从0了解机器学习:3——分类
本文章将介绍监督学习中的分类算法,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
分类(Classification)
分类一般为
- 二分类
- 多分类
以下是二分类问题的一些应用:
| 问题 | 输出 \(y\) |
|---|---|
| 是否为垃圾邮件 | 是/否 |
| 是否存在交易欺诈 | 是/否 |
| 是否为恶性肿瘤 | 是/否 |
如果 \(y\) 仅为两种值中的一种,称其为:二分类(binary classification)
二分类中,常常使用 0和1 作为输出值: 否/是 事实证明,这样做是非常有用的
对于二分类来说,最常见的例子就是乳腺癌的良性和恶性的分类:
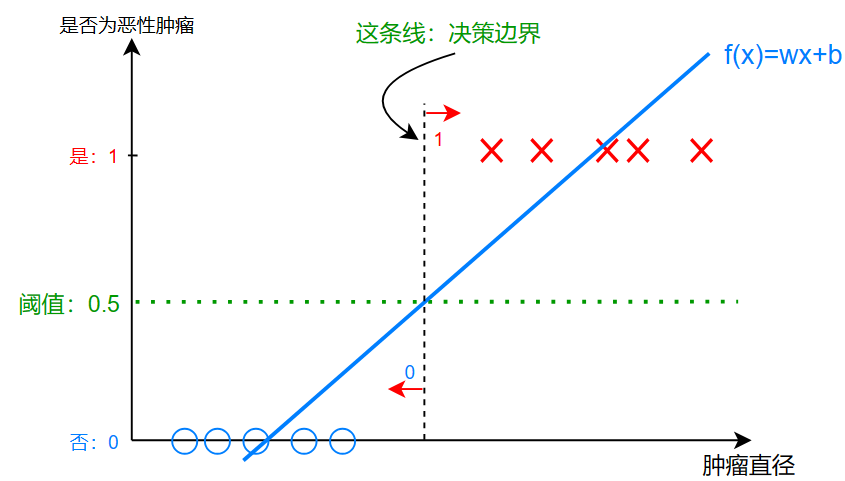
将训练数据按照如图画在坐标轴上,其中:0为良性,1为恶性
我们可以像线性回归一样,不把它看作是分类问题,而是简单的设置一个线性函数:\(f_{w,b}(x)=wx+b\) 使用线性回归的方法,拟合一条直线,就像图中这样
接下来,我们设置一个阈值(threshold):0.5(对于大多数二分类,这是一个很好的选择)
决策边界(decision boudary / dividing line)
此时,将阈值 \(y=0.5\) 与 \(f_{w,b}(x)=wx+b\) 相交处作垂线,此时这个垂线就是所谓的决策边界
决策边界左侧的为良性肿瘤 \(y=0\) 而右侧的为恶性肿瘤 \(y=1\)
使用线性函数作为激活函数的缺点:
要求两类数据分布较为集中,如果分布松散,那么决策边界就会产生很多的错误分类结果
只能拟合单特征的数据,对于复杂特征的数据就不能拟合
我们看看具体情况:
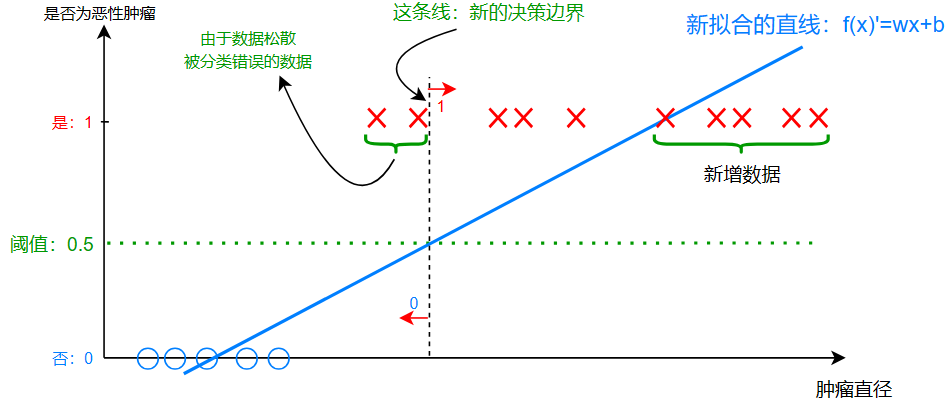
上图中,我们新增了几个靠右的数据,我们发现新拟合的直线斜率变小,而决策边界也随着右移,这使得恶性肿瘤中,直径较小的数据被分类为良性,这在现实中将会造成很大影响
那么该怎么解决呢?
