从0了解机器学习:5——决策树
本文章将介绍监督学习中的决策树,以及一些其他有关概念
决策树广泛应用于分类和回归任务,在机器学习竞赛中也有广泛应用,且能够取得不错的成绩
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
决策树(Decision trees)
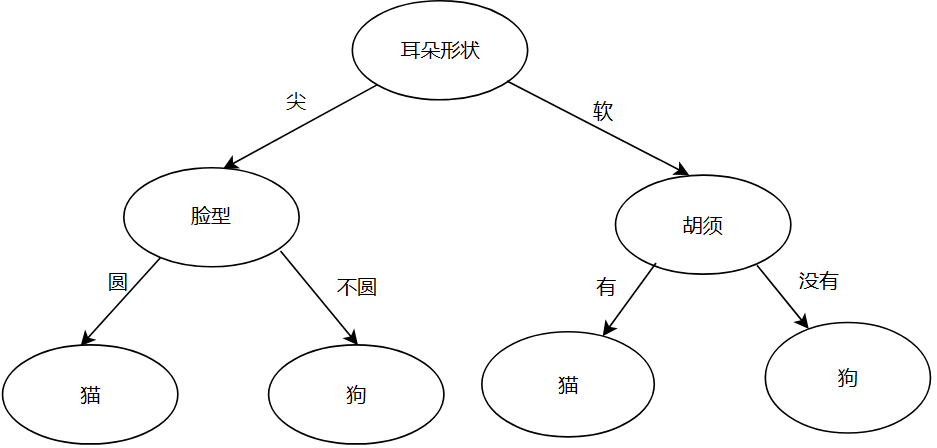
我们使用猫狗分类来举例子:
| 耳朵形状 | 脸型 | 胡须 | 猫 |
|---|---|---|---|
| 尖 | 圆 | 有 | 1 |
| 软 | 不圆 | 有 | 1 |
| 软 | 圆 | 无 | 0 |
| 尖 | 不圆 | 有 | 0 |
| 尖 | 圆 | 有 | 1 |
| 尖 | 圆 | 无 | 1 |
| 软 | 不圆 | 无 | 0 |
| 尖 | 圆 | 无 | 1 |
| 软 | 圆 | 无 | 0 |
| 软 | 圆 | 无 | 0 |
其网络大概是:
决策树学习(Decision tree learning)
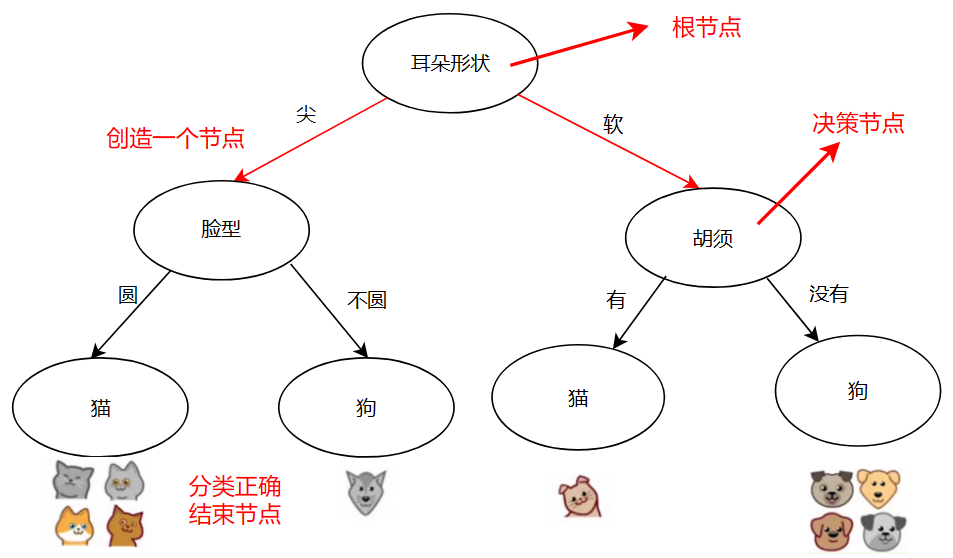
决策一:如何选择每个决策节点的特征用于分类(提纯:maximize purity)
- 选择一个特征,能让分类后某一类的纯度最大
