从0了解机器学习:2——线性回归
本文章将介绍监督学习中的线性回归算法,以及一些其他有关概念
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
线性回归(Linear Regression)
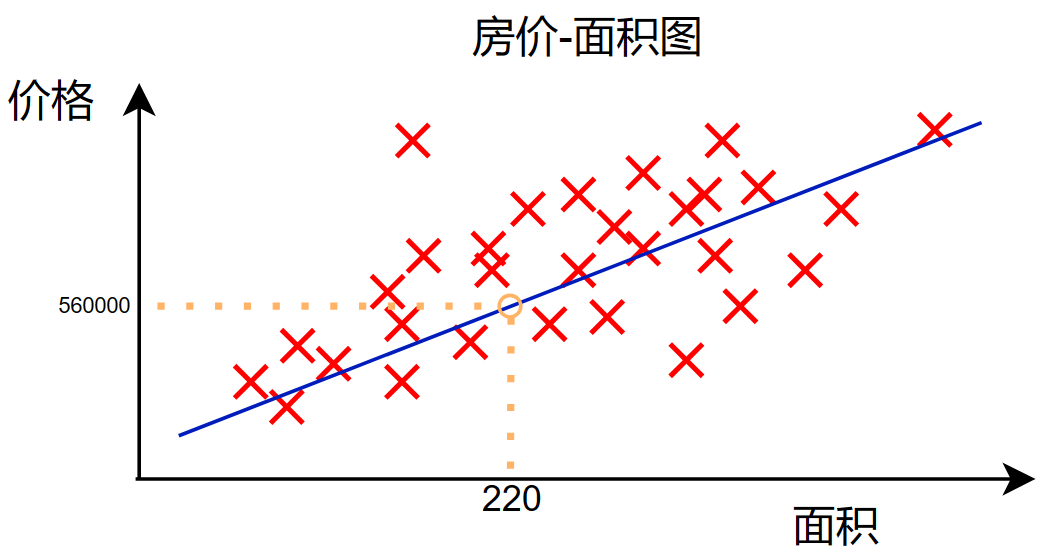
在上图中展示了线性回归模型,我们发现它有一些特点:
- 预测数字
- 数据都有标签“正确答案”
- 输出数据无限
而对比分类来说:
- 预测类型:
- 类别
- 离散类别
- 输出数据有限
在进行线性回归之前,我们一般得到了数据需要进行一些可视化,而对于线性回归或者说监督学习的数据来说,我们一般使用以下方式进行可视化:
- 数据表格
- 数据图
在了解算法过程时,我们也需要了解一些术语:
训练:使用数据去训练机器学习模型
数据:对于监督学习来说,一般都是输入x与标签y一一对应的数据,例如:
| \(x\):房屋面积(\(m^2\)) | \(y\):房屋价格(w) |
|---|---|
| (1)651 | 400 |
| (2)426 | 232 |
| (3)507 | 315 |
| (4)275 | 178 |
| ... | ... |
| (47)1065 | 870 |
x:输入变量/特征
y:输出变量/目标变量
m:训练数据的个数
(x,y):一对训练数据
\(x^{(1)}=651 \quad y^{(1)}=400\)
\((x^{(1)},y^{(1)})=(651,400)\)
\((x^{(i)},y^{(i)})\) 第 i 个训练数据
线性回归过程
在线性回归中,怎么代表 \(f\) 呢:
\[
f_{w,b}(x)=w\cdot x+b \quad \Leftrightarrow \quad f(x)=w\cdot x+b
\]  \[
f_{w,b}(x)=f(x)=w\cdot x+b\qquad 线性函数
\] 对于上述的 \(f_{w,b}(x)\)
只有一个特征 \(x\)
\[
f_{w,b}(x)=f(x)=w\cdot x+b\qquad 线性函数
\] 对于上述的 \(f_{w,b}(x)\)
只有一个特征 \(x\)
我们称其为:单变量线性回归
梯度下降(Gradient descent)
在之前的机器学习入门数学原理中,我们讲到了线性回归的目标函数:\(\frac{1}{2}\sum_{i=1}^n(f(x^{(i)})-y^{(i)})^2\)
在这里我们将其改进为: \[ J(w,b)=\frac{1}{2m}\sum_{i=1}^m(f_{w,b}(x)-y^{(i)})^2 \] Q:为什么在分母加了 m 呢?