逻辑回归(Logistic regression)
而对于以上的问题,我们想要的函数应该是能将两类数据完美分类的,而且对数据拟合也很好的函数
理想效果应该是这样:
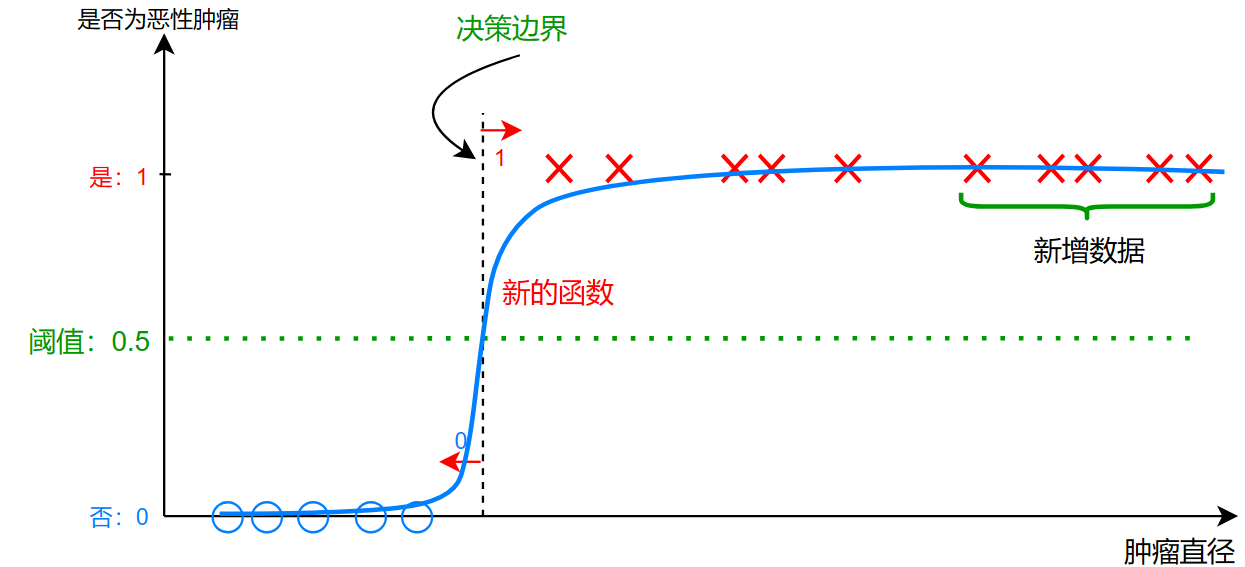
那么,这个函数好眼熟啊,是不是我们在数学基础里提到的 sigmoid 函数:
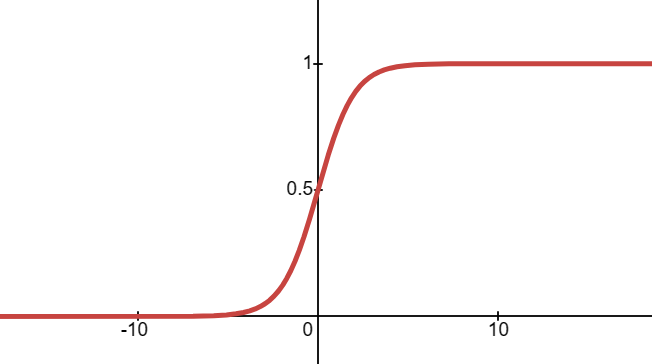 \[
sigmoid=\frac{1}{1+e^{-x}}
\] 这个函数也被称为逻辑函数
\[
sigmoid=\frac{1}{1+e^{-x}}
\] 这个函数也被称为逻辑函数
逻辑回归模型
对于 sigmoid 函数,我们将其规定为: \[ g(z)=\frac{1}{1+e^{-z}} \] 对于:\(f_{w,b}(\vec{x})\) 令: \[ \begin{gather} z=\vec{w}\cdot\vec{x}+b \\ \downarrow \\ z \\ \downarrow \\ g(z)=\frac{1}{1+e^{-z}} \end{gather} \] 写出最终形式: \[ f_{w,b}(\vec{x})=g(\vec{w}\cdot\vec{x}+b)=\frac{1}{1+e^{-(\vec{w}\cdot\vec{x}+b)}} \] 对于以上式子,我们称其为:逻辑回归
规定其输出: \[ f_{\vec{w},b}(\vec{x})=0.7\rightarrow \begin{cases} 70\%\;:\;y=1 \\ 30\%\;:\;y=0 \end{cases} \] 有时你可能还会见到其他形式: \[ f_{\vec{w},b}(\vec{x})=P(y=1|\vec{x};\vec{w},b) \] 上述式子含义为:给定输入:\(\vec{x}\) ,和参数 \(\vec{w},b\) 后,输出 \(y=1\) 的可能
决策边界(Decision boundary)
对于 sigmoid 函数而言,当 Z 仅仅含有 x 时: \[ \begin{gather} f(x)=\frac{1}{1+e^{-x}} \\ z=x \end{gather} \]
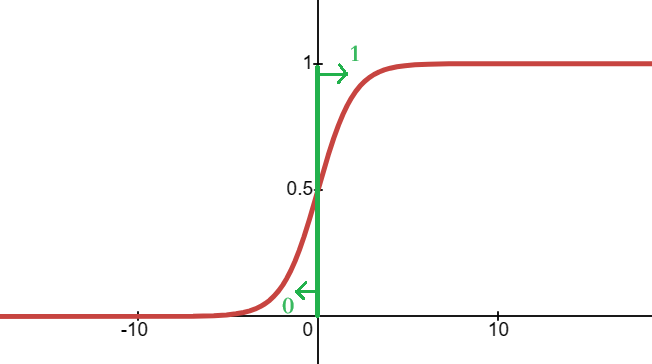
很显然,决策边界为:\(z=x=0\)
为什么决策边界是 \(x=0\) 呢?
