从0了解机器学习:4——神经网络
本文章将介绍监督学习神经网络,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
神经网络发展历程:
起源:为了模仿人脑
在二十世纪八十年代和九十年代早期大受欢迎,而在九十年代末,神经网络开始跌出人们的视野
在2005年之后的时间神经网络再次卷土重来,而神经网络也常常被叫做深度学习
从一开始研究语音识别,到图像识别,再到自然语言处理(实际上这些研究是并行的,并不是顺序进行)
具体的历史还需要各位自行了解,这里作简要介绍
神经网络(Neural networks)
我们举一个例子作为了解神经网络的切入点:预测一款服装是否畅销
当我们想要回答这个问题时,我们需要考虑哪些因素呢?我们可以像下图一样:
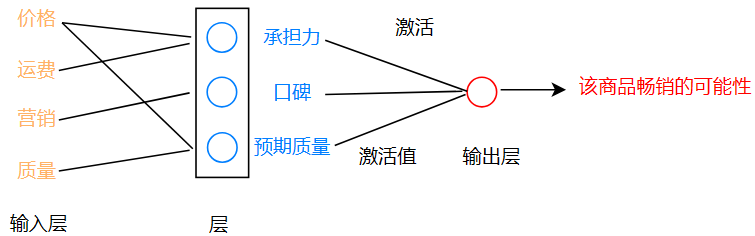
价格和运费影响着客户的经济承担能力,营销影响着商品的口碑,质量和价格在影响着客户的预估质量。而承担力,口碑,质量共同决定了该商品能不能成为畅销的商品,这些在常识看来是很合理的
但是,如果我们有很多的输入,也就是很多可供考虑的因素,那么我们还应该像图中一样,把相关联的因素连在一起吗?或者说,图中的线所反映的影响关系就一定是正确的吗?口碑就只由营销影响吗?或者价格就一定影响质量吗?
很显然,这些问题都需要回答,但是一些因素的影响关系是我们无法通过直觉判断的,那该怎么办?
答案是,我们只需将他们都互相连接起来就行,在现在看来,这是一个好的办法
下面是将他们互相连接起来的样子:
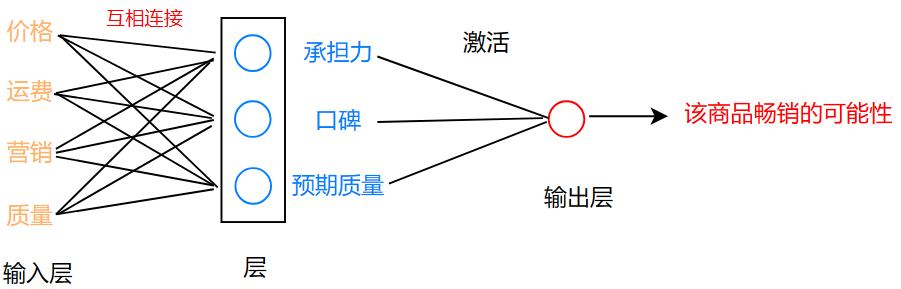
但是,你可能会问,这样连接真的合适吗?
营销真的可以影响经济承担力吗?运费真的影响质量吗?这听起来不可思议,或者说很荒唐
但是没办法,如果因素多起来,你还想一个个地按照现实的影响关系一一连起来吗?
我们别管他,只需要给每一条线设置一个参数就行,让参数大小决定影响大小就可以!
术语(Terms)
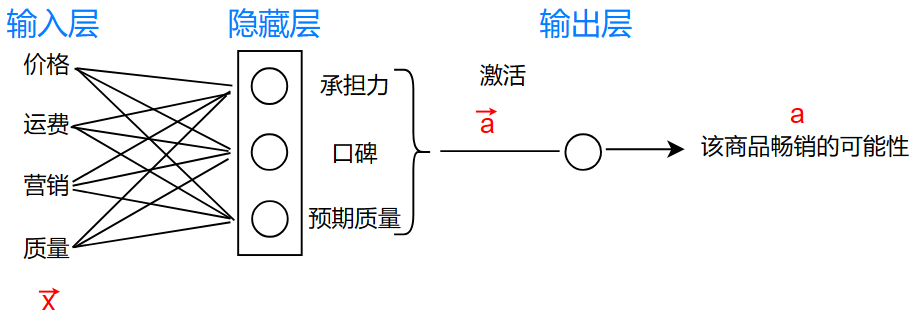
在图中,一共有三层:
- 输入层(input layer)
- 隐藏层(hidden layer)
- 输出层(output layer)
框框中的圆又叫做神经元(neurons)
你可以看到你的数据的输入和输出,但是你不知道你的这些数据在“隐藏层”中的样子或数值,所以称为隐藏层
神经网络让我震惊的点在于:它不知道隐藏层到底代表着什么,也就是说,隐藏层中的“口碑”是我们假设的,神经网络它根本不知道这是什么,在训练过程中,神经网络只知道:这个参数设置为这个值,或者说让一些参数代表某些含义,比如“质量”,就能够让损失函数的值降低(当然神经网络不知道什么是“质量”)
有点像婴儿学习说“爸爸妈妈”,在婴儿说出口时,婴儿也许也不知道他说的是什么,但是看到了爸爸妈妈开心的样子(感觉这个神经网络有点像人脑了啊喂 doge)
所以说,这就是为什么神经网络算法成为当今世界上最强大的算法之一
多隐藏层(Multiple hidden layer)
多隐藏层的神经网络就像这样:
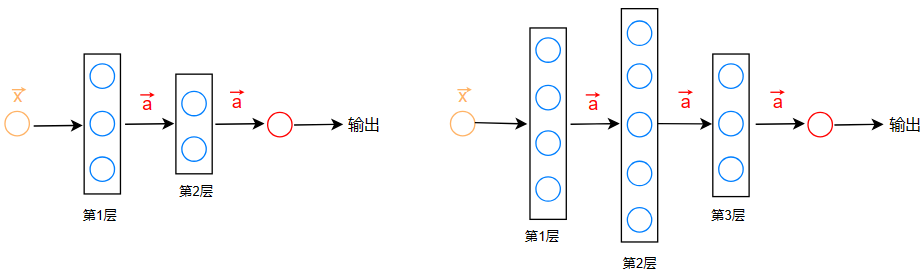
这又叫多层感知机(multiple perceptron)
神经网络架构:神经网络中,有多少隐藏层和多少神经元都是可以自由选择的,选择合适数量的层数和神经元数将会影响神经网络的表现
计算机视觉(Computer vision)
计算机视觉可以说是神经网络的一个广泛应用,比如:图像识别,人脸识别,各种通过图像和视频的识别等等
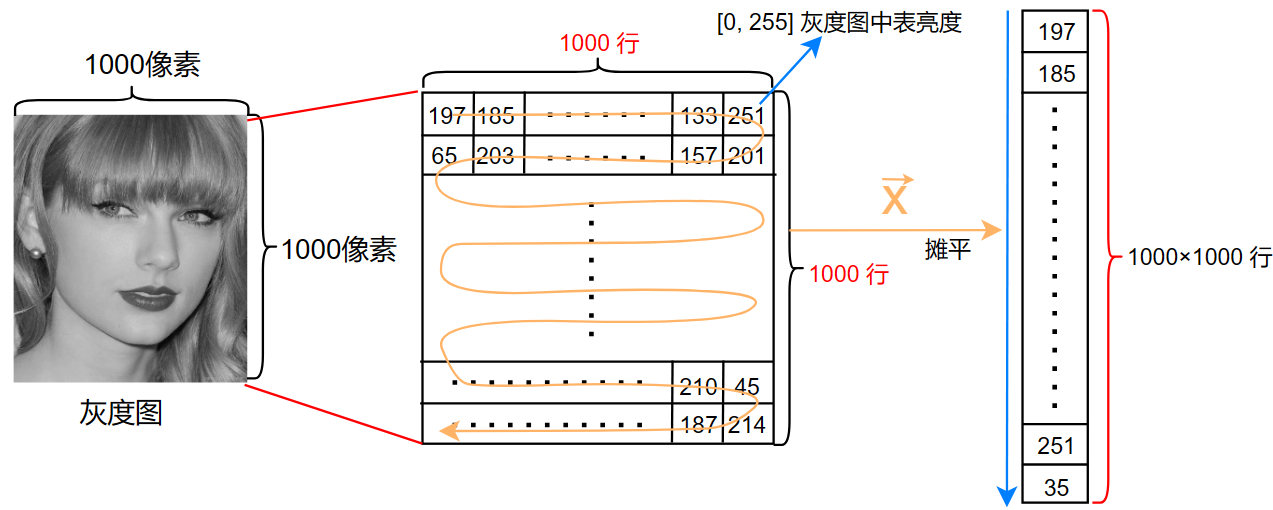
这里补充一些图像数据的知识,图像数据分为三类:
- 灰度图:单通道
- RGB:三通道(红绿蓝)
- JPGE
- PNG
- SVG
- BMP
- RGBA:四通道(红绿蓝+透明度)
- PNG
- SVG
其中每个通道的数据都是 [0,255] 之间
人脸识别:
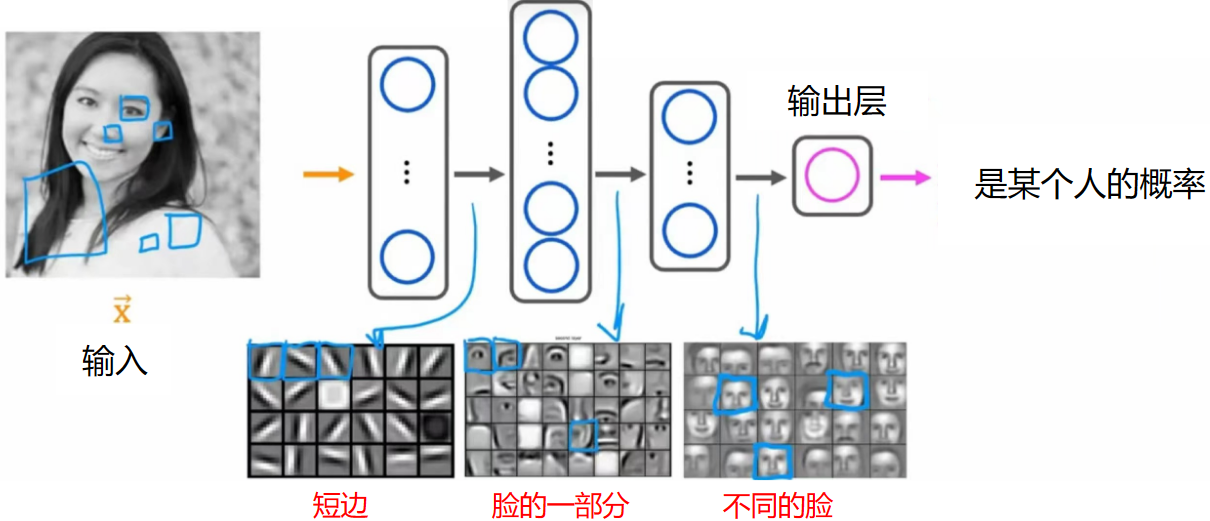
事实上,没有人告诉神经网络,第一层要分析短边,第二层要分析脸的一部分,第三层要分析不同的脸
所有的这些都是神经网络通过自己“学习”得到的,它也不知道为什么每一层要这么做,但就是因为这样做能让损失函数减小,这是一件很神奇的事!