A:原来的函数求的是所有数据的误差之和,在机器学习算法中,我们需要除以总的样本数,求取平均误差,有利于减少数据膨胀,导致目标函数为很高的值
这就是均方差函数(MSE)
我们要做的,就是使得这个函数最小,也就是让误差变小,这样就能用直线拟合数据了
梯度下降过程:
- 初始化 \(w,b\) (设置 \(w,b=0\) 或者其他随机的值)
- 修改 \(w,b\) 以降低 \(J(w,b)\) 的值
- 直到 \(J(w,b)\) 落在最小值或者最小值附近
但是,函数 \(J(w,b)\) 可能不仅仅有一个最小值,就像下图:
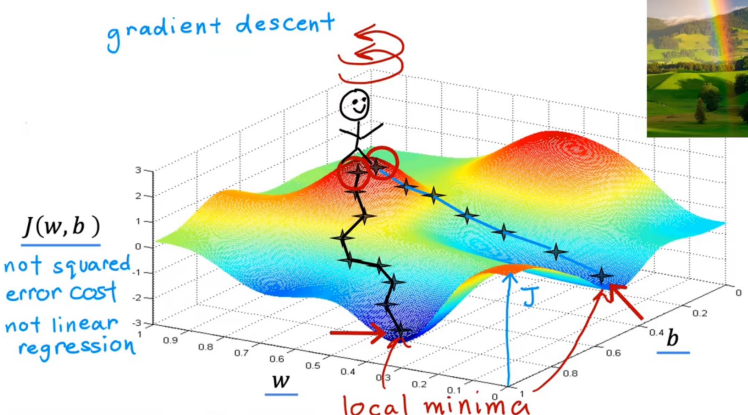
图中的函数图像不是均方差函数,也不是线性回归模型,图只是展示局部最小值(local minima)的情况
根据我们机器学习入门数学原理那篇文章,均方差函数只有一个最小值
梯度下降算法: \[ \begin{gather} w=w-lr\cdot\frac{\partial J(w,b)}{\partial w} \\ b=b-lr\cdot\frac{\partial J(w,b)}{\partial b} \\ lr\;为学习率 \end{gather} \] 在实际代码编写梯度下降算法时,要注意:
以下是错误的代码:
1 | tmp_w = w - lr * grad(w, b) // grad(w,b)这里代表对 J(w,b) 求对应的偏导 |
上述代码错在:
在还没有对 b 更新时,就将更新后的 w 赋值,导致在更新 b 时,对 b 求偏导时,函数 J(w, b) 中的 w 已经被更新过了,导致 w,b没有同步更新
正确的代码:
1 | tmp_w = w - lr * grad(w, b) // grad(w,b)这里代表对 J(w,b) 求对应的偏导 |
在对 w,b 求完偏导后再将他们一起更新
学习率(Learning rate)
如果设置学习率时,设置得太小,那么梯度下降的速度就会非常缓慢
当然,如果设置过大,那么在更新参数时,参数会“左右横跳”,导致无法到达最小值
以上我们在数学原理中讲过
当你在观察梯度下降的过程时,你会发现,当目标函数接近最小值的时候,梯度会越来越小,同样的,参数的更新速度也会越来越慢,这是由函数图像和参数更新公式决定的
批梯度下降(Batch gradient descent): 每一步梯度下降都将用到所有的训练数据
(与小批量梯度下降不同,小批量梯度下降只会使用一部分的数据)
多特征(Multiple features/variables)
之前的房价-面积数据,只有一个特征:面积
而现实中,使用机器学习时我们一般都会遇到多特征的数据,例如:
| 房屋面积:x1 | 卧室数量:x2 | 房屋层数:x3 | 房屋年龄:x4 | 房价(W):y |
|---|---|---|---|---|
| (1)651 | 5 | 1 | 45 | 460 |
| (2)426 | 3 | 2 | 40 | 232 |
| (3)507 | 3 | 2 | 30 | 315 |
| (4)275 | 2 | 1 | 36 | 178 |
| ... | ... | ... | ... | ... |
\(x_j\):第 j 个特征
n:特征的数量
\(\vec{x}^{(i)}\): 第 i 个数据的所有特征,例如: \(\vec{x}^{(2)}=[426,3,2,40]\)
\(x_j^{(i)}\):特征 j 的第 i 个数据,例如:\(x_3^{(2)}=2\)
对于目标函数:\(f_{w,b}(x)=wx+b\)