因为决策边界是我们函数与阈值的交点决定的,而当阈值为 0.5 时: \[ \begin{gather} f(x)=0.5\quad\Rightarrow\quad\frac{1}{1+e^{-z}}=0.5\quad\Rightarrow\quad\ z=0 \\ \because\;z=x \\ 解得:\quad x=0 \end{gather} \] 所以说,决策边界就是 \(x=0\) 的直线
所以说得出一个结论:决策边界就是 \(z=0\) 构成的的线
让我们看看一个复杂的例子,来验证这个结论:
对于以下数据,使用 sigmoid 函数拟合:
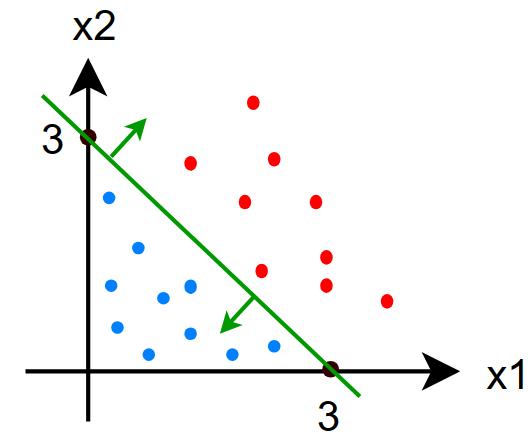
我们会得到拟合后的 sigmoid 函数: \[ \begin{gather} f(x)=g(z)=g(x_1+x_2-3)=\frac{1}{1+e^{-(x_1+x_2-3)}} \\ z=x_1+x_2-3 \end{gather} \] 让我们使用结论:决策边界为 \(z=0\) 的直线: \[ \begin{gather} z=x_1+x_2-3=0 \\ \Rightarrow\quad x_1+x_2=3 \end{gather} \] 我们观察图中的决策边界,决策边界确实为直线:\(x_1+x_2=3\)
那更复杂的呢?
还是一样的道理
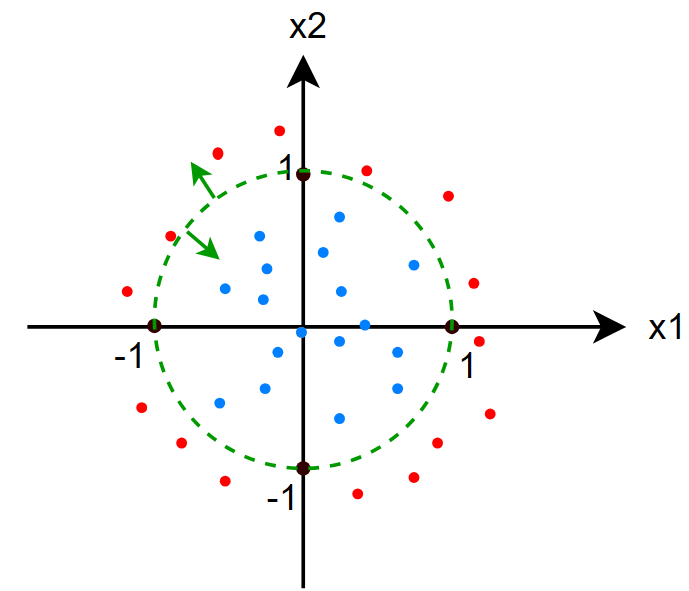
对于以上数据我们拟合 sigmoid 函数,得到: \[ \begin{gather} f(x)=g(z)=g(x_1^2+x_2^2-1)=\frac{1}{1+e^{-(x_1^2+x_2^2-1)}} \\ z=x_1^2+x_2^2-1 \end{gather} \] 那么决策边界就是: \[ \begin{gather} z=x_1^2+x_2^2-1=0 \\ \Rightarrow\quad x_1^2+x_2^2=1 \end{gather} \] 在图中我们看到,决策边界确实为:\(x_1^2+x_2^2=1\) 的圆
以上就是决策边界:
你可以组合 \(x_1\;or\; x^n\) 去创造一些你想要的复杂的决策边界,如果 \(z\) 只是线性的,那么你的决策边界也永远是线性的
损失函数(Loss function)
在线性回归中,我们使用 MSE 均方差 作为损失函数 \[ MSE=L(\vec{w},b)=\frac{1}{n}\sum_{i=1}^m\frac{1}{2}(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2 \] 对线性回归来说: \[ f_{\vec{w},b}(x)=\vec{w}\cdot\vec{x}+b \] 使用MSE作为损失函数,其梯度下降就像这样:是一个凸(convex)函数
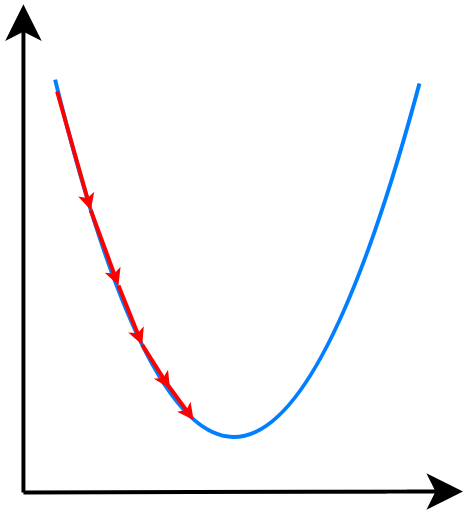
而对于逻辑回归来说: \[ f_{\vec{w},b}(\vec{x})=\vec{w}\cdot\vec{x}+b \] 使用MSE作为损失函数,其梯度下降就像这样:是非凸(non-convex)函数