决策二:什么时候结束节点
当一个节点中某一类的纯度为100%
当节点深度达到了规定的最大树深度(规定最大树深度能够有效避免过拟合)
当每次分类所提升的纯度降低到一个阈值以下时
当某个节点的分类的结果少于一个阈值时
衡量纯度(Measuring purity)
熵(Entropy)
使用熵来衡量每一次分类之后某一类的纯度
高中学过熵,当系统越混乱时熵越大,而系统越有秩序,熵越小
而我们要做的就是像减小损失函数一样,减少熵
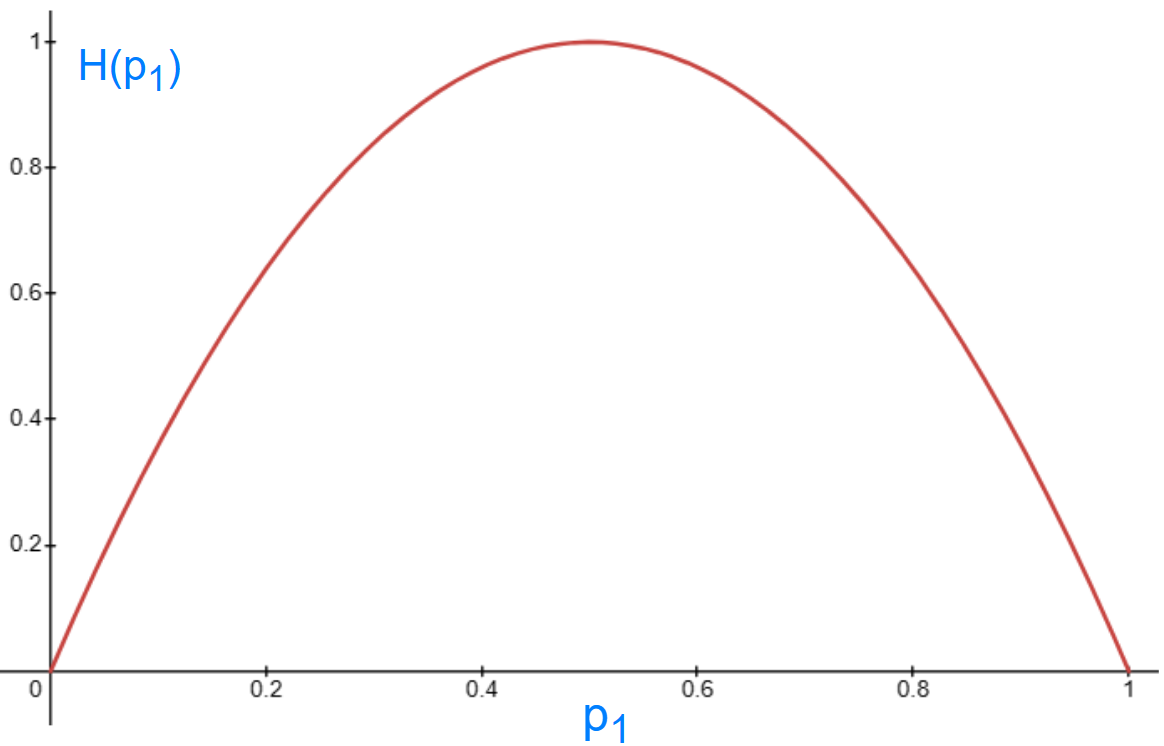
以上是熵函数,\(x\) 轴为 \(p_1\) ,\(y\) 轴为熵: \(H(p_1)\)
\(p_0\) :分类的数据中含狗的比例
\(p_1\) :分类的数据中含猫的比例 \[ \begin{gather} H(p_1)=-p_1log_2(p_1)-p_0log_2(p_0) \\ \Downarrow \\ H(p_1)=-p_1log_2(p_1)-(1-p_1)log_2(1-p_1) \end{gather} \] 以下是一些例子:

信息增益(Information gain)
熵的减小被称为信息增益
根据之前的数据,数据一共有 10 个,其中猫狗各一半
故根节点的熵为:\(H(0.5)=1\)
