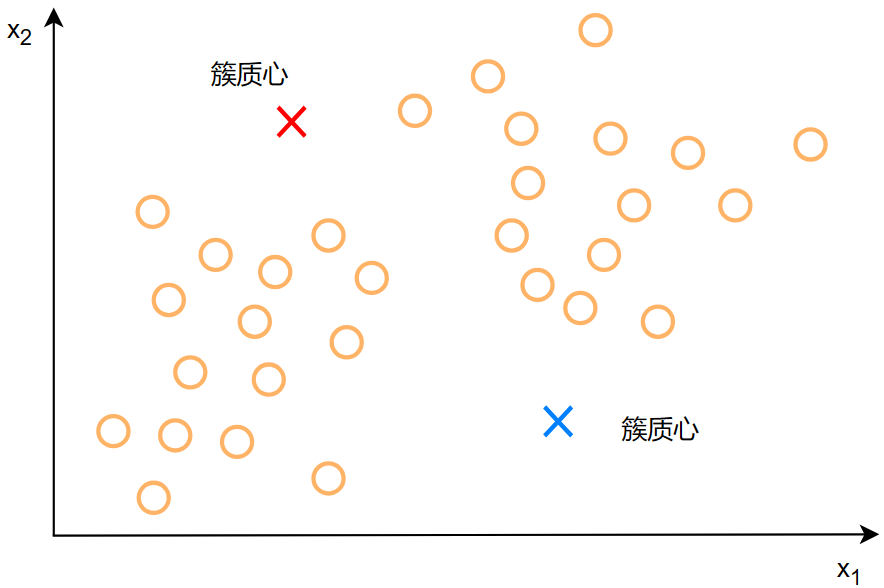
怎么找到他们各自的同伴呢,正所谓“远乡不如近邻”,我们可以看看这些点,哪些离他们近就把近的点归为他们的同类
所以,计算每个点到两个簇质心的距离,将二者中最短的点标记为其同类:
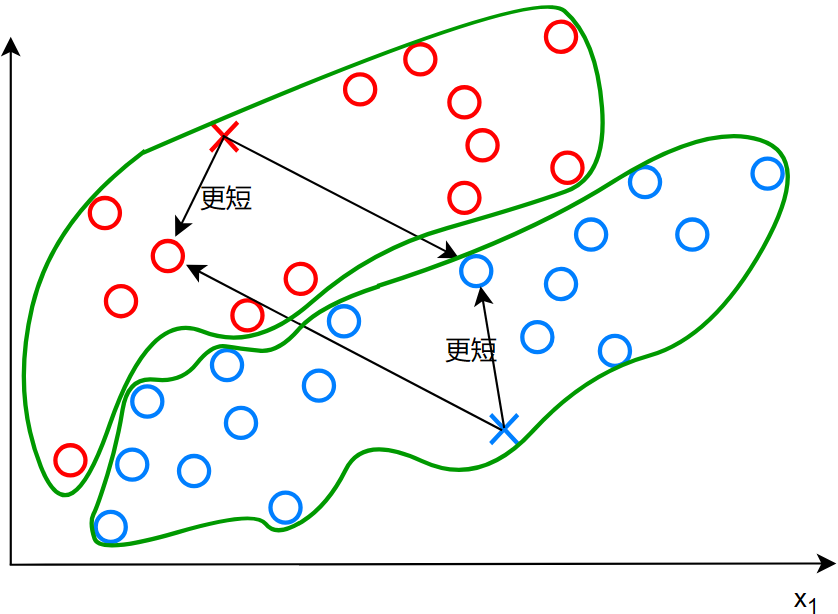
标记好同类之后,此时两个簇质心向着各自同类的质心移动:
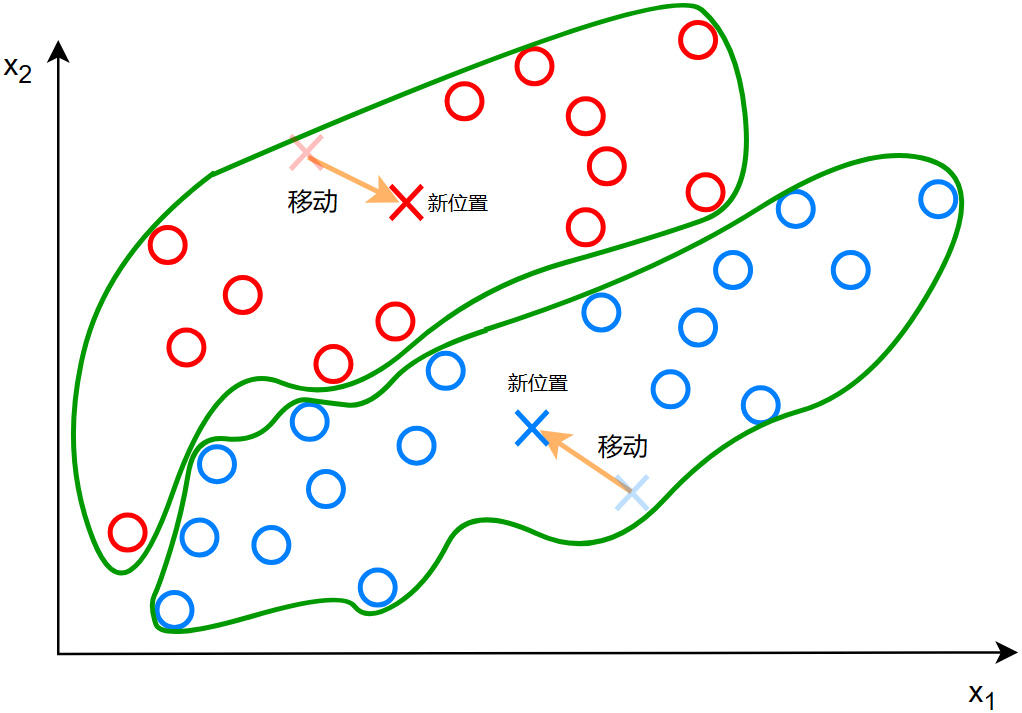
移动之后,重新计算所有点到簇质心的距离,取最短的距离标记为同类:
标记好同类之后,两个簇质心继续向着各自同类的质心移动:
移动之后,重新计算所有点到簇质心的距离,取最短的距离标记为同类:
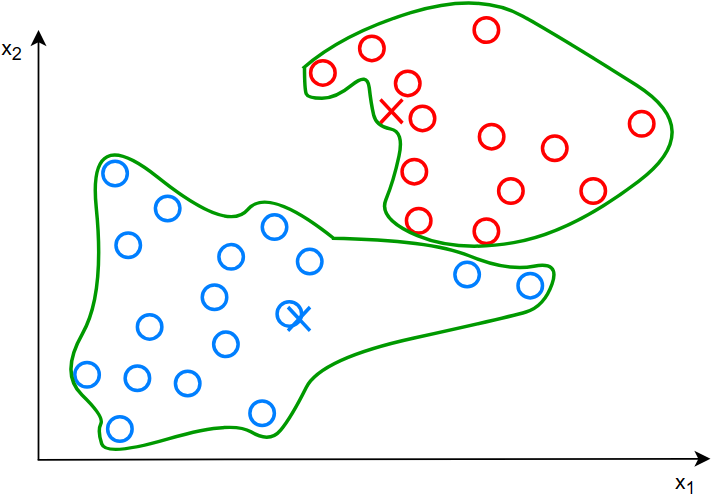
标记好同类之后,两个簇质心继续向着各自同类的质心移动
移动之后,重新计算所有点到簇质心的距离,取最短的距离标记为同类
重复上述操作后,得到最终图像为:
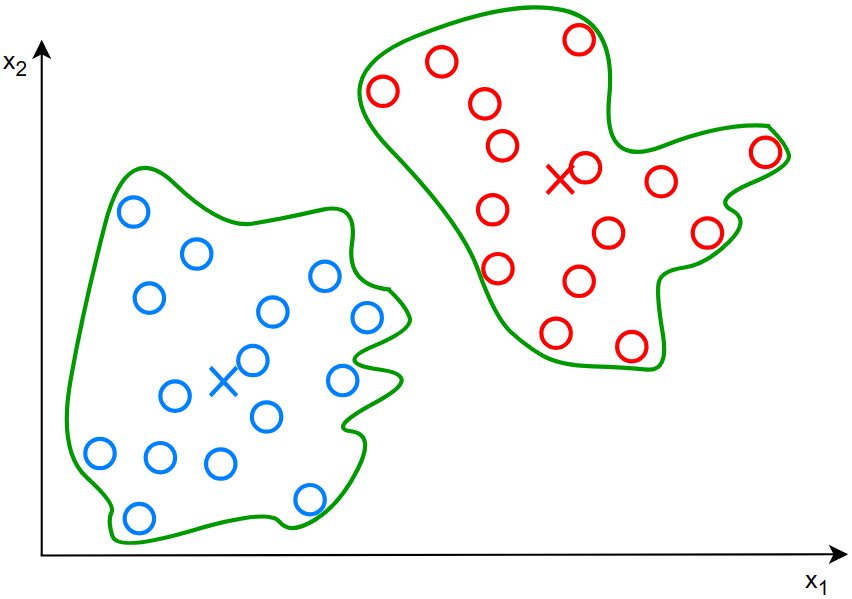
简单来说,上述这个算法就是:
- 随机两个簇质心
- 计算各个点到他们的距离,将最短的点标记为同类
- 移动簇质心到新的质心
- 重复2、3步骤
K-means算法
数据集有 \(m\) 个点,随机初始化 \(K\) 个簇质心:\(\mu_1,\mu_2,\mu_3,...,\mu_k\)
重复以下步骤:
- 分配各个数据点给每个簇质心
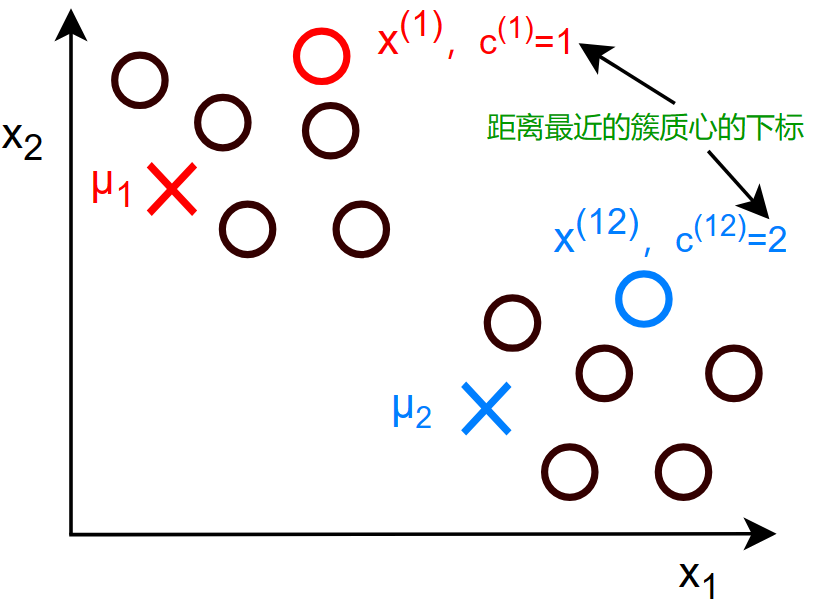
- 从1~m 个数据点:\(c^{(i)}:=\) 离数据点 \(x^{(i)}\) 最近的簇质心的下标(1~k)
- \(c^{(i)}:=min_k|| x^{(i)}-\mu_k ||^2\qquad(L_2范数)\)
- 移动簇质心
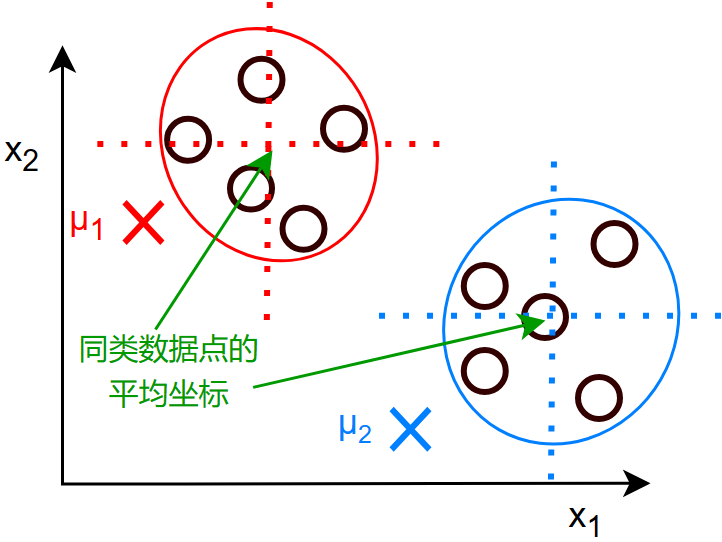
- 从1~k 个簇质心:\(\mu_k:=\) 分配给簇质心k的点的平均值(就是同类数据点的对应坐标值相加取平均值)
- 例如:\(\mu_1=\frac{1}{4}(x^{(1)}+x^{(5)}+x^{(6)}+x^{(10)})\) 其中的 \(x\) 都是含有两个数 \((x_1,x_2)\) 的向量