而且有很多的局部最小值
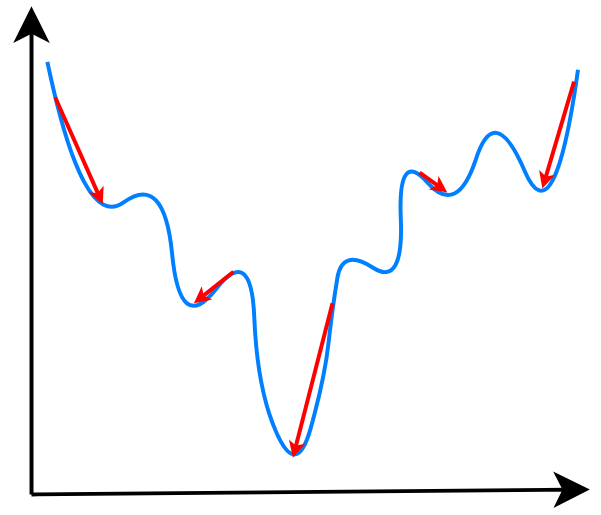
所以说,该怎么给逻辑回归制定一个合适的损失函数呢?
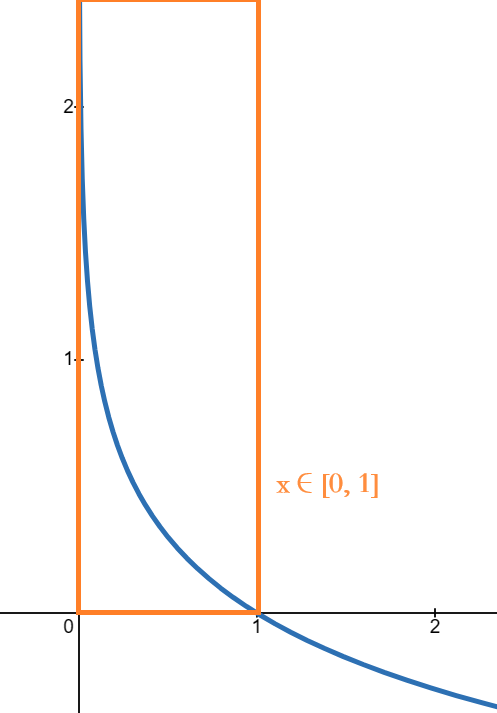
其实这个在数学基础那里提到过,就是似然函数化简,这里也类似: \[ L(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)})= \begin{cases} -log(f_{\vec{w},b}(\vec{x}^{(i)}))\qquad y^{(i)}=1 \\ -log(1-f_{\vec{w},b}(\vec{x}^{(i)}))\qquad y^{(i)}=0 \end{cases} \] 对于 \(y^{(i)}=1:\quad -log(f_{\vec{w},b}(\vec{x}^{(i)}))\) 来说:
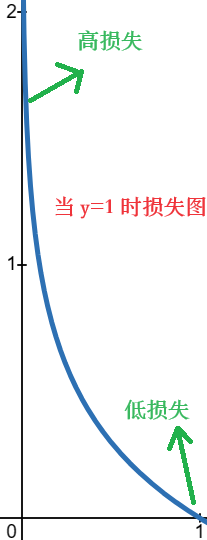
这个函数图满足了逻辑损失函数 \(y^{(i)}=1\) 的特点:
- 当输出 \(f(x)\rightarrow1\) 时,也就是输出越接近正确答案,那么损失值越小
- 当输出 \(f(x)\rightarrow0\) 时,也就是输出越接近错误答案,那么损失值越大
对于 \(y^{(i)}=0:\quad -log(1-f_{\vec{w},b}(\vec{x}^{(i)}))\) 来说:
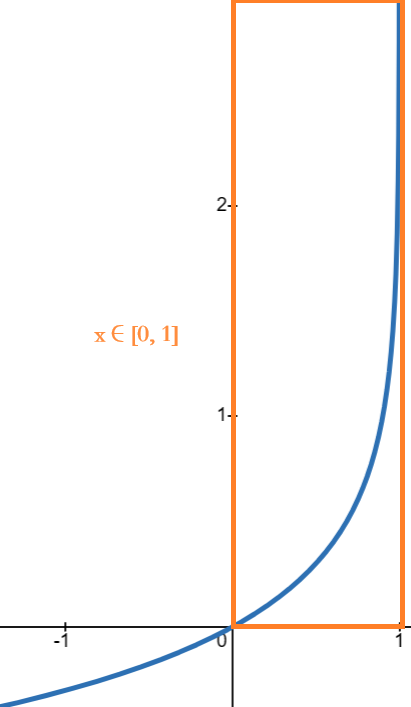
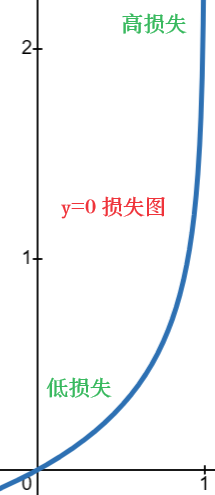
这个函数图满足了逻辑损失函数 \(y^{(i)}=0\) 的特点:
- 当输出 \(f(x)\rightarrow0\) 时,也就是输出越接近正确答案,那么损失值越小
- 当输出 \(f(x)\rightarrow1\) 时,也就是输出越接近错误答案,那么损失值越大
因此,最终的损失函数为: \[ J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^mL(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)}) \] 将损失函数变为这样之后,我们看其梯度下降:
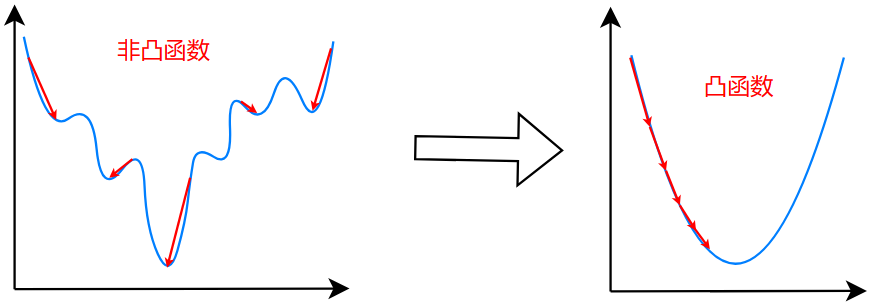
现在,逻辑回归的梯度下降,变得十分顺滑,没有局部最小值(上图只是示意,实际并不长这样)
现在,有了损失函数,我们要做的就是找到能使得损失函数最小的 \(w,b\)
简化损失函数(Simplified loss function)