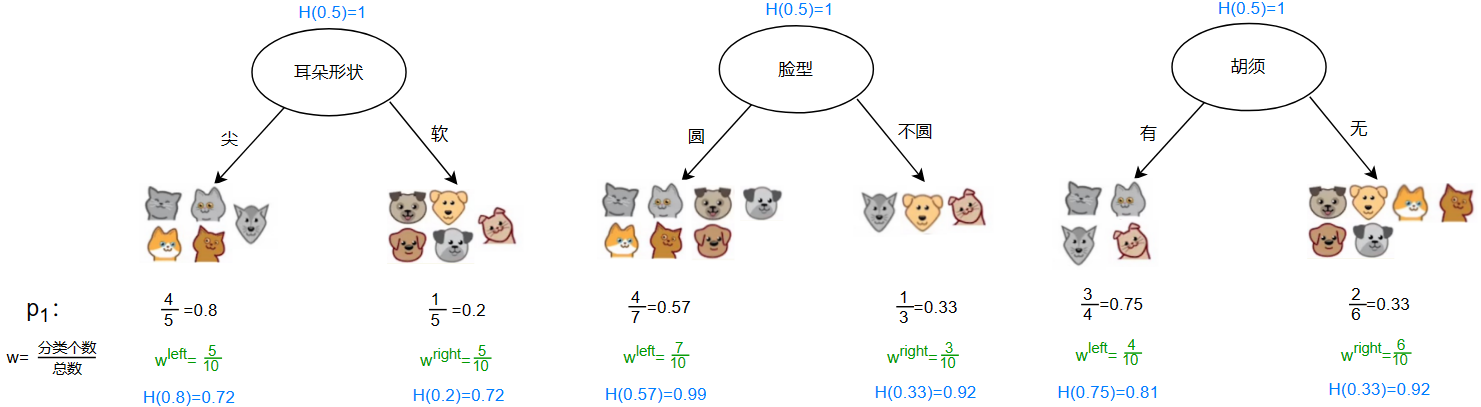
根据信息增益公式: \[ \begin{gather} w=\frac{当前节点样本数}{上一节点样本数} \\ information\;\;gain=IG=H(p^{root})-[w^{left}\cdot H(p_1^{right})+w^{right}\cdot H(p_1^{left})] \end{gather} \] 对于以上三个例子: \[ \begin{gather} IG_1=H(0.5)-[\frac{5}{10}\cdot H(0.8)+\frac{5}{10}\cdot H(0.2)]=0.28 \\ IG_2=H(0.5)-[\frac{7}{10}\cdot H(0.57)+\frac{3}{10}\cdot H(0.33)]=0.03 \\ IG_3=H(0.5)-[\frac{4}{10}\cdot H(0.75)+\frac{6}{10}\cdot H(0.33)]=0.12 \\ \Downarrow \\ IG_1>IG_3>IG_2 \end{gather} \] 第一个的信息增益最高,可以选择”耳朵形状“作为该节点的特征
学习过程
从根节点开始使用整个数据集
对所有可能的特征计算信息增益,选取信息增益最高的特征
根据选出的特征切分数据,分成左右节点