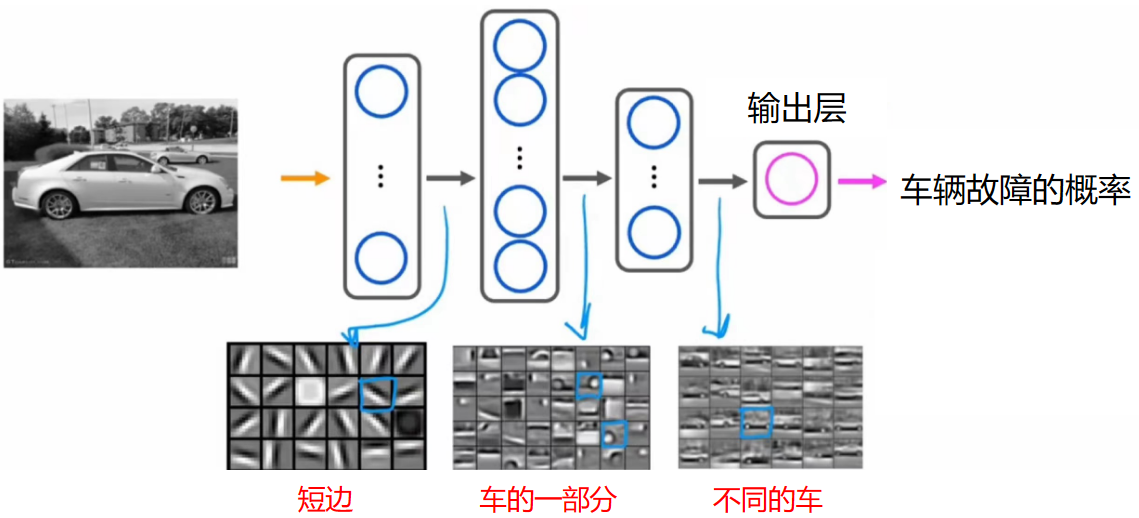
同样对于车辆故障检测:
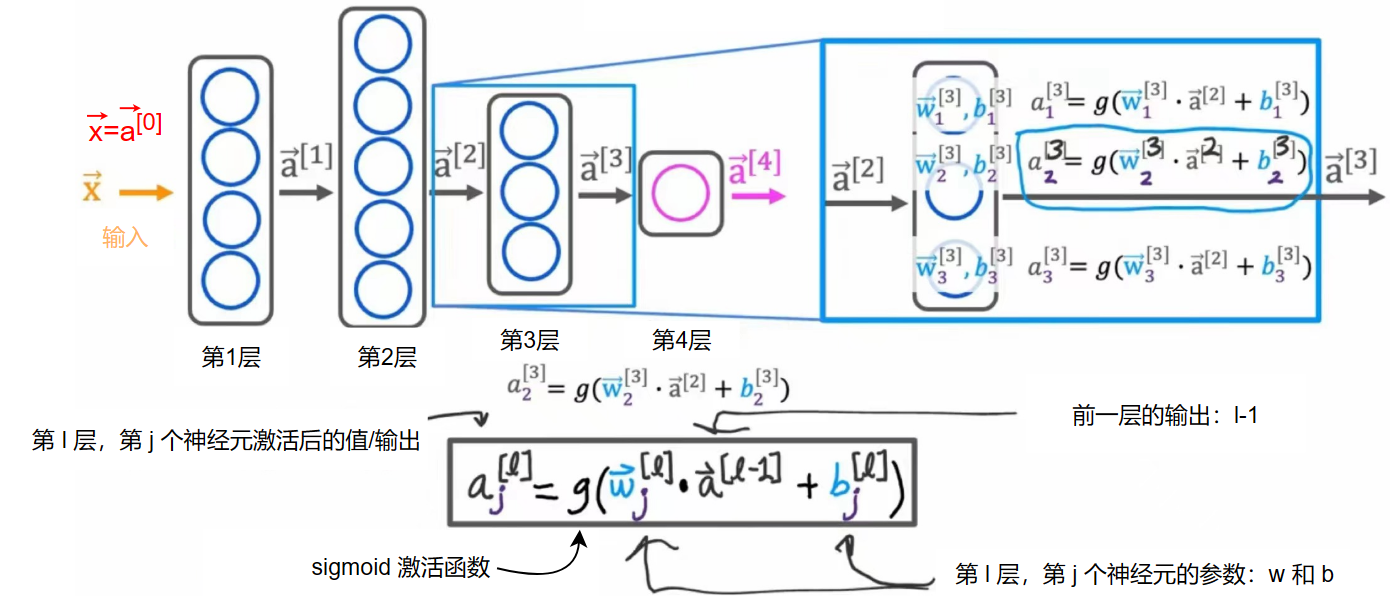
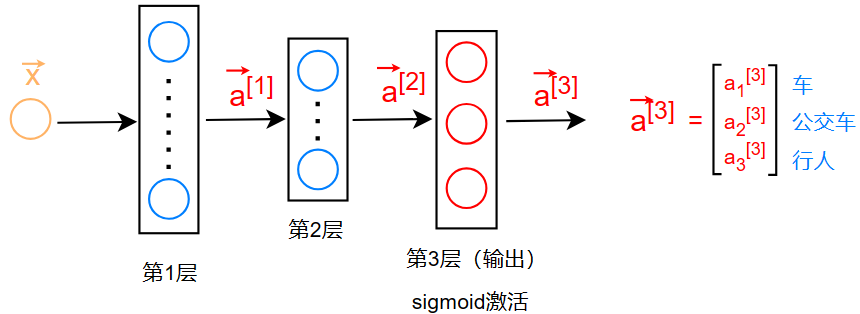
神经网络层(Neural network layer)
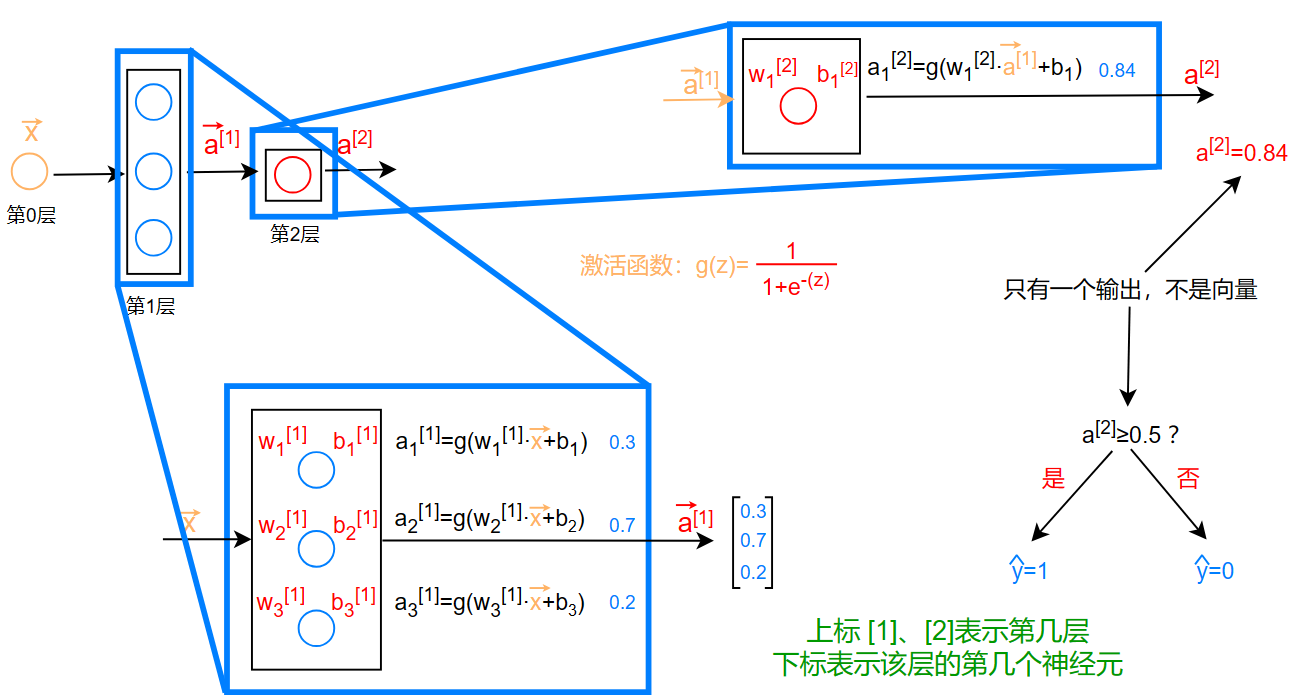
上图为两层神经网络(输入层除外)
对于有 l 层神经网络来说,每层的每个神经元的输出通式为:
手写数字识别(Handwriting digit recognition)
对于手写数字识别,我们只选择识别 0和1 来方便举例
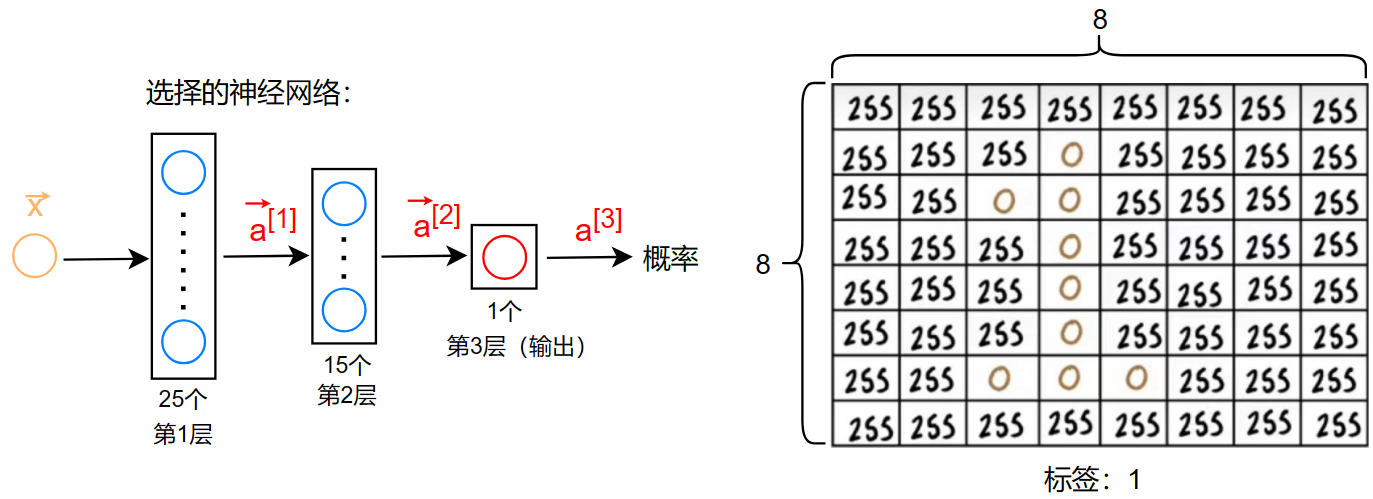
第一层有25个神经元,第二层有15个神经元,第三层有1个神经元,那么他们每个神经元输出的结果为: \[ \vec{a}^{[1]}= \begin{bmatrix} g(\vec{w}_1^{[1]}\cdot\vec{x}+b_1^{[1]}) \\ . \\ . \\ . \\ g(\vec{w}_{25}^{[1]}\cdot\vec{x}+b_{25}^{[1]}) \end{bmatrix} \\ \\ \vec{a}^{[2]}= \begin{bmatrix} g(\vec{w}_1^{[2]}\cdot\vec{a}^{[1]}+b_1^{[2]}) \\ . \\ . \\ . \\ g(\vec{w}_{15}^{[2]}\cdot\vec{a}^{[1]}+b_{15}^{[2]}) \end{bmatrix} \\ \\ a^{[3]}= \begin{bmatrix} g(\vec{w}_1^{[3]}\cdot\vec{a}^{[2]}+b_1^{[3]}) \end{bmatrix} \]
若 \(a^{[3]}\geq0.5\) 则 \(\hat{y}=1\)