应用以上案例,我们有表达式: \[ f_{w,b}(x)=w_1x_1+w_2x_2+w_3x_3+w_4x_4+b \] 给参数初始化: \[ \begin{gather} f_{w,b}(x)=0.1x_1+4x_2+10x_3-2x_4+80 \\ \quad\quad\quad\quad\quad\quad\quad\quad\qquad\qquad\uparrow 面积\;\uparrow卧室数\uparrow层数\uparrow房龄\uparrow偏置(基本房价) \end{gather} \] 而对于n个特征来说,目标函数: \[ f_{w,b}(x)=w_1x_1+w_2x_2+w_3x_3+...+w_nx_n+b \] 我们可以使用向量来简化上述函数: \[ \begin{gather} f_{\vec{w},b}(\vec{x})=\vec{w}\cdot\vec{x}+b \\ \vec{w}=[w_1,w_2,w_3,...,w_n] \\ b为偏置 \\ \vec{x}=[x_1,x_2,x_3,...,x_n] \end{gather} \] 上述有多个特征/变量,称为:多元线性回归
向量化(Vectorization)
将数据向量化有助于减少计算量,同时也能使用GPU加速,因为GPU很擅长向量/矩阵计算
给一个例子: \[ \begin{gather} \vec{w}=[1.0,2.5,-3.3] \\ b=4 \\ \vec{x}=[10,20,30] \end{gather} \] 如果在python中该如何计算呢?
1 | f = w[0] * x[0] + w[1] * x[1] + w[2] * x[2] + b |
如果特征数量n=10000甚至更多呢,该怎么计算?
1 | f = 0 |
那向量化该怎么操作?
1 | import numpy as np |
向量化的操作,比之前的两种方法快得多得多
那么,为什么会那么快呢?
原因是向量化将所有的乘法操作一步完成,就像这样:
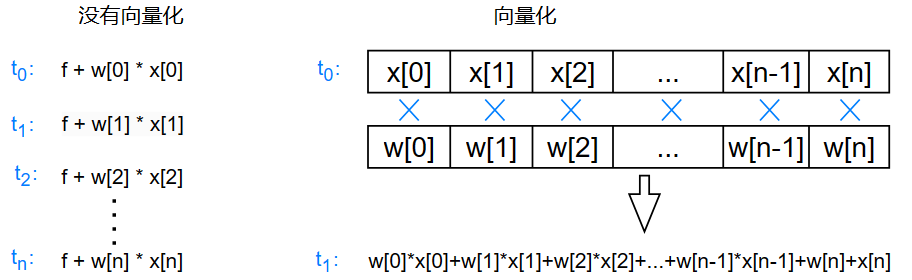
单特征梯度下降参数更新公式: \[ \begin{gather} w=w-lr\frac{1}{m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)})x^{(i)} \\ b=b-lr\frac{1}{m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)}) \\ 有时学习率为:lr、\alpha、\eta \end{gather} \] 多特征的参数更新公式: \[ \begin{gather} w_1=w_1-lr\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})x^{(i)} \\ . \\ . \\ . \\ w_n=w_n-lr\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})x^{(i)} \\ b=b-lr\frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}) \end{gather} \]
特征缩放(Scale the feature)
有时候,特征与特征之间的数值差距实在很大,这会导致某一特征主导了模型学习过程,并且梯度下降的速度也将变得缓慢且不稳定,我们需要将他们变为相似的尺度
给出一个例子: \[ \hat{price}=w_1x_1+w_2x_2+b\qquad\qquad x_1:房屋面积\quad x_2:楼层数量 \] 房屋面积很大:50~1000 而楼层数量一般较少:1~5
有一套房产:\(x_1=1000\quad x_2=3\quad price=300W元\)
如果:\(w_1=50\quad w_2=0.1\quad b=50\) \[ \begin{gather} \hat{price}=50\times1000+0.1\times3+50 \\ \hat{price}=50150.3W元 \end{gather} \] 与300W差距太大了,如果一开始初始化为这样,那么目标函数的值会非常大
如果:\(w_1=0.1\quad w_2=50\quad b=50\) \[ \begin{gather} \hat{price}=0.1\times1000+50\times3+50 \\ \hat{price}=300W元 \end{gather} \] 如果这是最终梯度下降结束后的参数值,那么 \(w_1\) 和 \(w_2\) 相差500倍!