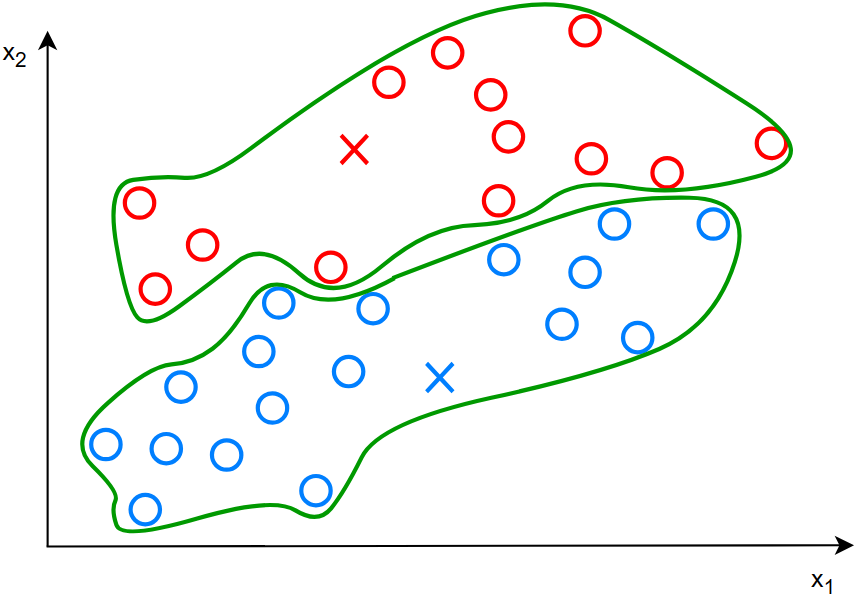
对于第一步的图解:
分配各个数据点给每个簇质心:
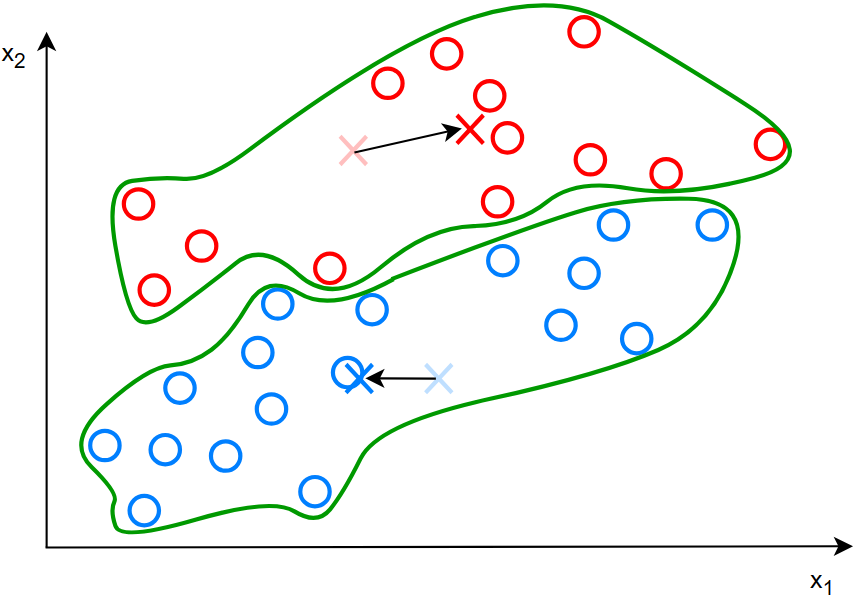
对于第二步的图解:
移动簇质心:
如果因为簇质心初始化有问题,导致一些簇质心没有分配到坐标点该怎么办,就像这样:
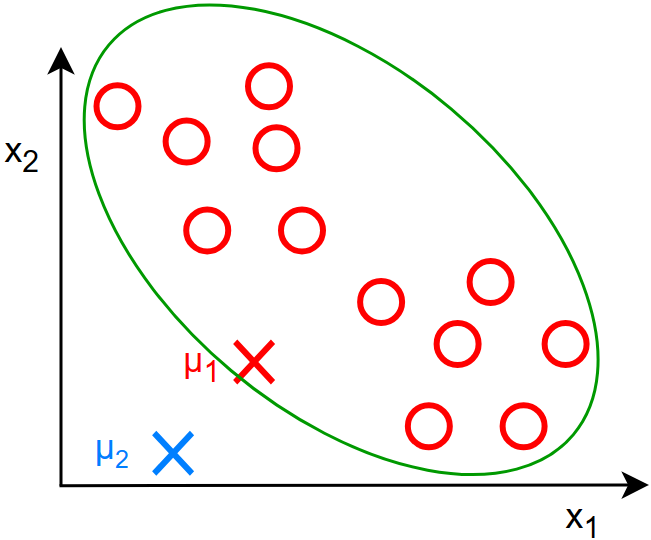
簇质心 \(\mu_2\) 没有分配到任何数据点!
通常情况下,如果程序执行完后,存在簇质心没有任何的数据点,那么我们一般会将那个没有任何数据点的簇质心删去
也就是进行\(k-1\) 的操作,去除 \(\mu_2\) 只保留 \(\mu_1\)
但是也可以重新进行簇质心的初始化
K-means优化器(Optimization)
定义如下参数:
\(c^{(i)}\) = 距离 \(x^{(i)}\) 最近的簇质心的下标
\(\mu_k\) = 簇质心 k
\(\mu_c^{(i)}\) = 距离 \(x^{(i)}\) 最近的簇质心的位置坐标
