从0了解机器学习:1——机器学习的基本分类
本文章是该系列的第一篇文章,我会从一个初学者的角度带你了解机器学习的一些基本概念
以下的内容以及该系列的内容基于本人在学习机器学习过程中的笔记和个人理解
(如果文章中的公式不能正常显示,请刷新该页面。如果还不能解决,请邮箱联系我,谢谢...)
机器学习的分类
机器学习分为两类:
- 监督学习(supervised learning)(用得最多)
- 无监督学习(unsupervised learning)
监督学习
监督学习,就是训练时使用的数据含有标签,也就是每一个输入对应的“正确答案”
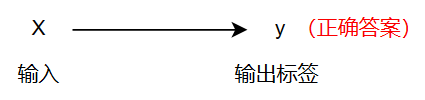
一些实例:
| 输入x | 输出y | 应用 |
|---|---|---|
| 邮件 | 是否为垃圾邮件(0/1)? | 垃圾邮件过滤器 |
| 音频 | 文本 | 语音识别 |
| 英文 | 中文 | 翻译器 |
| 广告,用户信息 | 是否点击(0/1)? | 在线广告 |
| 图像,雷达信息等 | 其他车辆的位置 | 自动驾驶车辆 |
| 手机的图片 | 是否损坏(0/1)? | 视觉检查 |
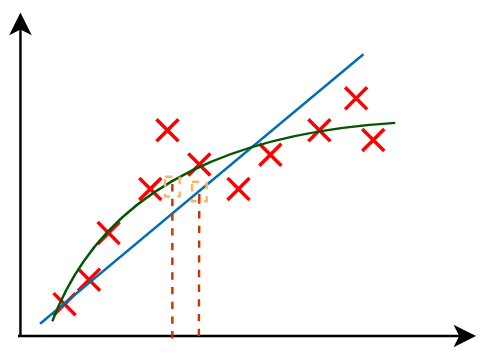
监督学习的一种主要类型是:回归(Regression algorithms)
- 预测一个数字
- 有无限多种输出
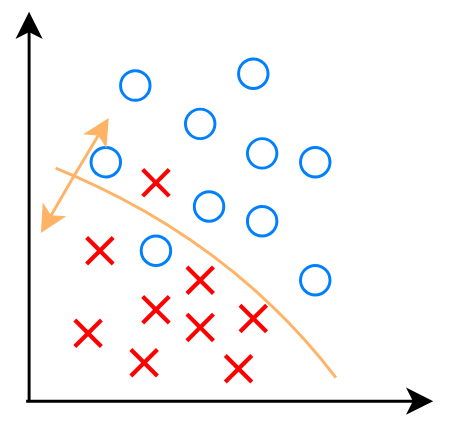
另一种主要类型是:分类(Classification algorithms)
预测类型(猫/狗)
输出的数量少(种类数量)

无监督学习
监督学习:从带正确答案标签的数据中学习
无监督学习:从不带标签的数据中找到一些有趣的发现/特征
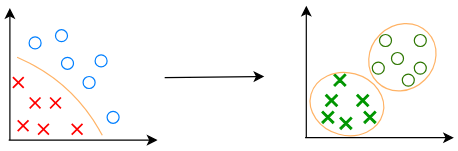
(上图中从红蓝变成只有绿色,表示从有标签变成无标签)
无监督学习的一种主要类型是:聚类(clustering)