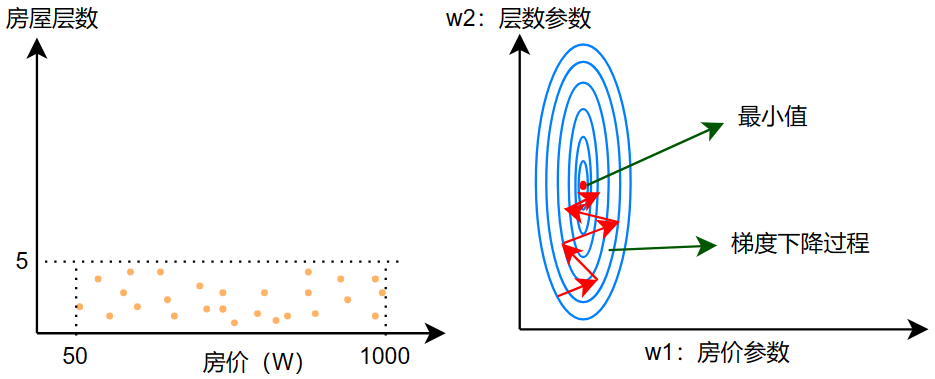
特征的大小在梯度下降中的表现:
没有进行特征缩放时,原始特征:
进行了特征缩放后:
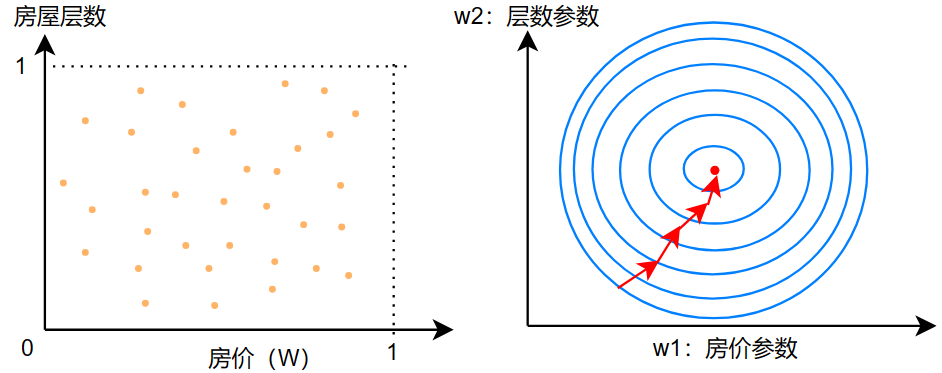
说了特征缩放的好处,那么该怎么缩放呢?