若 \(a^{[3]}<0.5\) 则 \(\hat{y}=0\)
像这样一层一层向前计算的过程叫做:前向传播(Forward propagation)
通过之前的例子,你可能会发现:越接近输出层的层,其神经元的数量会越来越少!
怎么选择激活函数(Activation function)
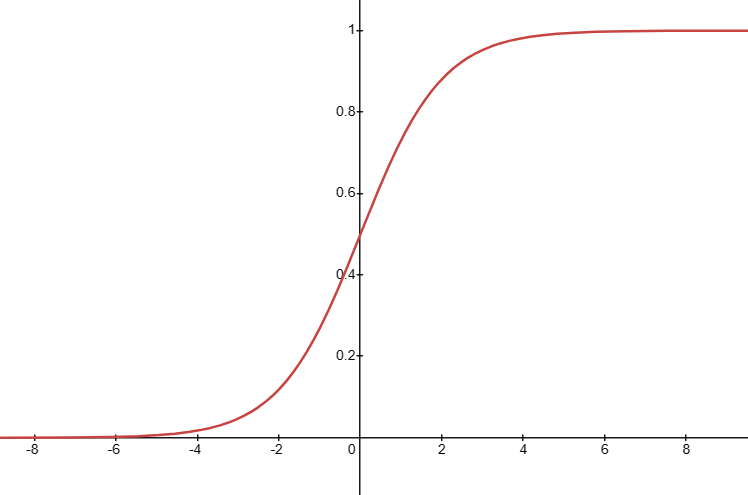
- 如果 y 只有两个值,就像:0、1
这种情况可以选择 sigmoid 函数作为激活函数 \[ sigmoid=f(x)=\frac{1}{1+e^{-x}} \]
如果是多分类的话会用到 softmax 激活,这是一种将多种输出结果全部转为和为1的概率输出的方式
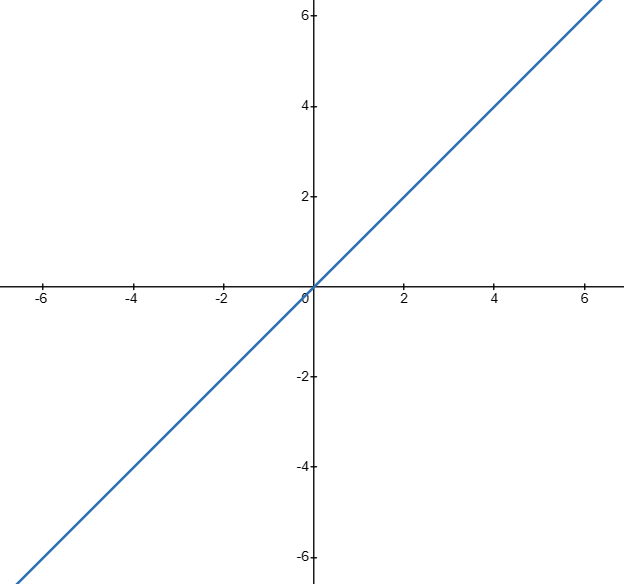
- 如果 y 既有正值也有负值
可以选择 线性 激活函数 \[ f(x)=kx+b \]
- 如果 y 总是正值的话
可以选择 Relu 激活函数 \[ Relu=f(x)=max(x,0) \]
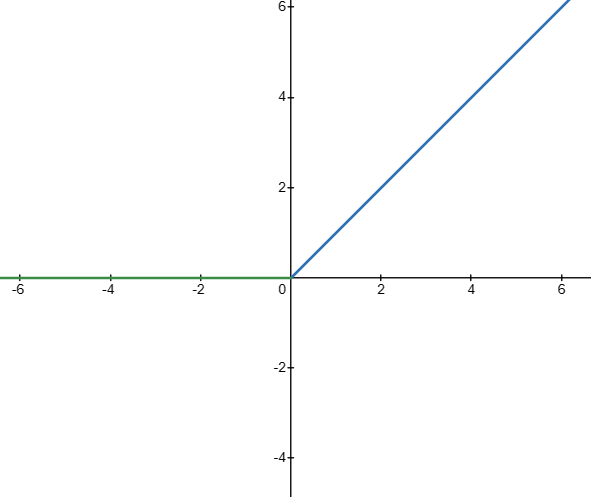
而如今,我们常常选择Relu作为激活函数:
- Relu激活函数的计算比 sigmoid 要快,这个结论通过观察二者的函数表达式就能得出
- sigmoid 的梯度下降在许多地方是平的(即该点的导数值接近于0),这将会使得梯度下降变慢,这个结论也可以通过观察 sigmoid 的函数表达式就能得出
而还有其他的激活函数如:Tanh 和 Leaky-Relu
但在实际应用中并没有完全证明二者总是优于 Relu
多分类问题
区别于二分类,多分类就是分类标签不少于2种,区别于二分类使用 sigmoid 多分类转而使用 softmax
softmax原理:
对于多个输出:
| 类别1 | 类别2 | 类别3 |
|---|---|---|
| 1.01 | 2.01 | -0.86 |
怎么将其转为和为1的概率呢?