将子节点作为新的根节点,循环上述过程,最后可以使用以下标准停止分支:
- 当一个节点中某一类的纯度为100%
- 当节点深度达到了规定的最大树深度
- 当每次分类所提升的信息增益降低到一个阈值以下时
- 当某个节点的分类的样本数少于一个阈值时
以下是过程示例:
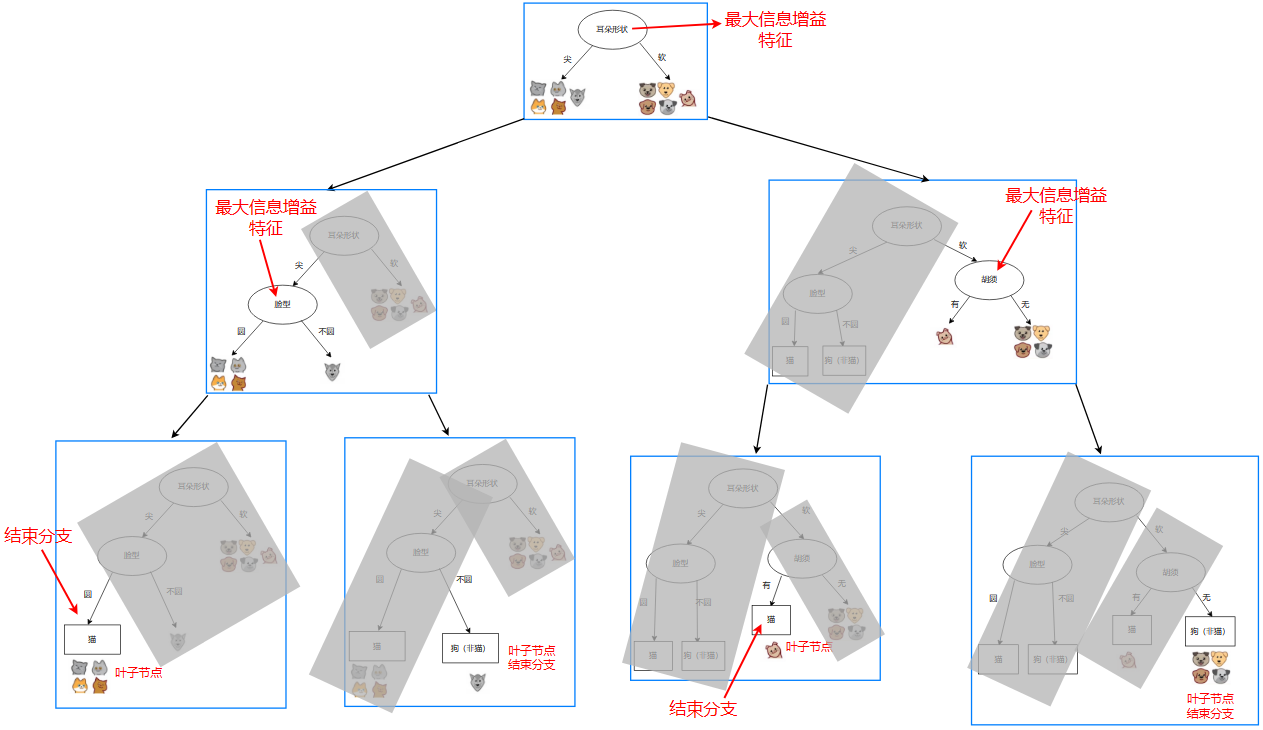
独热码(One-hot code)
将原来的文字描述换成01描述:
| 尖耳 | 软耳 | 圆耳 | 圆脸 | 胡须 | 猫 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 1 | 1 |
| 0 | 0 | 1 | 0 | 1 | 1 |
| 0 | 0 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 1 |
| 0 | 1 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 1 | 0 | 0 |
输入变为五个
连续值特征
对于一些数值类型的特征,比如体重:
| 体重 | 猫 |
|---|---|
| 7.2 | 1 |
| 8.8 | 1 |
| 15 | 0 |
| 9.2 | 0 |
| 8.4 | 1 |
| 7.6 | 1 |