简化损失函数,在数学基础那里就已经提过,这里作简要讲解: \[ L(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)})= \begin{cases} -log(f_{\vec{w},b}(\vec{x}^{(i)}))\qquad y^{(i)}=1 \\ -log(1-f_{\vec{w},b}(\vec{x}^{(i)}))\qquad y^{(i)}=0 \end{cases} \] 对于以上的式子,我们可以写成: \[ \begin{gather} L(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)})=-y^{(i)}log(f_{\vec{w},b}(\vec{x}^{(i)}))-(1-y^{(i)})log(1-f_{\vec{w},b}(\vec{x}^{(i)})) \\ \Downarrow \\ J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^mL(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)}) \\ \Downarrow \\ J(\vec{w},b)=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}log(f_{\vec{w},b}(\vec{x}^{(i)}))+(1-y^{(i)})log(1-f_{\vec{w},b}(\vec{x}^{(i)}))] \end{gather} \] 最后我们的目标就是让 \(J(\vec{w},b)\) 最小,这里让他最小的方法,还是梯度下降
梯度下降
对于损失函数: \[ J(\vec{w},b)=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}log(f_{\vec{w},b}(\vec{x}^{(i)}))+(1-y^{(i)})log(1-f_{\vec{w},b}(\vec{x}^{(i)}))] \] 我们知道梯度下降的参数更新表达式: \[ \begin{gather} w_j=w_j-lr\cdot\frac{\partial}{\partial w_j}J(\vec{w},b) \\ b=b-lr\cdot\frac{\partial}{\partial b}J(\vec{w},b) \end{gather} \] 对于 \(w_j\) : \[ \frac{\partial}{\partial w_j}J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})x^{(i)} \] 对于 \(b\) : \[ \frac{\partial}{\partial b}J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)}) \] 带入表达式中,得到最终的参数更新表达式: \[ \begin{gather} w_j=w_j-lr\cdot\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})x^{(i)} \\ b=b-lr\cdot\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)}) \end{gather} \] 对于逻辑回归,也可以像线性回归一样,使用:
- 监控梯度下降
- 向量化
- 特征缩放
逻辑回归的参数更新表达式看起来和线性回归差不多啊!