那就是取他们的和作为分母,某一类的输出作为分子
但是有负数怎么办?那就加上 e : \[ y_i=\frac{e^{y_i}}{\sum_i^ne^{y_i}} \] 对于以上例子就是: \[ \begin{gather} \begin{cases} y_0=1.01 \\ y_1=2.01 \\ y_2=-0.86 \end{cases} \quad\rightarrow\quad \begin{cases} y_0=\frac{e^{y_0}}{e^{y_0}+e^{y_1}+e^{y_2}}=0.256 \\ y_1=\frac{e^{y_1}}{e^{y_0}+e^{y_1}+e^{y_2}}=0.695 \\ y_2=\frac{e^{y_2}}{e^{y_0}+e^{y_1}+e^{y_2}}=0.048 \end{cases} \\ y_0+y_1+y_2=0.256+0.695+0.048=1 \end{gather} \] 最后只需要取出其中最大的,也就是 \(y_1=0.695\) 作为预测值即可
在二分类中,目标函数为: \[ \begin{gather} a_1=f_{\vec{w},b}(\vec{x}^{(i)})=\frac{1}{1+e^{-(\vec{w}\cdot\vec{x}^{(i)}+b)}}\qquad y^{(i)}=1 \\ a_2=1-a_1\qquad y^{(i)}=0 \\ L(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)})= \begin{cases} -log(a_1)\qquad y^{(i)}=1 \\ -log(1-a_1)\qquad y^{(i)}=0 \end{cases} \end{gather} \] 其中 f(x) 为 sigmoid 函数
而在多分类中,f(x) 为 softmax 转化后的值: \[ \begin{gather} a_i=\frac{a_i}{\sum_i^ne^{a_i}}\qquad y^{(i)}=i \\ L(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)})= \begin{cases} -log(a_1)\qquad y^{(i)}=1 \\ -log(a_2)\qquad y^{(i)}=2 \\ -log(a_3)\qquad y^{(i)}=3 \\ \quad. \\ \quad. \\ \quad. \\ -log(a_n)\qquad y^{(i)}=n \end{cases} \end{gather} \] 之后,将目标函数带入损失函数中: \[ J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^mL(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)}) \] 之后的梯度下降操作和二分类一样,不做赘述
多标签分类(Multiple-label classification):
顾名思义,多标签分类就是一个数据中,有多个标签
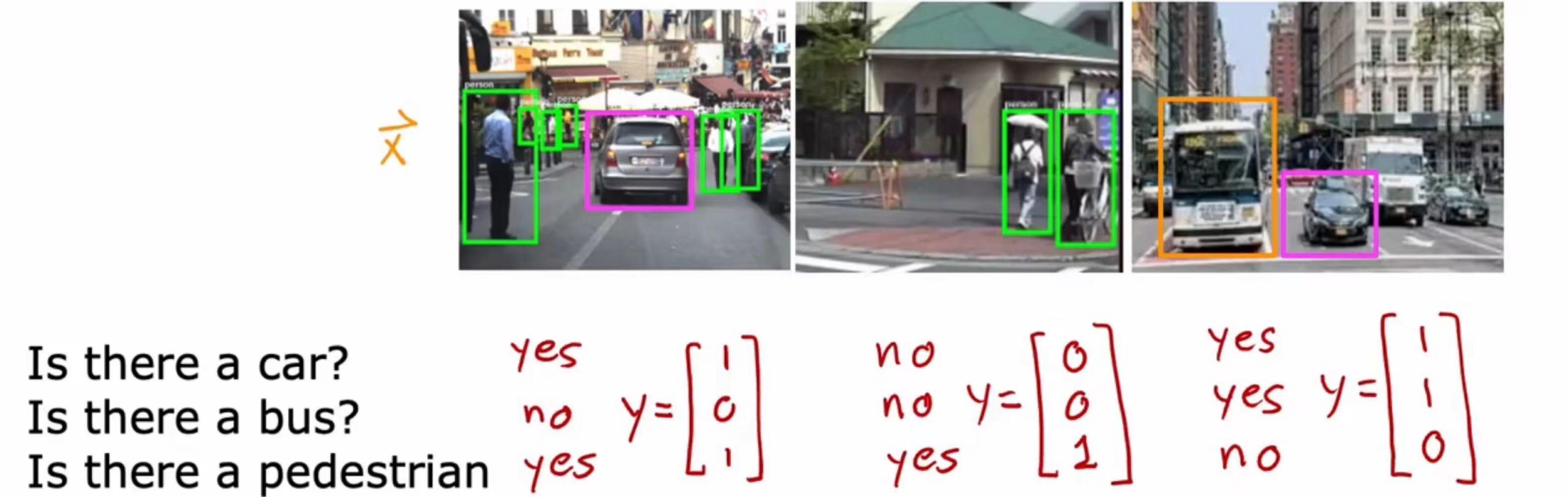
对于上图的例子,我们可以训练一个模型,拥有三个输出
为什么最后一层用 sigmoid 因为输出的是概率,而 sigmoid 输出为概率,其他层可以不使用 sigmoid 而使用其他激活函数,至于为什么不用 softmax,因为这不是多分类问题,而是多标签分类问题
而softmax,会将输出转为和为1的概率输出,而对于三个输出值,只可能有一个值大于0.5,或者都不大于0.5,那么最后预测的结果要么只有一个,要么都没有
而使用 sigmoid 函数,因为其输出为概率,总和并不一定等于1,有不止1个值大于0.5,这样就可以做到一次输出,识别多个目标的功能
诊断评估(Diagnostic)
如果你有一个线性回归模型: \[ J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum_{j=1}^nw_j^2 \] 如果这个线性回归模型有很大的偏差,你该怎么做?