| 11 | 0 |
| 10.2 | 1 |
| 18 | 0 |
| 20 | 0 |
将不同体重作为分界线,计算各个体重作为分界线时的信息增益,取出最大的作为特征
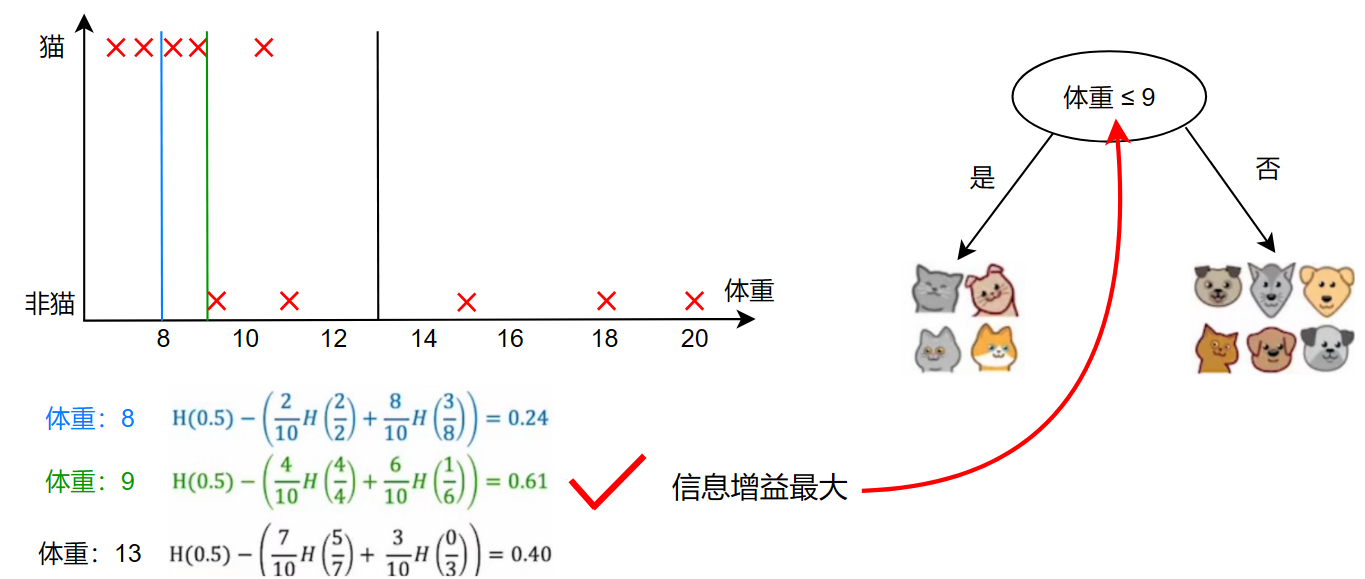
回归树(Regression with decision tree)
和之前的分类不同,回归树将预测的是数值而不是类别
对于之前的体重作为输入,这一次我们将体重作为输出,也就是预测体重
| 耳朵形状 | 脸型 | 胡须 | 体重(输出) |
|---|---|---|---|
| 尖 | 圆 | 有 | 7.2 |
| 软 | 不圆 | 有 | 8.8 |
| 软 | 圆 | 无 | 15 |
| 尖 | 不圆 | 有 | 9.2 |
| 尖 | 圆 | 有 | 8.4 |
| 尖 | 圆 | 无 | 7.6 |
| 软 | 不圆 | 无 | 11 |
| 尖 | 圆 | 无 | 10.2 |
| 软 | 圆 | 无 | 18 |
| 软 | 圆 | 无 | 20 |
那么怎么表示预测结果呢?
和之前的分类一样,不过这一次在停止分支之后的叶子节点的值为:该叶子节点样本体重的平均值
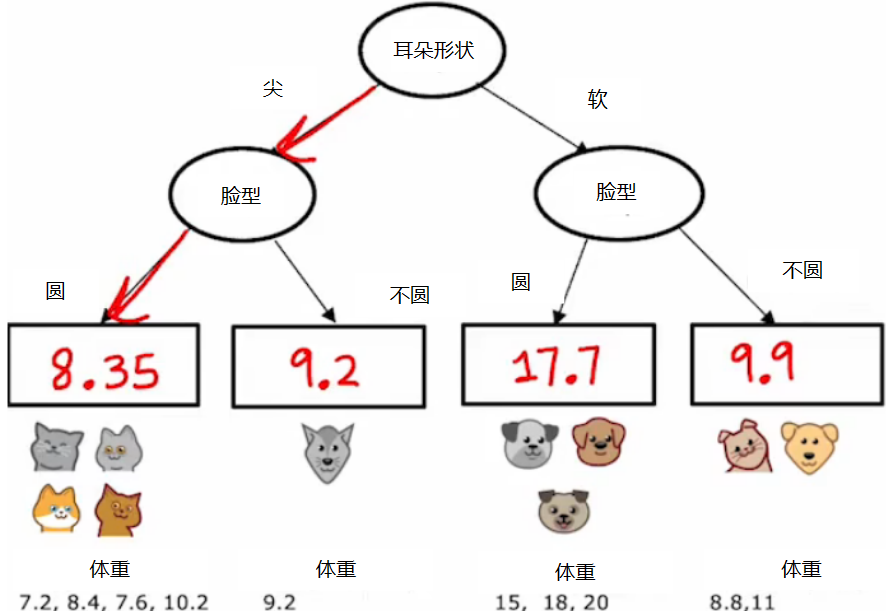
怎么选取决策的特征呢?