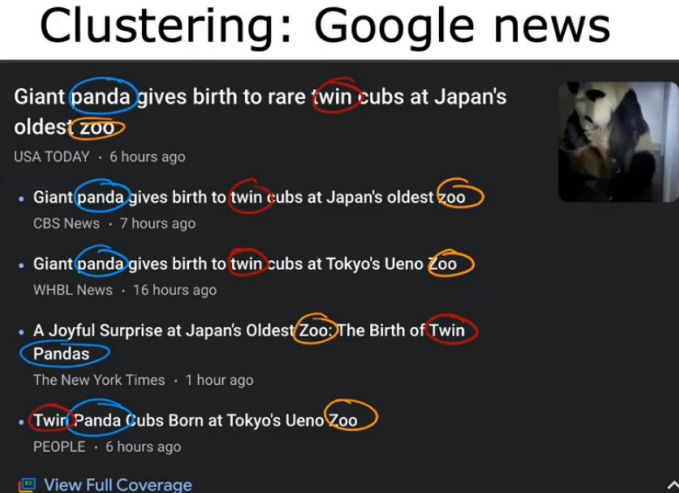
谷歌新闻里,这一页面中的所有新闻都是关于熊猫的
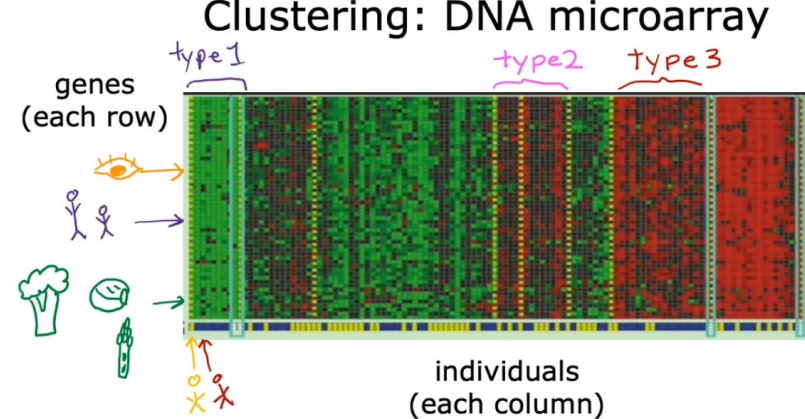
基因分析,分析出哪些人在基因片段上的不同,造就了一些人体特征上的不同
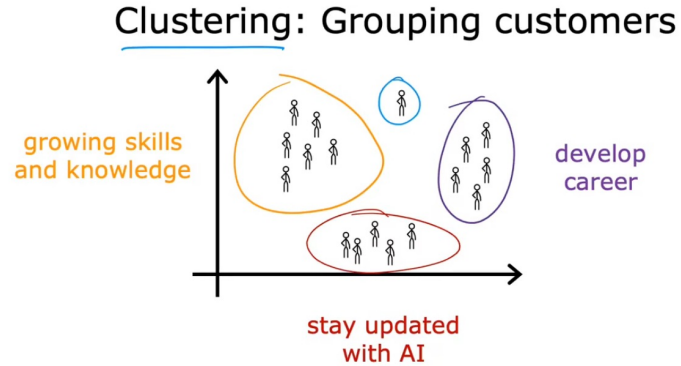
客户聚类,通过一些客户特征将客户分为几类
有人可能会问,把客户分为几类,难道不是分类问题吗,不应该是监督学习吗?
我们区分监督学习和无监督学习的关键是,训练的数据有没有标签:
对于客户分类,我们在训练时并没有给一个个客户打上标签,因为我们从客户的行为数据上难以快速区分是属于哪一种客户,所以说我们需要让机器学习这些客户的特征,来捕获一些有趣的区别,从而将客户分为几类
并且我们分出的类别本身也不带标签,机器只知道,这些客户应该为一类,但不知道这一类代表什么意思,最后的分类还是需要手动进行。
一些无监督学习类别:
- 聚类(Clustering):把一些相似的数据分在一起
- 异常检测(Anomaly detection):找到不同寻常的数据
- 降维(Dimensionality reduction):使用更少的数据/特征将数据压缩
后话
这里简单介绍了机器学习的一些基本分类,之后将会介绍相关的机器学习算法
之后的文章将介绍这两种大类别中的一共8种算法/类别:
- 线性回归(Linear Regression)
- 分类(Classification)
- 神经网络(Neural Networks)
- 决策树(Decision Trees)
- 聚类(Clustering)
- 异常检查(Anomaly Detection)
- 推荐系统(Recommender System)
- 主成分分析(PCA)(简要介绍)
- 强化学习(Reinforcement Learning)
持续更新中,敬请期待...
从0了解机器学习:1——机器学习的基本分类