- 获得更多的数据集
- 尝试减少特征
- 尝试增加特征
- 尝试增加特征维度 \((x_1^2,x_2^2,x_1x_2,...)\)
- 减小正则化参数 \(\lambda\)
- 增加正则化参数 \(\lambda\)
评估模型(Evaluating model)
交叉验证(Cross validation):使用训练集和测试集
这里,我们使用10个数据的线性回归作为演示:
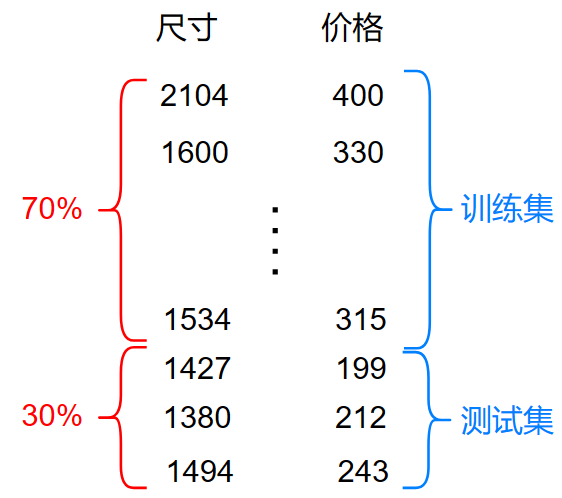
划分测试集和训练集常用的比例为2:8或3:7
- 对于训练集,我们有:
\[ \begin{gather} (x^{(1)},y^{(1)}) \\ (x^{(2)},y^{(2)}) \\ . \\ . \\ . \\ (x^{(m_{train})},y^{(m_{train})}) \end{gather} \]
其中:\(m_{train}=7\) 即训练集有7个
- 对于测试集,我们有:
\[ \begin{gather} (x^{(1)},y^{(1)}) \\ (x^{(2)},y^{(2)}) \\ . \\ . \\ . \\ (x^{(m_{test})},y^{(m_{test})}) \end{gather} \]
其中:\(m_{test}=3\) 即测试集有3个
使用 MSE 去计算 \(L_{train}\) 和 \(L_{test}\) \[ L_{MSE}(\vec{w},b)=min_{\vec{w},b}[\frac{1}{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac{1}{2m}\sum_{i=1}^nw_j^2] \] 计算测试集误差: \[ L_{test}(\vec{w},b)=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(f_{\vec{w},b}(\vec{x}^{(i)}_{test})-y^{(i)})^2 \] 计算训练集误差: \[ L_{train}(\vec{w},b)=\frac{1}{2m_{train}}\sum_{i=1}^{m_{train}}(f_{\vec{w},b}(\vec{x}^{(i)}_{train})-y^{(i)})^2 \] 为什么没有正则项,因为这只是计算误差,没有进行梯度下降,所以不需要加正则项
对于分类来说,只需要将 \(L(\vec{w},b)\) 更换为对应的损失函数即可
并且统计当 \(y\neq\hat{y}\) 的个数,计算正确率
综上,我们就能看到 \(L_{test}\) 和 \(L_{train}\) 的图像,并且基于图像进行判断
改进交叉验证
这里给出一个例子: \[ \begin{gather} d=1\qquad f(\vec{x})=w_1x_1+b\qquad\rightarrow\qquad L_{test}(w^{<1>},b^{<1>}) \\ d=2\qquad f(\vec{x})=w_1x_1+w_2x^2+b\qquad\rightarrow\qquad L_{test}(w^{<2>},b^{<2>}) \\ d=3\qquad f(\vec{x})=w_1x_1+w_2x^2+w_3x^3+b\qquad\rightarrow\qquad L_{test}(w^{<3>},b^{<3>}) \\ . \\ . \\ . \\ d=10\qquad f(\vec{x})=w_1x_1+w_2x^2+w_3x^3+...+w_{10}x^{10}+b\qquad\rightarrow\qquad L_{test}(w^{<10>},b^{<10>}) \end{gather} \] 以上是对1~10阶多项式进行交叉验证
我们从中取出 \(L_{test}\) 最小的作为模型,之后我们使用其 \(L_{test}\) 再次计算出误差,作为该模型的泛化误差报告(以下称误差报告)
观察以上的方法,有什么不对的地方吗?
事实上,通过这种方法选择模型,在对其使用 \(L_{test}\) 报告误差,此时这个误差比实际更少!
因为选择模型时,使用测试集选择的模型,之后报告误差时,又再次使用该测试集计算 \(L_{test}\) 进行报告,此时的模型是经过一次测试集拟合过了,所以再使用测试集进行误差报告,此时的误差将会比实际更小
举一个常见的例子帮助理解:
数学老师从班上随机挑选10名同学选出一位综合实力更强的作为课代表,所以数学老师让他们同时做一套卷子,选出分数最高的同学。但是老师还不放心,这位同学这次分数考得最高,会不会存在偶然因素呢?于是数学老师决定再测试一次,于是让这位同学再做一次刚刚的卷子,看看考得怎么样