和之前的一样,只不过这一次我们使用另一个东西来表示”熵“——方差
每一次分类之后,计算各个样本的方差,之后带入信息增益公式中,信息增益公式中所有的熵替换为方差:

多决策树(Multiple decision tree)
决策树对数据中的微弱变化是十分敏感的,这将导致相同的标签仅仅因为数据内一点点不同,可能会有不同的输出
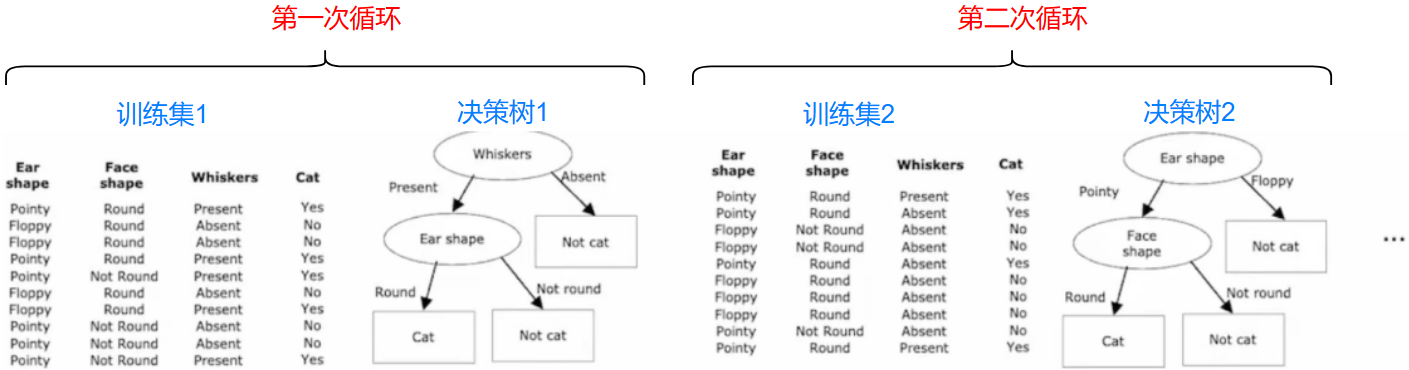
我们可以使用多个决策树,让多个决策树对同一组数据进行预测,最后”少数服从多数“,获得最后的输出
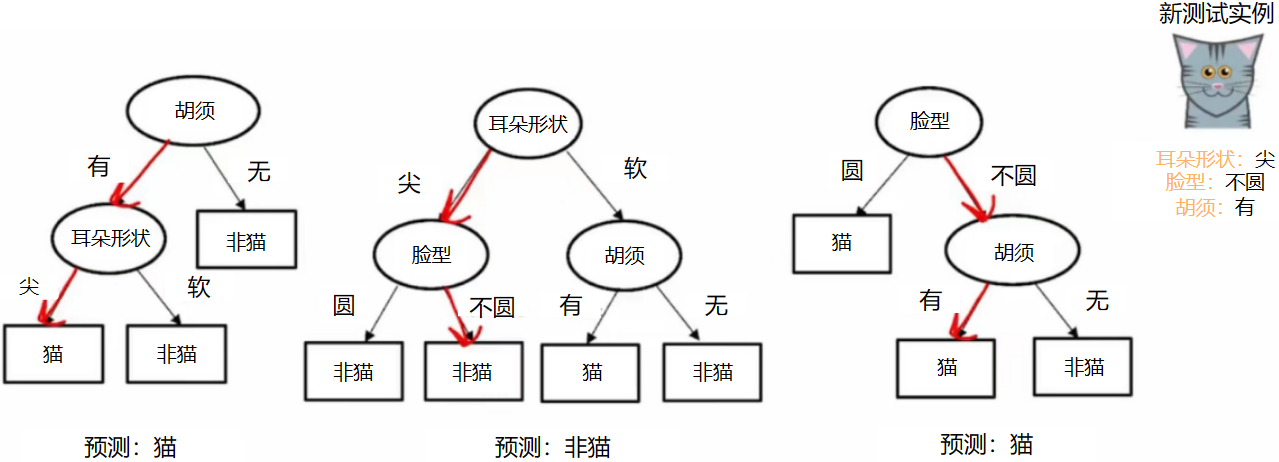
最后,两个预测为猫,一个预测为非猫,少数服从多数,最终结果为猫
有放回抽样(Sampling with replacement)
这是一种给多决策树创建训练集的方式

有放回抽样,拿取的数据是随机抽取的,可以有重复的数据
随机森林算法(Random forest algorithm)
随机森林算法又叫做口袋决策树(Bagged decision tree)
给定大小为 \(m\) 的训练集,和 \(B\) 个决策树
- 从 1 到 \(B\) ,遍历森林中的 \(B\) 棵决策树:
- 使用有放回抽样创建大小为 \(m\) 的训练集
- 在刚刚创建的训练集上训练决策树
- 重复以上操作(每一次重复都会创建新的训练集和决策树)
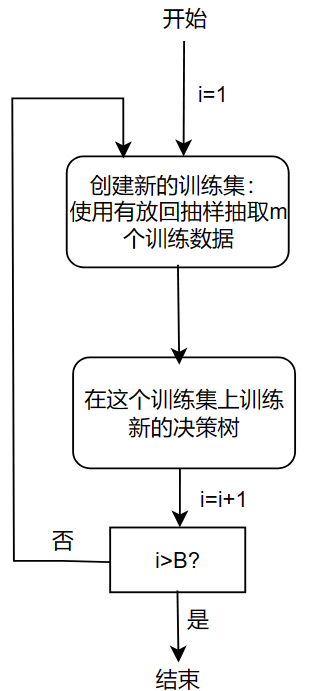
其中,\(B\) 的数量,也就是森林中树的个数一般是100个左右
当 \(B\) 大于100时,随机森林可能工作得不是很好
在训练的时候,你会发现很多树在根节点附近的决策节点都是相同的,因为一旦找到了最好的特征,那么之后的树就都会使用这个特征,导致树的根部附近看起来都是相同的
随机特征选择
为了解决上面提到的,决策树靠近根节点的特征都相同的问题
在每个节点选择特征时:
如果我们有 \(n\) 个可供选择的特征,那么就随机取出其中的 \(k\) 个特征,其中 \(k<n\)
在选择特征时,只能从这 \(k\) 个特征中选择
事实上,\(k\) 一般设置为 \(\sqrt{n}\)
极端梯度增强(Extreme gradient boosting:XGBoost)