没错,看起来他们二者确实一模一样,但是注意的是:
- 线性回归的激活函数 \(f_{\vec{w},b}(\vec{x}^{(i)})\) 是 \(\vec{w}\cdot\vec{x}+b\)
- 逻辑回归的激活函数 \(f_{\vec{w},b}(\vec{x}^{(i)})\) 是 \(\frac{1}{1+e^{-(\vec{w}\cdot\vec{x}+b)}}\)
过拟合(Overfitting)
合适的模型,它的泛化(generalization)能力都很好,也就是能够在训练集和测试集中表现的很好
而一些情况不能很好得兼顾训练集和测试集:
- 高偏差(high bias):往往代表着存在欠拟合
- 高方差(high variance):往往代表着存在过拟合
而高偏差和高方差的产生,在之后再讲
让我们看一个例子:有两个特征的乳腺癌人群的数据:
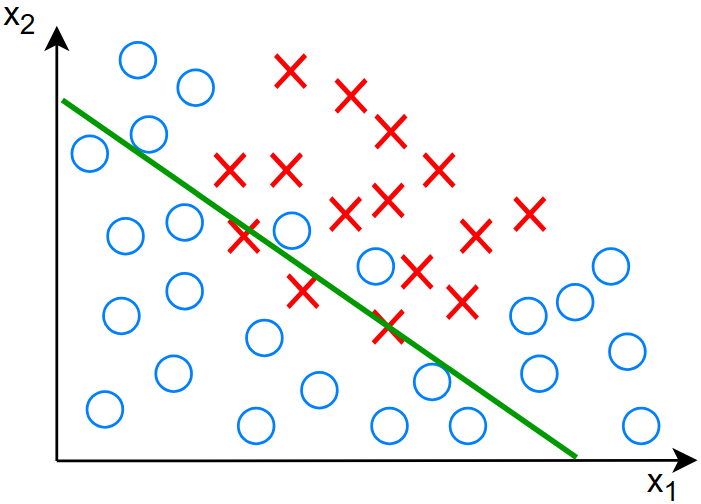
对于以上决策边界有: \[ \begin{gather} z=w_1x_1+w_2x_2+b \\ f_{\vec{w},b}(\vec{x})=g(z) \end{gather} \] 其中的激活函数为 sigmoid 函数
对于这样的分类结果,明显是欠拟合,且具有高偏差
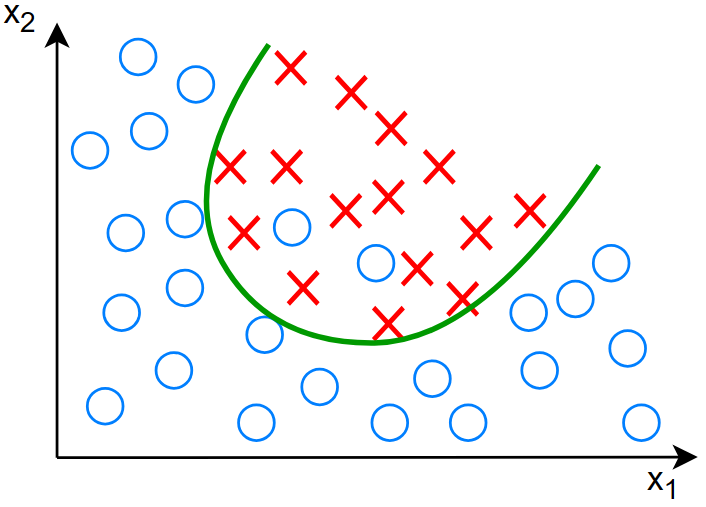
对于以上决策边界有: \[ \begin{gather} z=w_1x_1+w_2x_2+w_3x_1^2+w_4x_2^2+w_5x_1x_2+b \\ f_{\vec{w},b}(\vec{x})=g(z) \end{gather} \] 其中的激活函数为 sigmoid 函数
显然,此次分类的结果很合适,对于测试集有很好的泛化性
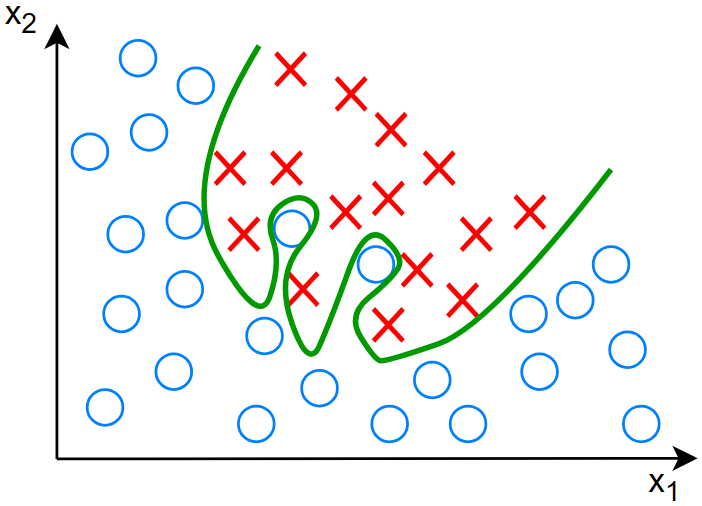
对于以上决策边界有: \[ \begin{gather} z=w_1x_1+w_2x_2+w_3x_1^2x_2+w_4x_2^2x_1^2+w_5x_1^2x_2^3+...+b \\ f_{\vec{w},b}(\vec{x})=g(z) \end{gather} \] 其中的激活函数为 sigmoid 函数
对于这样的分类结果,明显过拟合了,训练的模型对于训练集拟合过度,对测试集不能有很好的泛化性,具有高方差
解决办法
- 收集更多的训练数据
- 选择一些特征或抛弃一些特征(特征选择 feature selection)
- 使用所有的特征可能会引起过拟合,可以选择一些对能够对结果产生影响的有用的特征
- 缺点是一些有用的特征可能无法通过直觉选择出来
- 正则化
正则化(Regularization)