欸,问题就在这,数学老师怎么能让他再做一次刚刚的试卷呢,他刚刚做了一次,那再做一次,分数肯定不会比之前差呀,所以说这就是问题所在
那该怎么解决呢,相信你也知道,那肯定是让他做一套新的试卷呀,如果他在新试卷做得也不错,那就能证明他的实力,而不是存在偶然,所以这就是接下来介绍的解决方法
所以我们可以从数据中再分出一部分作为交叉验证用于选择最佳模型(第一套试卷),而测试集(第二套试卷)作为最终的误差报告:
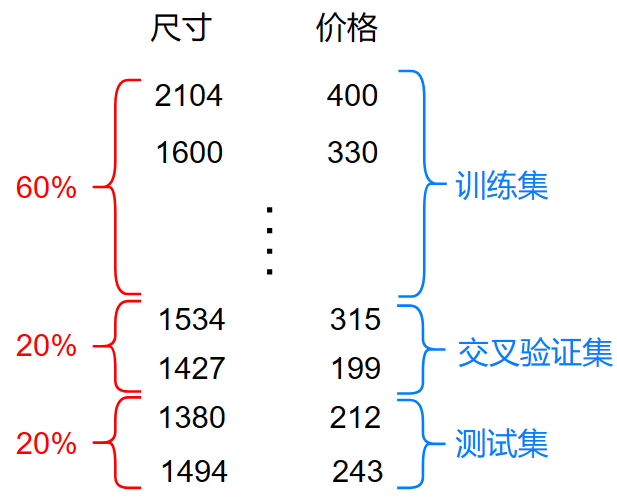
训练集和测试集我们之前已经说过了,说说交叉验证集:
- 对于若干个交叉验证集:
\[ \begin{gather} (x^{(1)},y^{(1)}) \\ (x^{(2)},y^{(2)}) \\ . \\ . \\ . \\ (x^{(m_{cv})},y^{(m_{cv})}) \end{gather} \]
上图中的 \(m_{cv}=2\) 也就是交叉验证集有2个
现在我们先计算 \(L_{cv}\) 选出最优模型之后,对模型计算 \(L_{test}\) 报告其泛化误差 \[ \begin{gather} d=1\qquad f(\vec{x})=w_1x_1+b\qquad\rightarrow\qquad L_{cv}(w^{<1>},b^{<1>}) \\ d=2\qquad f(\vec{x})=w_1x_1+w_2x^2+b\qquad\rightarrow\qquad L_{cv}(w^{<2>},b^{<2>}) \\ d=3\qquad f(\vec{x})=w_1x_1+w_2x^2+w_3x^3+b\qquad\rightarrow\qquad L_{cv}(w^{<3>},b^{<3>}) \\ . \\ . \\ . \\ d=10\qquad f(\vec{x})=w_1x_1+w_2x^2+w_3x^3+...+w_{10}x^{10}+b\qquad\rightarrow\qquad L_{cv}(w^{<10>},b^{<10>}) \end{gather} \] 此时用于筛选的 \(L_{cv}\) 和用于报告误差的 \(L_{test}\) 都是标准的,没有误差
对于神经网络:
对于神经网络也是同样的,从若干个不同隐藏层,不同神经元的神经网络中通过 \(L_{cv}\) 选出最佳模型,之后使用 \(L_{test}\) 报告泛化误差
偏差和方差(Bias and variance)
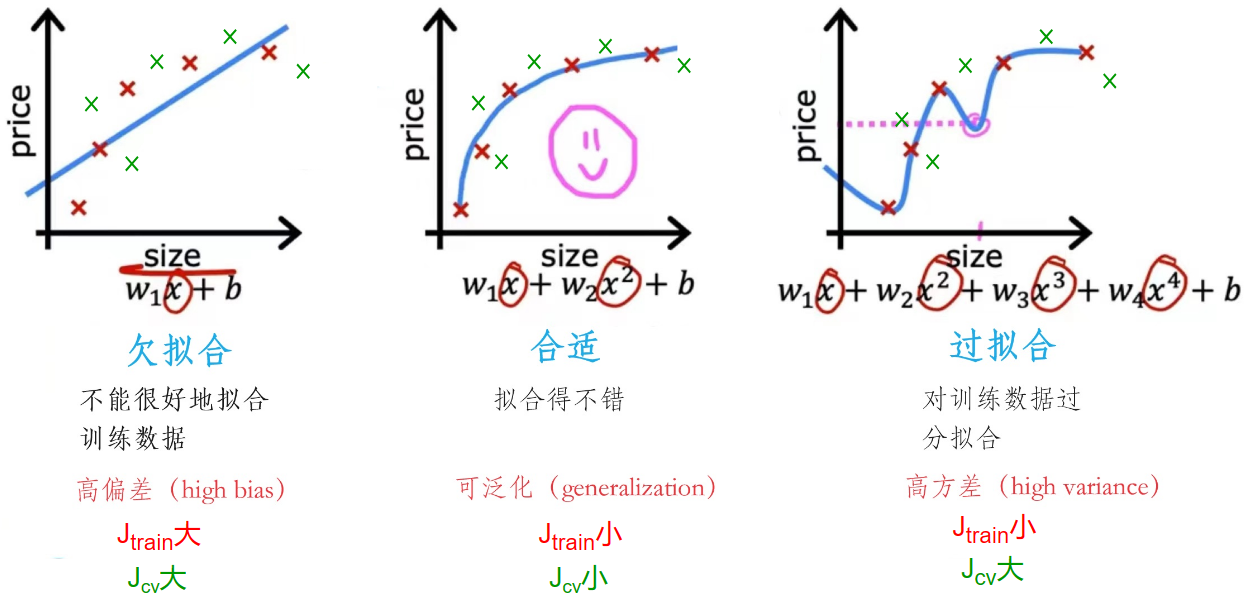
根据上图,绘制出 \(J_{cv}、J_{train}\) 的曲线:
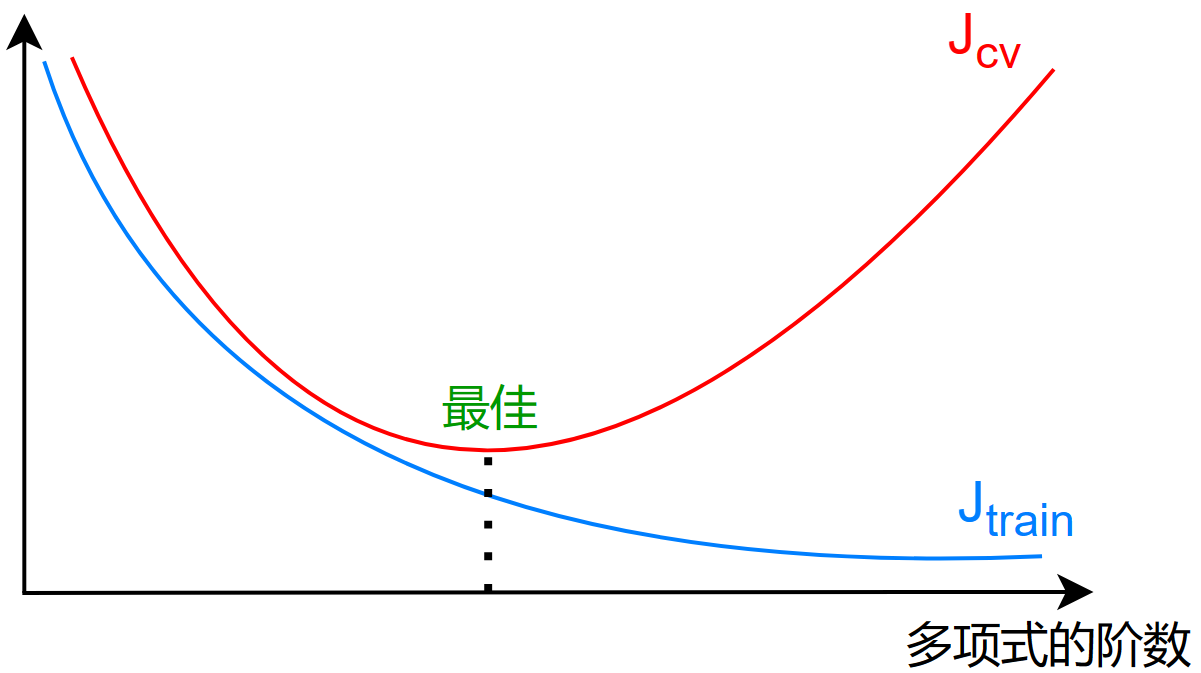
对于以上的曲线有以下特点:
高偏差(欠拟合)
- \(J_{train}\) 很高
- \(J_{train}\approx J_{cv}\)
高方差(过拟合)
- \(J_{cv}\gg J_{train}\)
- \(J_{train}\) 很低
高方差和高偏差(神经网络中常见)
- \(J_{train}\) 较高
- 但是 \(J_{cv}\gg J_{train}\)
选择正则化参数
选择正则化参数可以和之前选择不同的模型一样,尝试从小到大的参数 \(\lambda\) 通过计算其 \(L_{cv}\) 选出最佳的参数 \(\lambda\) 之后计算 \(L_{test}\) 报告泛化误差
正则化的偏差和方差
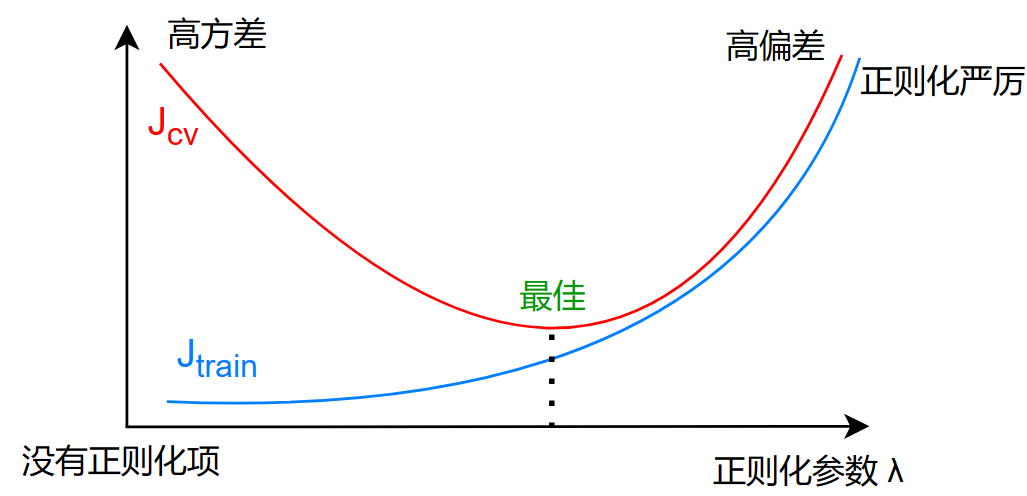
对于损失函数: \[ J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum_{j=1}^nw_j^2 \] 有 \(J_{cv}、J_{train}\) 的曲线:
高偏差和高方差判断
如何判断一个模型是高偏差还是高方差呢,或者说,怎样才算高偏差或高方差?
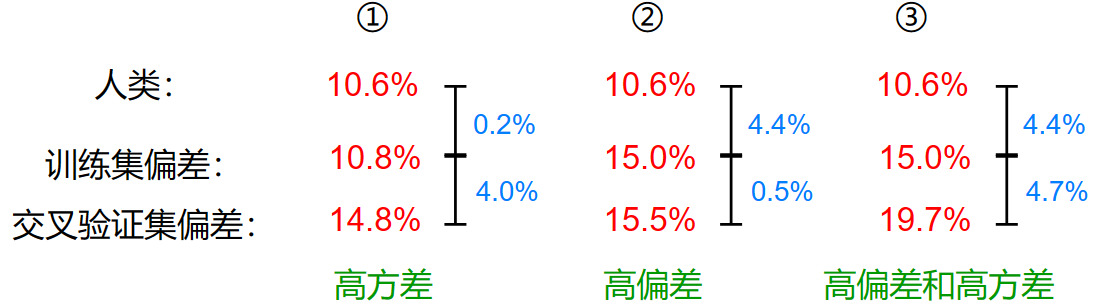
给出一个例子:
我们有一个语音识别模型:
- 训练集偏差:10.8%
- 交叉验证集偏差:14.8%
如果单单看这些数据,你可能会认为这个模型存在高偏差和高方差
但是,如果没有一个判断标准,这样的判断可能是错误的
如果我告诉你,正常人对语音的识别误差为:10.6% 那么:
- 正常人:10.6%
- 训练集偏差:10.8%
- 交叉验证集偏差:14.8%
这样看起来,训练集表现得不错
那么,哪些可以作为判断的标准呢?