在之前我们构造随机森林时,是这样操作的:
给定大小为 \(m\) 的训练集,和 \(B\) 个决策树
- 从 1 到 \(B\) ,遍历森林中的 \(B\) 棵决策树:
- 使用有放回抽样创建大小为 \(m\) 的训练集
- 在刚刚创建的训练集上训练决策树
- 重复以上操作(每一次重复都会创建新的训练集和决策树)
但是,如果在训练时,一些决策树对一些训练示例进行了错误分类,那么在下一个决策树训练时,这些分类错误的训练示例有很大可能仍然被分类错误,该怎么解决这个问题呢?
在学校里,当我们做作业做错了的时候,老师就会让我们一遍遍地做错题,做到正确为止
在随机森林中,也可以使用这种方法,让后一个决策树做前一个决策树做错了的”错题“,这样就能大大减小同一个训练示例的重复错误
让我们改进一下算法:
给定大小为 \(m\) 的训练集,和 \(B\) 个决策树
从 1 到 \(B\) ,遍历森林中的 \(B\) 棵决策树:
- 使用有放回抽样创建大小为 \(m\)
的训练集
- 在抽取训练数据时,每一个训练数据被抽取到的概率不再是公平的 \(\frac{1}{m}\) ,此时将大概率抽取之前决策树出错的数据(并不是一定抽取出错的数据)
- 在刚刚创建的训练集上训练决策树
- 重复以上操作(每一次重复都会创建新的训练集和决策树)
具体概率究竟增加了多少,这里面的数学细节很复杂,这里不做解释
XGBoost的优点:
- 开源
- 更高的效率
- 更好的节点分支标准和分支停止标准
- 内置正则化防止过拟合
- 在机器学习竞赛中竞争最激烈的算法
XGBoost使用:
1 | # 分类 |
决策树VS神经网络
决策树和树集合:
对表格数据(结构化数据)表现很好
不推荐在非结构化数据(图片,视频,音频,文本...)中使用决策树
快速
小规模的决策树的原理能被人类理解
神经网络:
在结构化和非结构化数据上都表现得不错
可能比决策树更慢一些
可以使用迁移学习
更容易将多个神经网络模型串联起来组成一个更大的网络模型一起学习,而决策树一次只能训练一颗树
总结
本文章讲了监督学习中的决策树,同时也讲了一些其他概念:信息增益,随机森林,XGBoost等
在接下来,我们将开始学习无监督学习中的第一个算法——聚类(Clustering)
从0了解机器学习:5——决策树