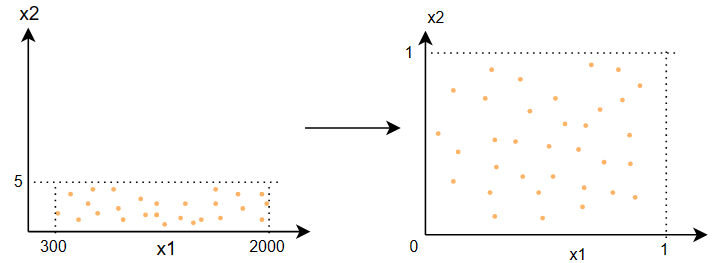
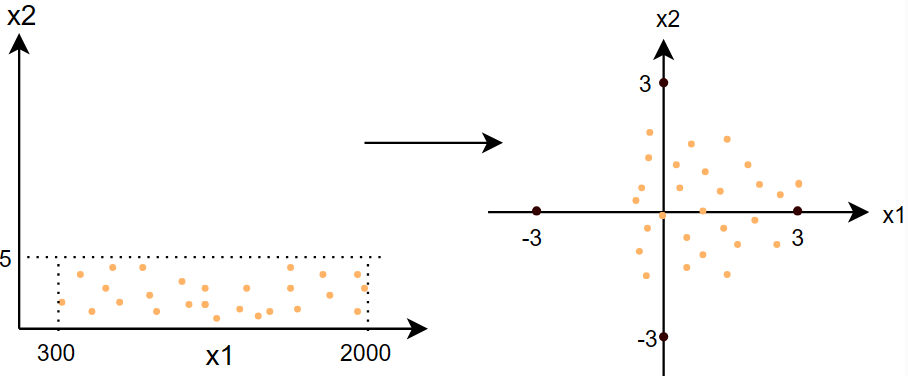
这里给出一个例子:\(\quad300\leq x_1\leq 2000\qquad 0\leq x_2\leq5\quad\) 下面几种方法都将使用这个例子
这里有几种方法:
- 方法一:除以各自的最大值
\[ \begin{gather} x_{1,scaled}=\frac{x_1}{x_{1max}}=\frac{x_1}{2000}\qquad\Rightarrow\qquad 0.15\leq x_{1,scaled}\leq1 \\ x_{2,scaled}=\frac{x_2}{x_{2max}}=\frac{x_2}{5}\qquad\Rightarrow\qquad 0\leq x_{2,scaled}\leq1 \end{gather} \]
- 方法二:均值归一化(标准化)
\[ \begin{gather} x_{1,scaled}=\frac{x_1-\mu_1}{max-min}=\frac{x_1}{2000-300}\qquad\Rightarrow\qquad -0.18\leq x_{1,scaled}\leq0.82 \\ x_{2,scaled}=\frac{x_2-\mu_2}{max-min}=\frac{x_2}{5-0}\qquad\Rightarrow\qquad -0.46\leq x_{2,scaled}\leq0.54 \\ \mu:\;均值 \end{gather} \]
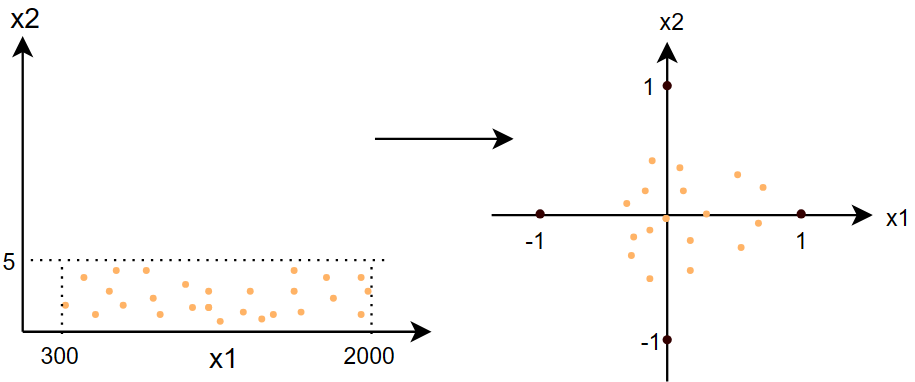
- 方法三:Z分数标准化(Z-score normalization)
\[ \begin{gather} x_{1,scaled}=\frac{x_1-\mu_1}{\sigma}\qquad\Rightarrow\qquad -0.67\leq x_{1,scaled}\leq3.1 \\ x_{2,scaled}=\frac{x_2-\mu_2}{\sigma}\qquad\Rightarrow\qquad -1.6\leq x_{2,scaled}\leq1.9 \\ \mu:\;均值 \\ \sigma:\;标准差 \end{gather} \]
我们什么时候需要使用特征缩放呢?