- 人类的平均水平
- 计算机算法的表现
- 根据生活经验猜测
下面有一些例子,判断是否存在高偏差或高方差
学习曲线(Learning curves)
对于一个模型,画出 \(L_{cv}、L_{train}\) 随着训练数据增加的变化曲线
- 对于一个合适的模型,其曲线应该是这样的:
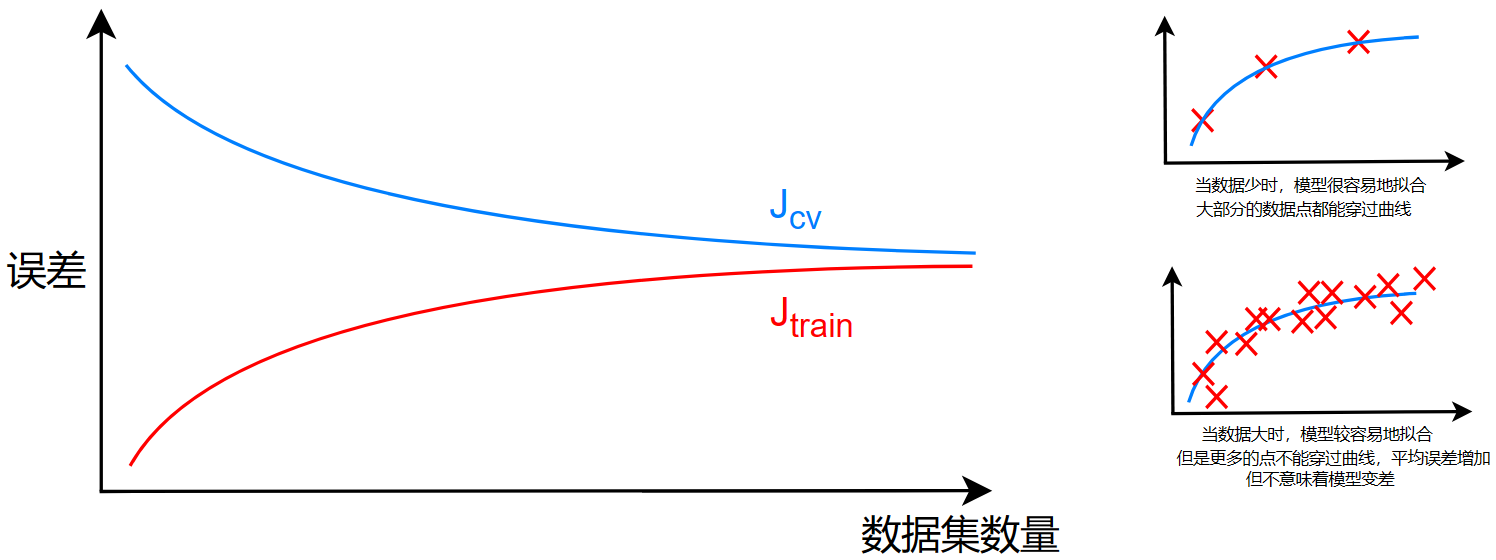
当模型数据量少时,模型能够精准地拟合,让绝大部分的点都能穿过曲线
当数据集增大时,模型有些力不从心了,没有穿过曲线的点越来越多,但是没有穿过曲线的点也能够在曲线附近,所以平均误差逐渐增大
后期逐渐平缓,由于数据的增大,分母增大,分子即总偏差也增大,但是增大幅度没有数据量,即分母的增大幅度大,故总体的分数变化趋于缓慢
- 对于一个高偏差模型:
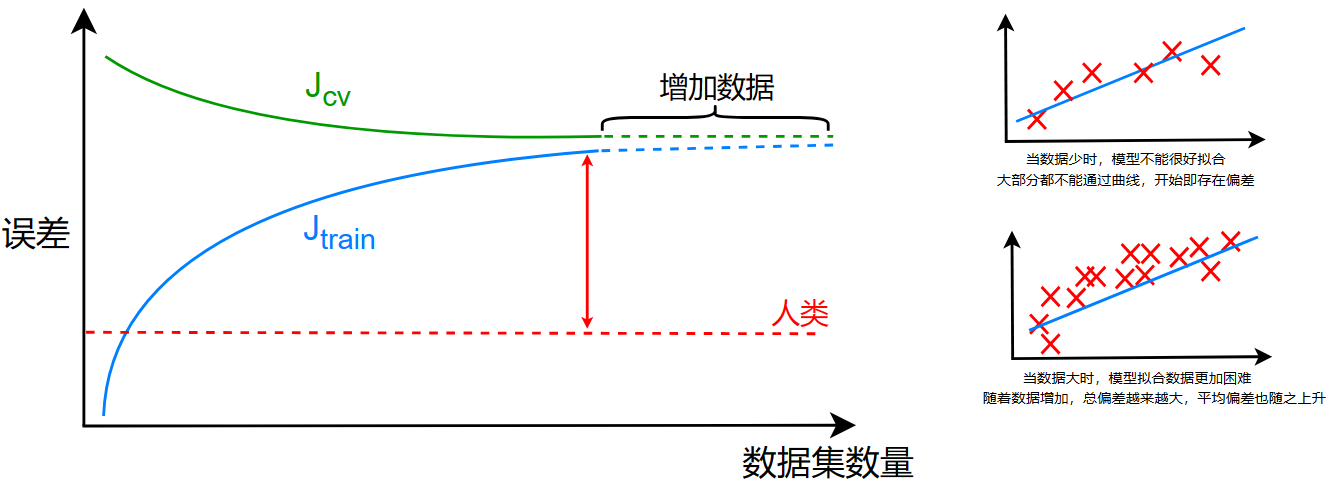
当数据量少时,由于存在欠拟合,一开始就不能很好拟合,存在偏差
当数据越来越大时,分子即总偏差的增大幅度远远比分母,即数据量的增大幅度大,总体分数也随之逐渐增大
在后期,由于曲线的形状趋于稳定,而数据的分布也趋于稳定,此时的分子增大的幅度没有分母大,整体分数趋于稳定
- 对于一个高方差模型:
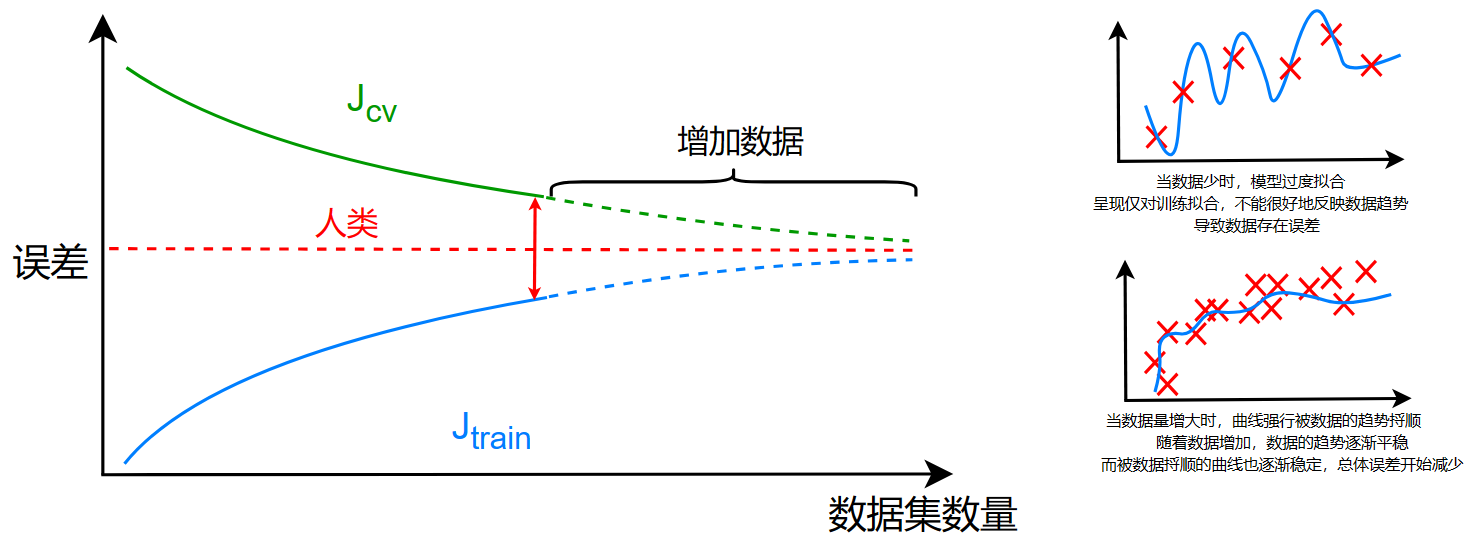
当数据量少时,模型过度拟合,呈现仅对训练拟合,不能很好地反映数据趋势,存在误差
当数据量增大时,数据的分布也体现出其趋势,而过拟合的曲线也渐渐被这种趋势所捋顺
在后期,由于曲线的形状趋于稳定,而数据的分布也趋于稳定,此时的分子增大的幅度没有分母大,整体分数趋于稳定
结论:
从图中来看,增加数据对高方差的模型有效
但是增加数据的缺点就是会增大计算量
偏差和方差的权衡(tradeoff)
你有一个线性回归模型: \[ J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum_{j=1}^nw_j^2 \] 这个线性回归模型有很大的偏差,以下是缓解的方法:
| 方法 | 效果 |
|---|---|
| 获得更多的数据集 | 缓解高方差 |
| 尝试减少特征 | 缓解高方差 |
| 尝试增加特征 | 缓解高偏差 |
| 尝试增加特征维度 \((x_1^2,x_2^2,x_1x_2,...)\) | 缓解高偏差 |
| 减小正则化参数 \(\lambda\) | 缓解高偏差 |
| 增加正则化参数 \(\lambda\) | 缓解高方差 |
如果我们在训练一个网络,以下可能是一些流程:
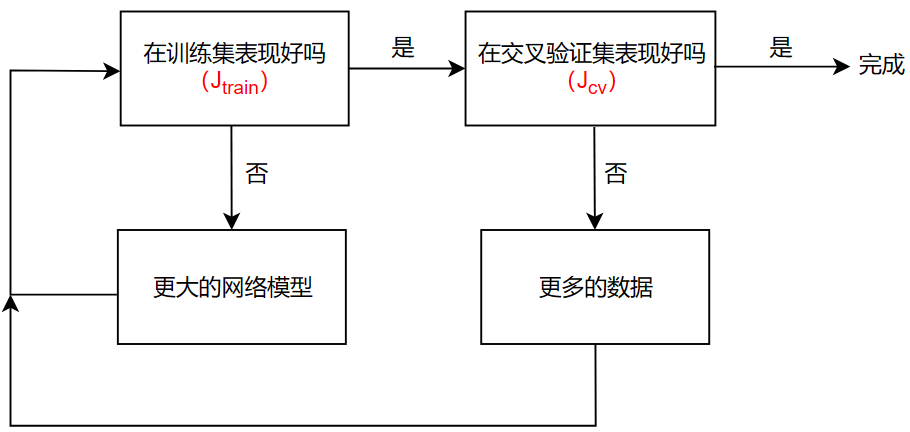
事实上,如果在一个复杂的神经网络里增加合适的正则化项,它可以和更小的神经网络表现的差不多或比其表现得更好,但同时也会增加计算量
复杂的网络将总是一个低偏差的网络,困扰我们更多的是过拟合带来的高方差
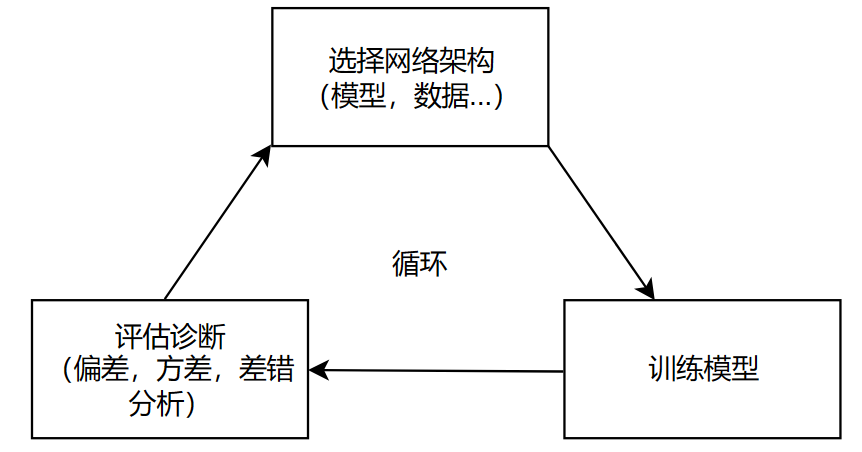
机器学习流程
案例(垃圾邮件分类)
如何构建一个垃圾邮箱分类器?