损失函数: \[ J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k)=\frac{1}{m}\sum_{i=1}^m|| x^{(i)}-\mu_c^{(i)} ||^2 \] 上述函数计算的是已分配簇质心的数据点到其簇质心的平均距离,我们要做到就是减小这个损失函数: \[ \begin{gather} min \\ c^{(1)},...,c^{(m)} \\ \mu_1,...,\mu_k \end{gather} J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k) \] 这个函数也叫做失真函数(distortion function)
和梯度下降不同,这个函数是通过选择不同的质心 \(\mu_c^{(i)}\) 来减小
对于之前提到的第一步:
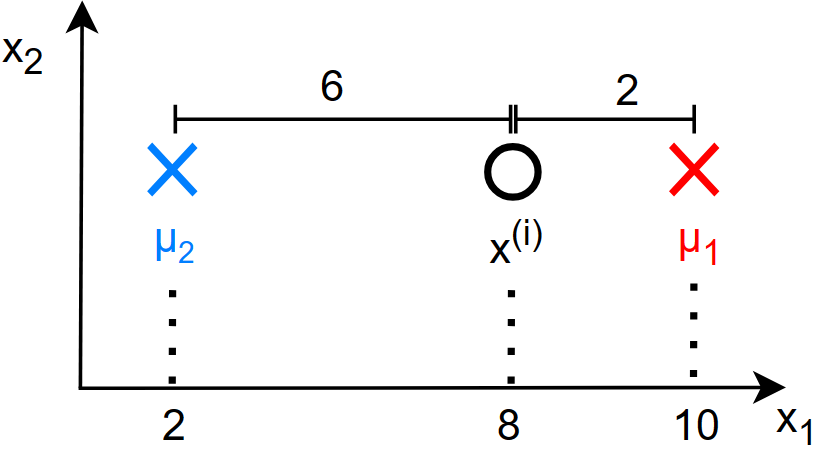
根据上图,\(\mu_1\) 到 \(x^{(i)}\) 的距离是更短的,所以损失函数会选择 \(\mu_1\) ,在函数中体现为:
选择了 \(\mu_1\) 也就是改变了 \(c^{(i)}\) 对于函数: \[ \frac{1}{m}\sum_{i=1}^m|| x^{(i)}-\mu_c^{(i)} ||^2 \] 其中的 \(\mu_c^{(i)}\) 也由于选择了更短的 \(\mu_1\) 而变为其坐标,从而使得该函数更小
对于之前的第二步:
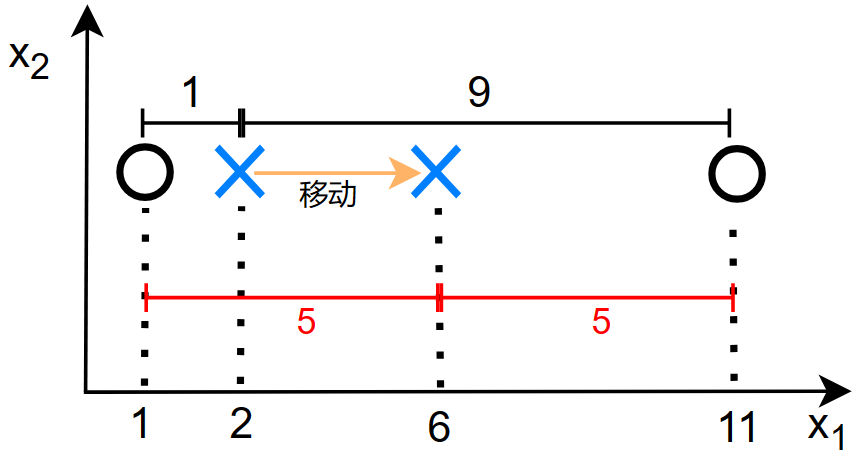
在移动簇质心之前,我们计算一些其到左右两个数据点的平均距离(其实也就是损失函数): \[ \begin{gather} \frac{1}{m}\sum_{i=1}^m|| x^{(i)}-\mu_c^{(i)} ||^2=\frac{1}{2}[(1-2)^2+(11-2)^2] \\ =\frac{1}{2}(1^2+9^2) \\ =41 \end{gather} \] 将簇质心移动到两个数据点的平均坐标上时,我们计算其平均距离: \[ \begin{gather} \frac{1}{m}\sum_{i=1}^m|| x^{(i)}-\mu_c^{(i)} ||^2=\frac{1}{2}[(1-6)^2+(11-6)^2] \\ =\frac{1}{2}(5^2+5^2) \\ =25 \end{gather} \] 移动之后,损失函数减小了:\(41-25=16\)