在数学原理那篇文章中介绍过正则化,但只是介绍了正则化是作为削弱过拟合的一个手段
而正则化的目标是减少参数 \(w_j\) 的大小,接下来将介绍正则化减小参数的原理
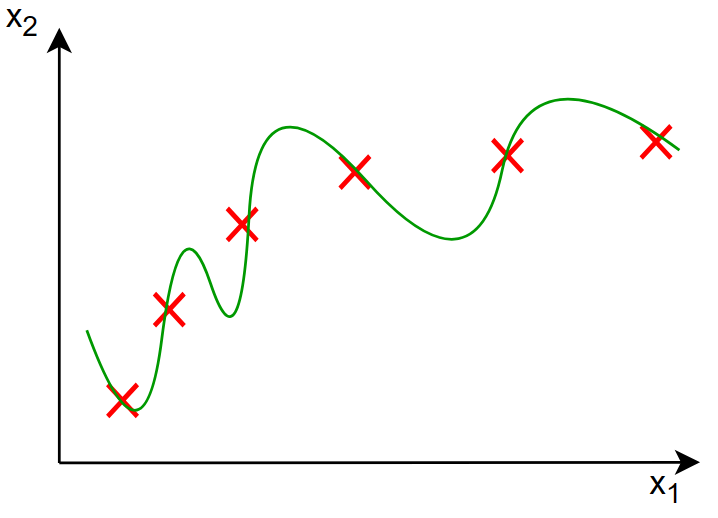
对于上图,其特征为: \[ f(x)=28x-385x^2+39x^3-174x^4+100 \] 我们发现,特征中存在着很大的参数 \(w_j\) 如:385,174
这意味着这些参数对应的特征主导了整个模型的训练过程,容易出现过拟合,而我们可以试着减小对应的参数来削弱其对模型的影响,就像这样:
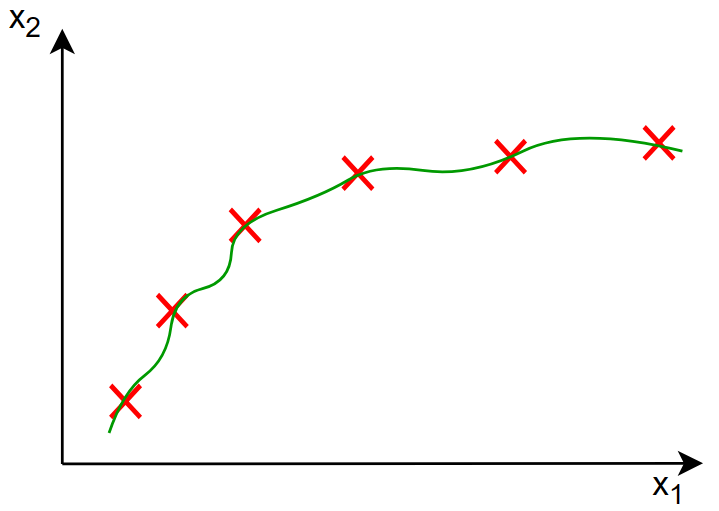
对于上图,是我们经过调整对应参数之后的图像,发现过拟合的现象不那么明显,而其参数为: \[ f(x)=13x-0.23x^2+0.000014x^3-0.0001x^4+10 \] 而此时,0.000014和0.0001对于参数 \(w_j\) 来说以及很小了,能够有效减小对于特征的影响
通常地:
我们只对参数 \(w_j\) 进行正则化,而 \(b\) 一般不进行正则化,而在正则化中,我们一般会将 \(w_j\) 减小到接近于0,而不是等于0,仍然保留其特征的影响,只不过不让其影响过大
正则化减小参数的原理:
举一个生活中的例子,如果我们想要在15分钟左右将一个水池的水放干,不能放得太快,因为水流太大容易把东西冲走,也不能放得太慢因为等不了太长时间,但是我们只能通过打开水池的水龙头来进行放水,但是只通过水龙头,放干整个水池的时间远大于15分钟
如果此时,我告诉你水池自带一个抽水泵,那么你如果想要尽快把水放干,你肯定会去使用那个抽水泵进行放水,但是如果抽水泵功率全开,那么水放得太快了,也不行
所以说我们需要调节抽水泵的功率以及使用时间才能将放水时间控制在15分钟左右
而例子中的抽水泵就是正则化项,抽水泵的功率就是正则化的权重
水池可以有多个,对应多个特征,每个水池都有一个抽水泵,对应每个特征都可以拥有一个正则化项
回到正题上来:
我们的目标是想要损失函数最小,那么结合之前放水的例子,我们可以在损失函数的后面加一个“抽水泵”,就像这样: \[ J=Loss+1000w_3^2+1000w_4^2 \] 怎么理解呢:
如果我们想要 \(J\) 最小,那么可以减小 \(Loss\) 和 \(1000w_3^2+1000w_4^2\)
当算法发现,减小 \(Loss\) 的收益远不如减小 \(1000w_3^2+1000w_4^2\) 来得快,那么算法就会减小 \(w_3、w_4\)
这样就能够实现减小参数值的功能了,这就是正则化的原理
但是有一个问题:
Q:我们不知道哪些参数或特征需要正则化,哪些不需要正则化,该怎么办呢?