监督学习:
- 特征 \(\vec{x}\) 邮箱的特征
- y:是否为垃圾邮件
特征 \(\vec{x}\) 可能是一些垃圾邮件的关键词组成的独热码(one-hot code)
独热码是一系列由 0和1 组成的数据,其中 0 表示无,1 表示有
| 输入 | 促销 | 甩卖 | 折扣 | 马上 | ... |
|---|---|---|---|---|---|
| \(\vec{x}\) | 1 | 0 | 1 | 1 | ... |
那么输入为: \[ \vec{x}= \begin{bmatrix} 1 \\ 0 \\ 1 \\ 1 \end{bmatrix} \] 那么输入就表示:该邮件中含有:“促销”、“折扣”、“马上”。等关键词
怎么减少垃圾邮件分类器的误差?
- 收集更多的数据
- 草船借箭法:故意泄露自己的或者虚拟的邮箱,以此来吸引更多的垃圾邮件,获得数据
- 使用计算机网络,对发送垃圾邮箱的路由地址进行分析,或将其作为输入特征之一
- 将一些近义词作为同一个特征,防止特征过多
- 一些垃圾邮件发送者会故意写错字,来绕过垃圾邮件检测系统
- 例如:醋消,帅麦,忧慧,斤扣,等等
数据增强(Data augmentation)
如果增加数据的方式很有限,或者很慢,那么数据增强将会是一个不错的方法
使用数据增强增加数据量的方式:
- 对于图形数据来说,可以对一个图形进行旋转,切割,缩放等方式来获取大量的不重复的数据
- 对于文字类型的数据,可以通过对文字使用不同的字体,颜色等方式来获取
数据增强不仅仅用于增加数据的数量,还可以增强模型的鲁棒性:
- 对图形数据加上干扰
- 马赛克
- 扭曲图片
- 不完整的图片
- 对语音数据加上干扰
- 环境噪声
- 断断续续的声音
- 不完整的声音
对数据进行加噪等方式,能够让模型在实际应用中克服各种环境的影响,增强了模型的在复杂环境下的准确性
在自己的模型中使用数据工程
以模型为中心: \[ AI=CODE+data \] 专注于代码层面:算法,模型
以数据为中心: \[ AI=DATA+code \] 专注于数据层面
对于机器学习来说,好的模型固然重要,但是给模型合适的更加丰富的数据,将会使模型运行得更好
迁移学习(Transfer learning)
有时候,从0开始训练一个模型,可能不如使用别人的模型来得快
如果你手上有一个目标检测模型,目标数量为1000个,但是你想要一个手写模型,只需要10个目标(0~9)
该怎么把这个模型化为己用?
更改已有模型的一些部分即可:
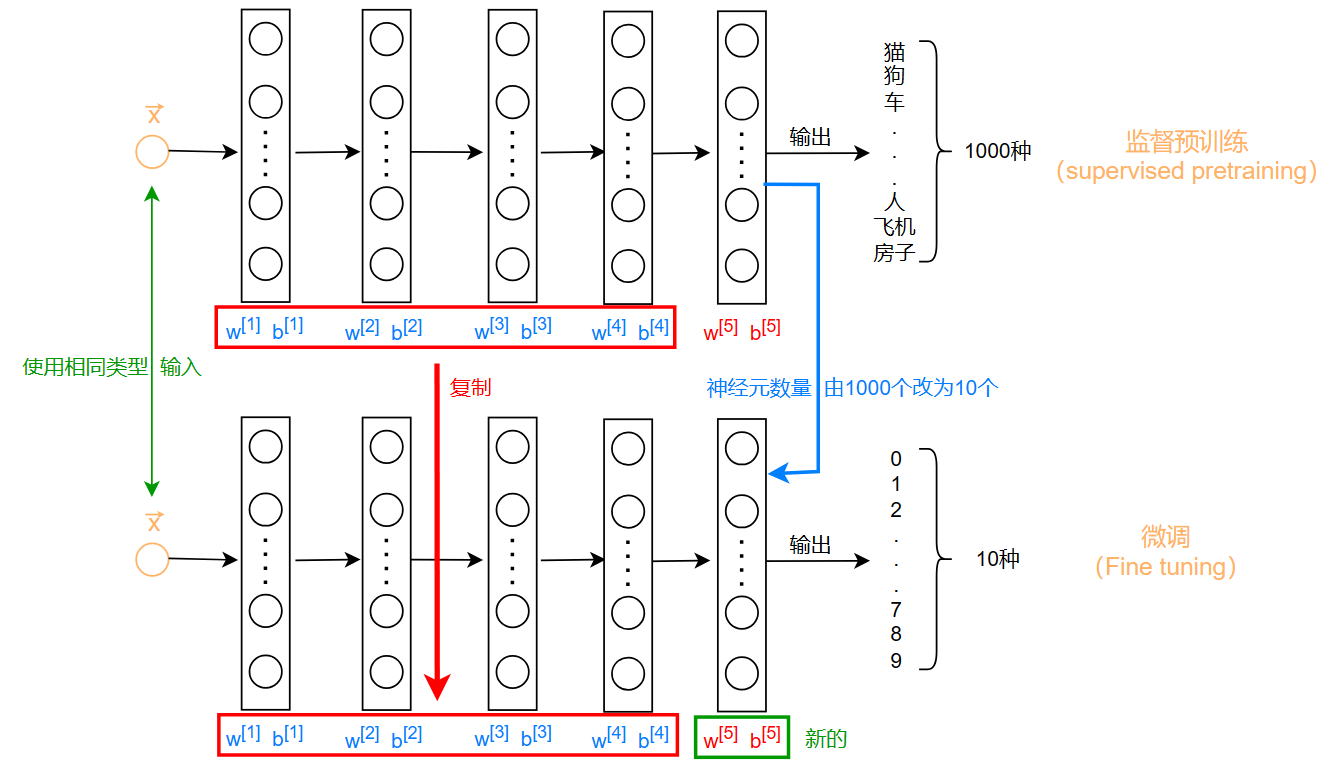
迁移学习的两种训练方法:
- 只训练输出层的参数:拥有很少的数据(num<10000)
- 训练所有的参数:用于大量数据(num>10000)
总结
- 从网上下载神经网络参数之后,使用大量的(num>1000000)和你自己的模型具有相同输入的数据进行预训练
- 在你自己的数据集(50<num<1000)上进行微调
完整的机器学习流程

实际应用

软件工程:
- 确保模型可靠和预测准确
- 扩展
- 日志
- 系统监控
- 模型更新
MLOps:机器学习操作(Machine learning operations)
混淆矩阵(Confusion matrix)
这部分已经在之前发布的文章:《简述机器学习中的入门数学原理》中讲到,且很详细,这里不做赘述
总结
本文章讲了监督学习的神经网络,同时也讲了一些其他概念:激活函数,诊断评估,学习曲线,迁移学习,数据增强等。
在接下来,我们将学习另一种监督学习或者说深度学习算法——决策树(Decision trees)
这个算法常常用于机器学习竞赛中,且有不错的效果!
从0了解机器学习:4——神经网络