首先得了解,特征缩放需要的目标范围: \[ \begin{gather} -1\leq x\leq1 \\ -3\leq x\leq3 \\ -0.3\leq x\leq0.3 \end{gather} \] 以上的范围都是可以的
当然,下面这些范围也是可以接受的,不使用特征缩放也是没有任何危害: \[ \begin{gather} 0\leq x\leq3 \\ -2\leq x\leq0.5 \end{gather} \] 而下面这些范围就需要使用特征缩放了: \[ \begin{gather} -100\leq x\leq100\qquad太大了 \\ -0.001\leq x\leq0.001\qquad太小了 \\ -98.6\leq x\leq105\qquad太大了 \end{gather} \] 合适的特征缩放将会加快梯度下降的速度
判断收敛(Judge convergence)
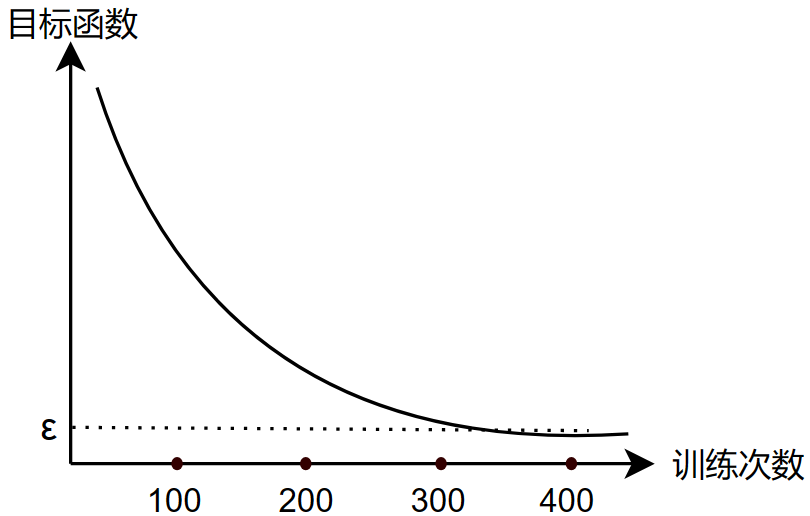
自动收敛:我们可以选择一个 \(\epsilon\) 值,执行训练时,当某一次训练使得目标函数小于 \(\epsilon\) 就判断收敛,停止训练,此时就找到了 \(\vec{w},b\) 接近于全局最小值
事实上,选择一个合适的 \(\epsilon\) 值是困难的,所以说我们一般都只是看上图,当目标函数每次下降很小时,就接近收敛了
当然,如果你的图像没有一直下降,甚至出现了上升,那么可能是你的学习率设置得太高了,或者你的代码出现了bug
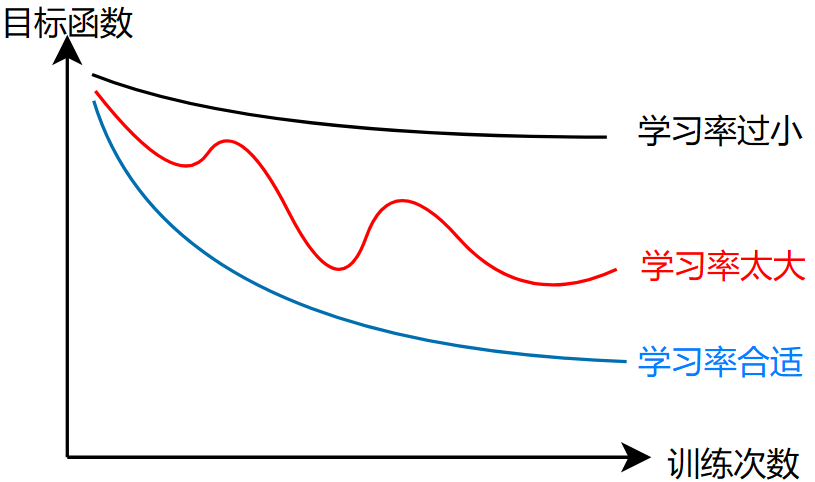
那么如何选择一个合适的学习率呢?