A:那就干脆对所有的参数或特征进行正则化
因为算法会在计算的过程中发现:哪些参数需要使劲正则化,哪些参数可以不需要或者只需要稍微进行正则化
其实这就是机器学习聪明的点,它会像人一样学习并发现!
那么加了正则化项的损失函数是什么样的: \[ J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum_{j=1}^mw_j^2+(\frac{\lambda}{2m}b^2)\qquad一般不对b正则化,括号中的可以去掉 \] 以上的例子,包括加了正则化的损失函数,都是线性回归问题,不是分类问题
其实逻辑回归的正则化也一样,在损失函数后面加上正则化项:\(\frac{\lambda}{2m}\sum_{j=1}^mw_j^2\)
其中,参数 \(\lambda\) 是正则化参数,或者正则化权重
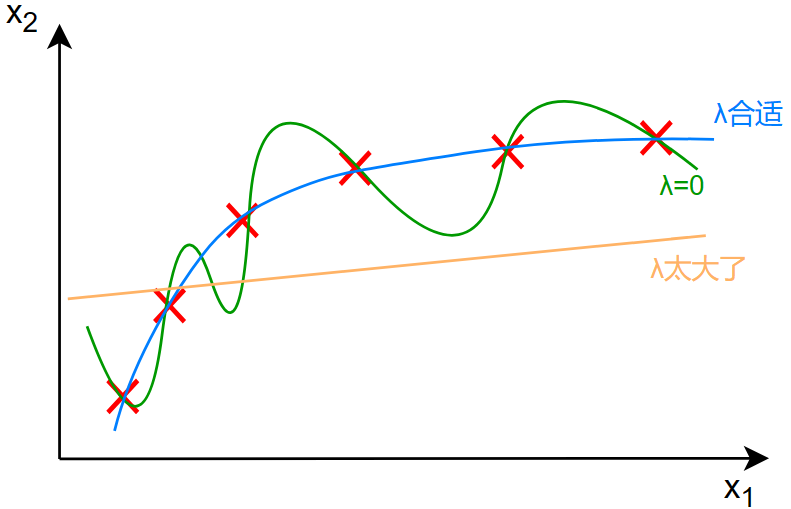
为什么 \(\lambda\) 太大的时候,接近于一条直线?
假如 \(\lambda=10000000000000000000000\) 那么: \[ \begin{gather} f(x)=\bcancel{w_1x}+\bcancel{w_2x^2}+\bcancel{w_3x^3}+\bcancel{w_4x^4}+b \\ \Rightarrow\quad f(x)\approx b \end{gather} \] 所以说调整 \(\lambda\) 的值是很重要的
带有正则化项的参数更新表达式
这里用线性回归的例子来计算: \[ J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum_{j=1}^mw_j^2 \] 对于 \(w_j\) : \[ \frac{\partial}{\partial w_j}J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}w_j \] 对于 \(b\) : \[ \begin{gather} \frac{\partial}{\partial b}J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)}) \\ 因为不对\;b\;进行正则化 \end{gather} \] 最后得到的参数更新表达式: \[ \begin{gather} w_j=w_j-lr\cdot[\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}w_j] \\ b=b-lr\cdot[\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})] \end{gather} \]
正则化的另外一种理解
让我们对 \(w_j\) 的参数更新表达式化简: \[ \begin{gather} w_j=w_j-lr\cdot[\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}w_j] \\ w_j=w_j(1-lr\cdot\frac{\lambda}{m})-lr\cdot\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(x^{(i)})-y^{(i)})x_j^{(i)} \\ (1-lr\cdot\frac{\lambda}{m})<1 \end{gather} \] 所以说,正则化其实就是在每次更新时,将上一次更新的参数 \(w_j\) 乘以一个小于1的值
这样每一次更新时,参数 \(w_j\) 的值都会越来越小
总结
本文章讲了监督学习中的分类问题以及逻辑回归,同时也讲了一些其他概念:决策边界,过拟合,正则化等。
在接下来,我们将学习另一种监督学习或者说深度学习算法——神经网络(neural network)
从0了解机器学习:3——分类