所以说,第二步中移动 \(\mu_k\) 能够减小损失函数
这个损失函数将会一直减小不会增大,如果不是这样的话,就检查你的代码是否存在bug
当这个函数停止减小了,或者减小的幅度很慢,就可以考虑它是不是收敛了
K-means初始化(Initializati0n)
如何随机选择簇质心呢,我们常常这么做:
- 选择 \(k<m\)
- 随机取出 \(k\) 个训练数据
- 将取出的 \(k\) 个训练数据的数据点作为 \(k\) 个簇质心
但是,如果只是初始化一次的话,会出现以下问题:
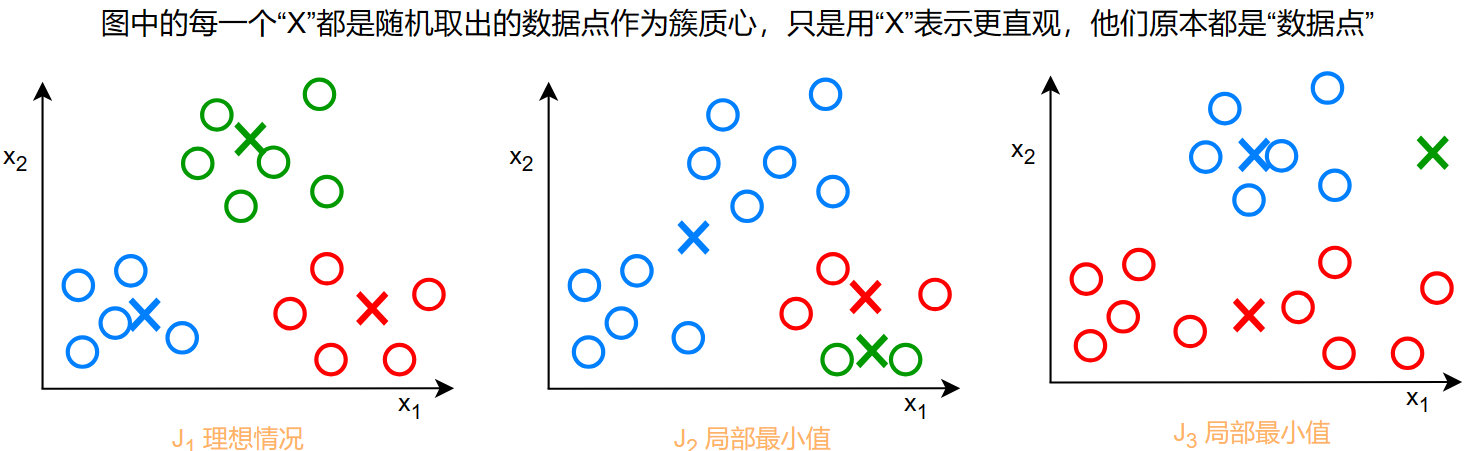
对于这种情况,我们只需要进行多次初始化,之后从收敛的损失函数中选出最小值作为最佳的初始化
写出最终算法:
循环 \(n\) 次(n的值一般为50~100):
- 随机初始化K-means
- 选择 \(k<m\)
- 随机取出 \(k\) 个训练数据
- 将取出的 \(k\) 个训练数据的数据点作为 \(k\) 个簇质心