其实,我们可以在一开始选择一个很小的学习率去测试模型
如果目标函数-训练次数图,出现了一些情况:
- 下降:代码正确,可以进一步设置学习率
- 出现上升:代码可能有bug
一般可以尝试以下学习率:

每下一次学习率的设置,都是基于本次训练的图像都是正常的下降,才可以接着设置学习率
特征工程(Feature engineering)
通过直觉或者知识和经验,从现有的特征中发现能够影响结果的新特征,或者通过组合现有特征,来获取更能反映输出结果的新特征,甚至可以去掉一些对结果没有影响的特征,来获得一个更好的模型
举一个例子:
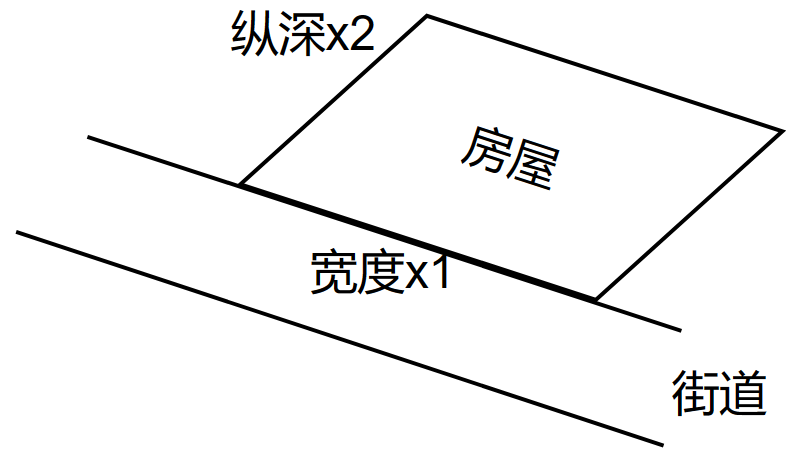
- \(x_1\):宽度
- \(x_2\):纵深
\[ f_{\vec{w},b}(\vec{x})=w_1x_1+w_2x_2+b \]
但是你会发现,仅仅靠宽度和纵深并不能很好的刻画其与价格的映射,因为如果该房屋恰好是“刀片房”,也就是纵深很小,但是宽度很宽,或者纵深很大,但是宽度很小,那么估计没人会买这个房子,并且它的价格也会很低(刚毕业的大学生可能会考虑...doge)
所以说,我们可以合并这两个特征,也就是将纵深和宽度相乘,组合成新的特征——面积,这样将会很好的适配 \[ \begin{gather} 面积=宽度\times 纵深 \\ x_3=x_1x_2 \\ f_{\vec{w},b}(\vec{x})=w_1x_1+w_2x_2+w_3x_3+b \end{gather} \]
多项式回归(Polynomial regression)
一些无法使用直线拟合的数据,可能需要曲线拟合,这就用到了多项式回归
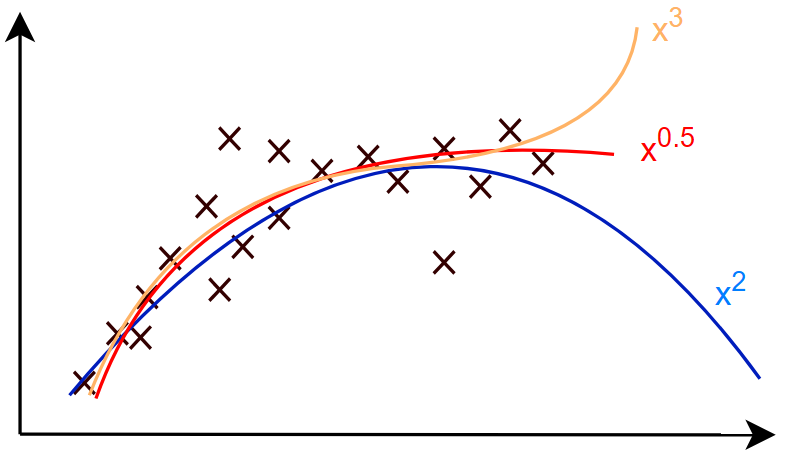
以下函数是一个多项式 \[ f_{\vec{w},b}(\vec{x})=w_1x_1+w_2x_2^2+w_3x_3^3+b \] 但是它有一个问题,高次的变量可能出现数值膨胀,例如: \[ \begin{gather} if:\quad1\leq x\leq1000 \\ \quad1\leq x_1\leq1000 \\ \quad1\leq x_2\leq1000000 \\ \quad1\leq x_3\leq1000000000 \end{gather} \] 所以说,在多项式回归里,特征缩放显得格外重要
总结
本文章讲了监督学习中的线性回归,同时也讲了一些其他概念:最重要的梯度下降,向量化的意义,特征缩放解决单一特征左右学习过程,收敛判断,特征工程等。
在接下来,我们将学习第二种监督学习——分类
从0了解机器学习:2——线性回归