- 运行K-means算法,获取 \(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k\)
- 计算损失函数:\(J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k)\)
最后取出最小的 \(J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k)\) 此时的簇质心就是比较合适的簇质心
簇质心数量的选择
上面说了那么多,我们到底要取多少个簇质心呢?
对于一些数据来说,选择簇质心的数量可能并没有那么简单:
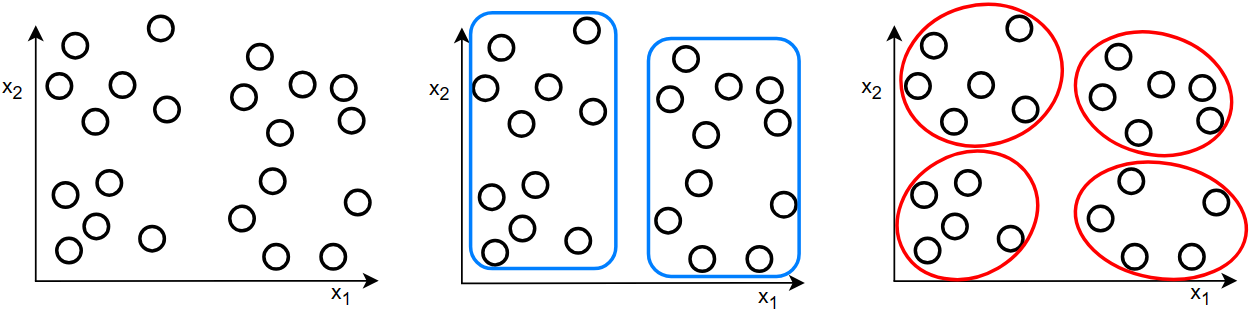
对于上面的数据,分为两类合理,分为四类也合理,到底应该分为几类呢?
肘法(elbow method)
我们可以画出损失函数关于簇质心数量的曲线:
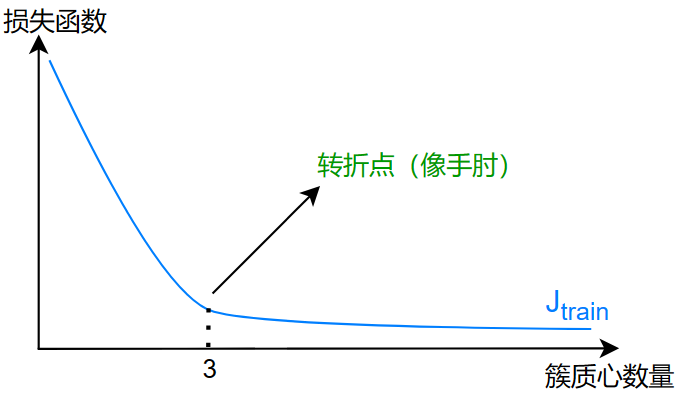
当损失函数出现转折点时,当时的转折点的簇质心数量就是最佳数量
那如果损失函数没有转折点该怎么办?
其实最好的办法就是:根据实际出发
如果你有一家服装店,经过多年积累,你手上有众多客户的身高体重的数据,此时你想要看看,将哪些范围的身高体重设置为衣服的对应尺码:S、M、L 码
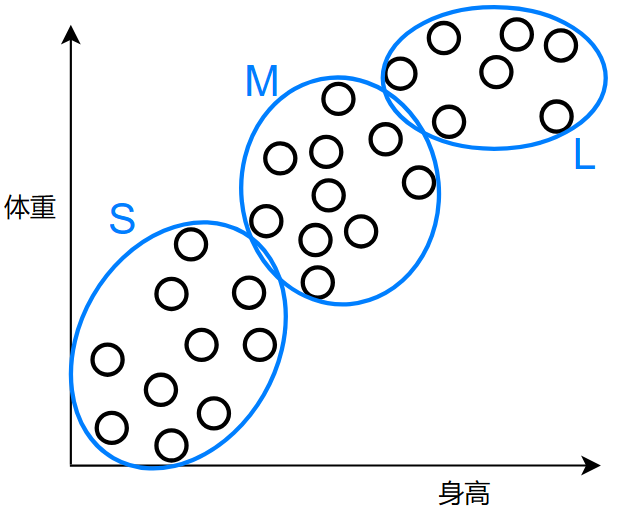
可以像这样分为三个尺码
但是如果客户对服装尺码的差异比较敏感的话,也可以这样分:
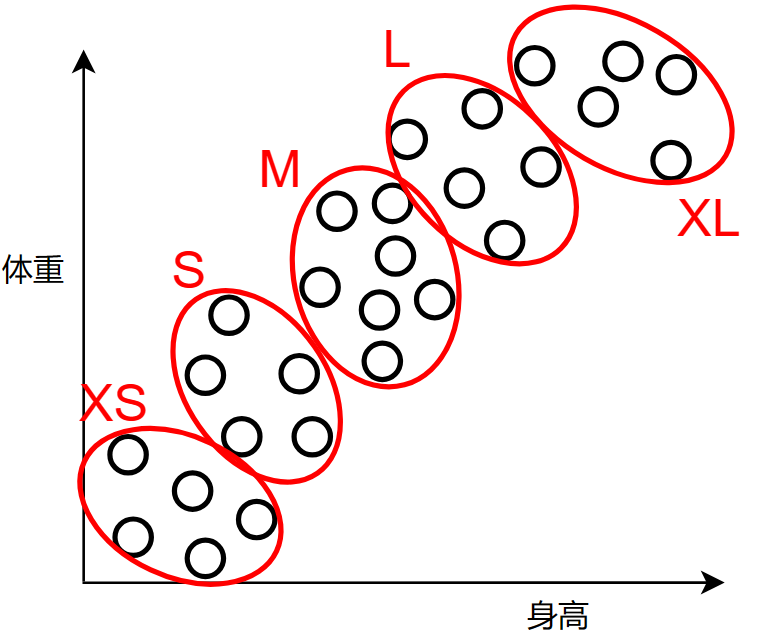
我的意思是,其实没有什么标准答案,我们需要考虑的是现实情况,然后去选择一个最合适的簇质心数量,每一个选择对你或者对其他人来说,可能都是适合的或者不适合的,这要看你如何处理
其实我们学习机器学习算法,目的就是要帮助人们解决生活中的问题,跳脱出算法的禁锢,回到生活中来,你将会有新的发现!
总结
本文章讲了无监督学习中的聚类,同时也讲了一些其他概念:K-means算法等
在接下来,我们将开始学习无监督学习中的第二个算法——异常检测(Anomaly detection)
从0了解机器学习:6——聚类